

Compreender a marcação semântica: Noções básicas e impacto no SEO
Olá a todos! Neste artigo, vamos falar sobre a marcação semântica e porque é que é importante para o seu website se planeia envolver-se na otimização para motores de busca.

Vamos começar com esta captura de ecrã de um tópico do Reddit:
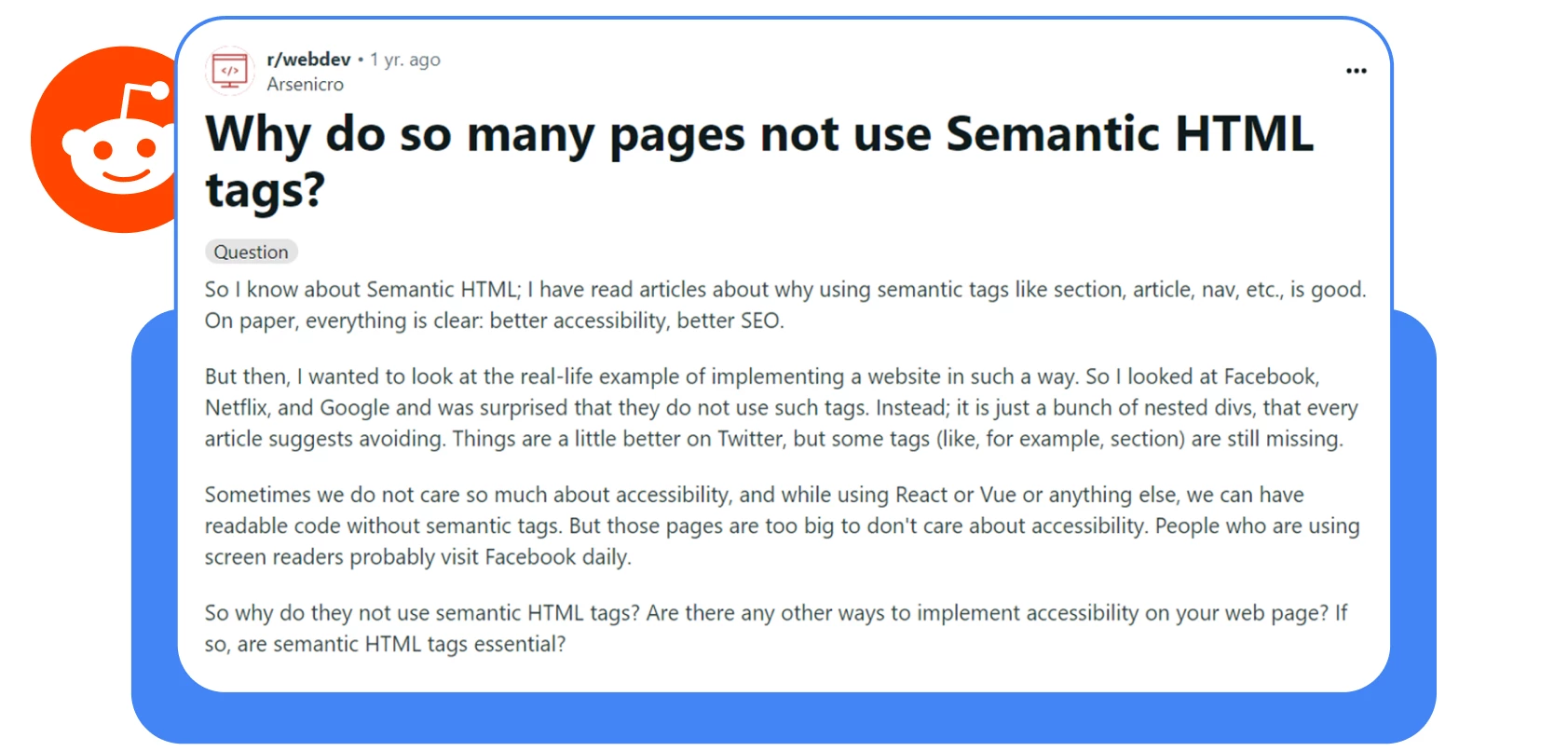
Ultimamente, é possível encontrar muitos sítios Web cujos criadores simplesmente não utilizam etiquetas HTML semânticas. Alguns pensam que o seu sítio já é amigo do SEO. Outros simplesmente não se querem dar ao trabalho. E alguns ainda usam <div id=”nav”> enquanto a documentação do HTML5 recomenda fazer isso: <nav>.
Mas esse não é o ponto agora. Muitos programadores tradicionalmente usam construções como
<div id=”nav”> para denotar navegação ou outros elementos estruturais de uma página. Portanto, antes de
de chegarmos ao problema e à sua solução, vamos ver o básico.
O que é marcação semântica?
O HTML semântico, também conhecido como marcação semântica, envolve a utilização de etiquetas HTML que transmitem o significado do seu próprio conteúdo, como títulos, navegação, secções de páginas, listas e parágrafos.
Para maior clareza, eis uma comparação de um sítio Web com marcação semântica e sem marcação semântica.
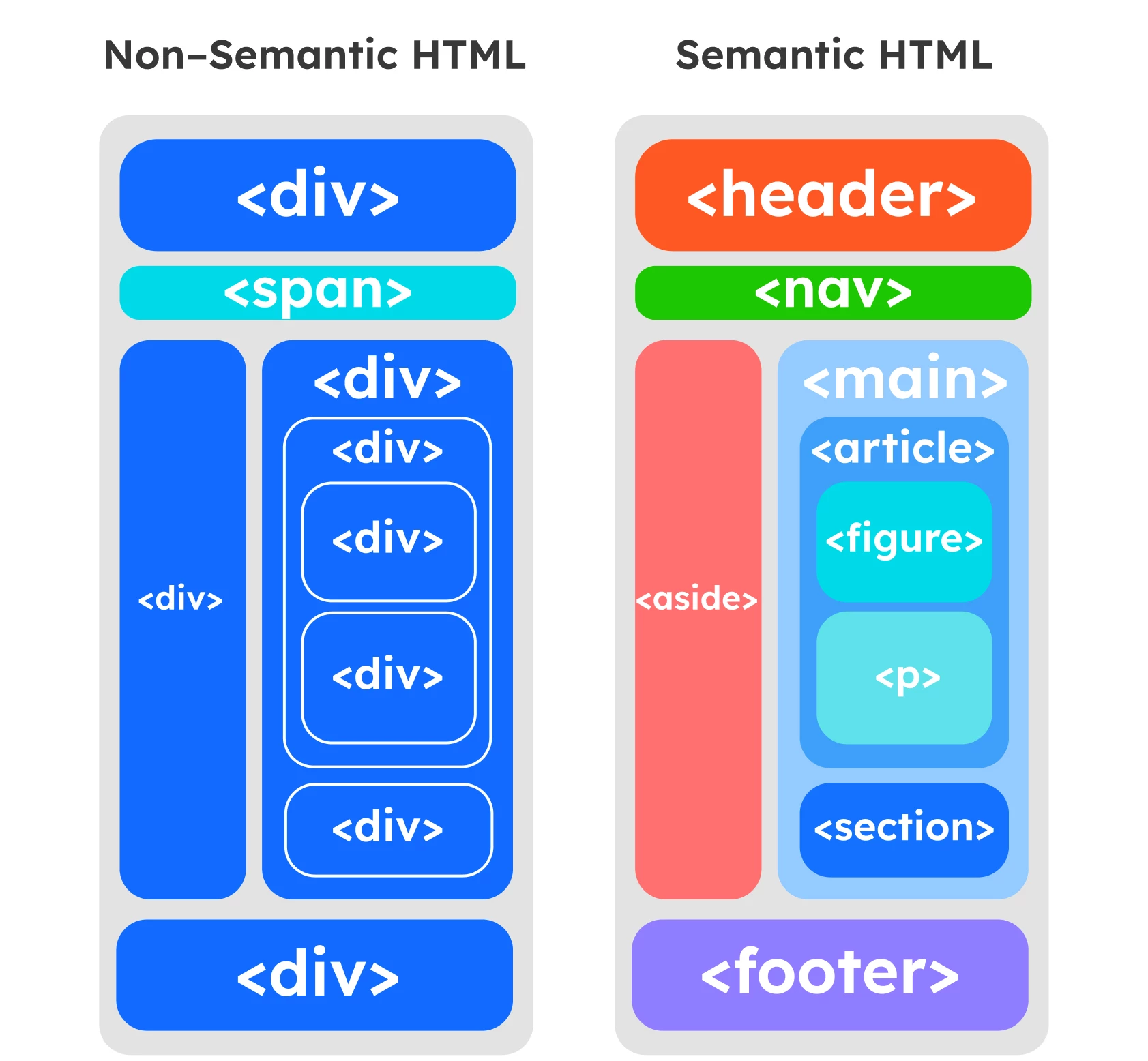
Em geral, este tipo de marcação tem duas funções principais:
A primeira é simplificar a vida dos robots de pesquisa.
O que é que isto significa? Quando um robô de pesquisa vê as etiquetas HTML semânticas, compreende exatamente qual a responsabilidade do conteúdo da etiqueta. Por conseguinte, entre dois sítios Web do mesmo tema, será dada preferência nos resultados da pesquisa ao sítio com marcação semântica (claro, desde que os outros parâmetros estejam aproximadamente ao mesmo nível).
A segunda é aumentar a acessibilidade do seu sítio Web.
Se pensa que as pessoas com deficiências visuais não utilizam a Internet, está enganado, apenas o fazem de forma diferente. Utilizam programas especiais chamados leitores de ecrã, que “lêem” e vocalizam o conteúdo da página. Quanto melhor o site estiver semanticamente marcado em termos de HTML, melhor (mais claro) será vocalizado para o utilizador.
Aqui está um vídeo visual que demonstra como funciona um leitor de ecrã:
“Como um utilizador de leitor de ecrã experimenta um Web site acessível e inacessível”.
O mesmo acontece com os robots de pesquisa quando indexam as suas páginas se não utilizar as etiquetas HTML necessárias. Eis outro exemplo do sítio web.dev (um sítio do Google para ajudar os programadores). Primeiro, dê uma olhada neste pedaço de código que usa apenas
as etiquetas <div> e <span>.
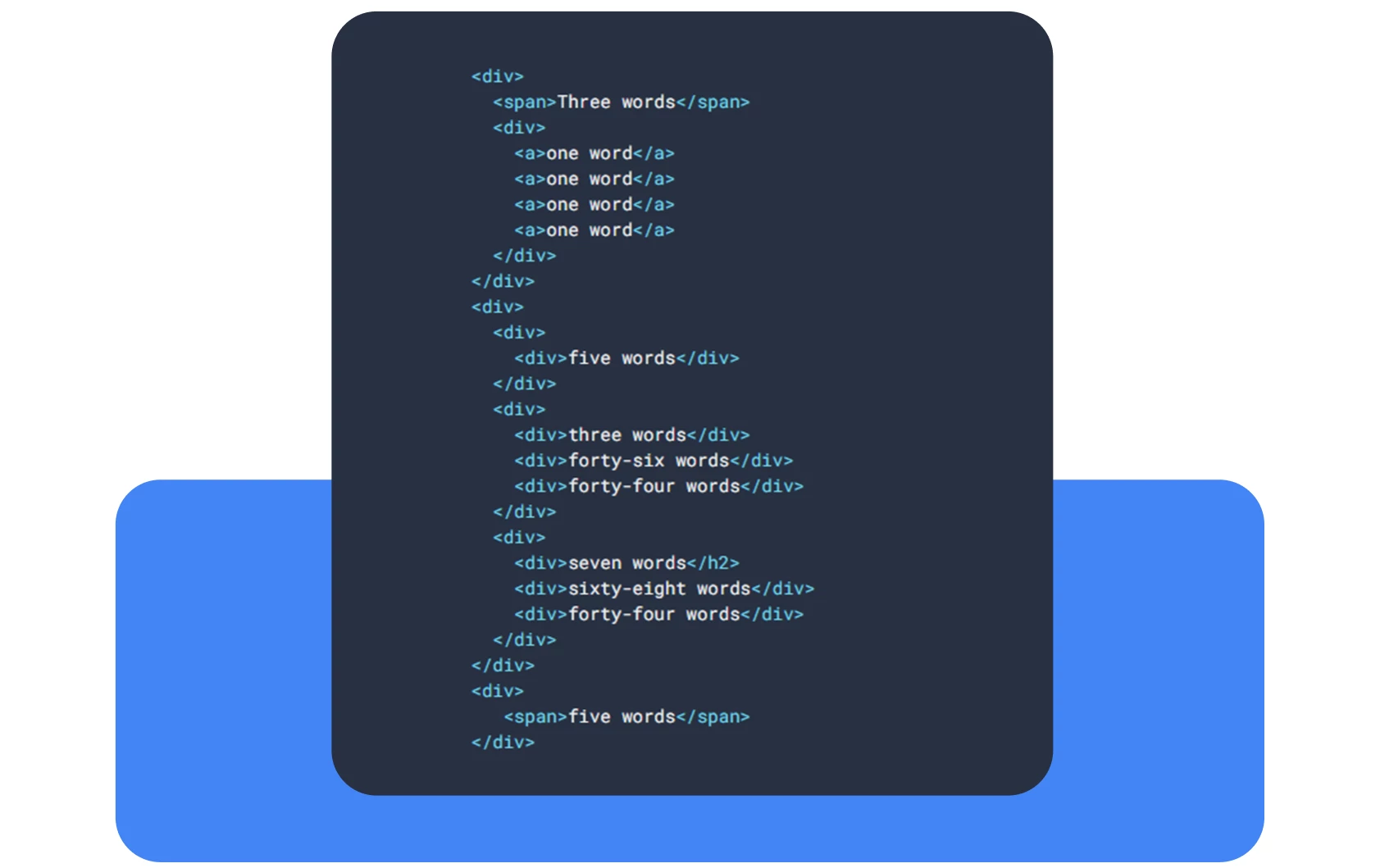
Agora, dê uma olhadela ao segundo pedaço de código, mas desta vez com etiquetas semânticas.

Naturalmente, no segundo cenário, é possível compreender a arquitetura do sítio Web, mesmo que não se conheça a linguagem utilizada no sítio. Eis um exemplo ainda mais interessante. Os browsers e os motores de busca utilizam modelos para “ler” o conteúdo do sítio. O conteúdo principal através do DOM (Document Object Model) e as folhas de estilo através do CSSOM (CSS Object Model).
E os programas de acessibilidade, como os leitores de ecrã, utilizam o Modelo de Objeto de Acessibilidade (AOM).
E é assim que se parece na prática:

No primeiro caso, sem marcação semântica, parece apenas um conjunto de texto estático. Além disso, se o sítio não tiver tido o cuidado de estruturar o texto e de o tornar legível para as pessoas, há muito poucas hipóteses para o motor de busca ou o leitor de ecrã.
O HTML semântico tem várias vantagens:
✅ A marcação semântica facilita a criação de design adaptativo.
A marcação semântica facilita a implementação de microdados Schema.org.
O código limpo e optimizado, típico da marcação semântica, contribui para um carregamento mais rápido da página. Como sabemos de artigos anteriores, isso é sempre bom.
E a cereja no topo do bolo, que é a razão pela qual este artigo foi escrito:
✅ O Google usa tags semânticas para determinar a relevância do conteúdo da página, o que pode impactar positivamente a classificação da página nas SERPs.
Elementos HTML semânticos
Vamos discutir tags semânticas importantes, exemplos básicos de seu uso e erros comuns. Elas podem ser divididas em dois tipos:
● Primeiro, aquelas que definem a estrutura da página.
Segundo, as que definem a marcação de texto na página.
Primeiro, marcamos o conteúdo em blocos lógicos e, em seguida, marcamos o texto dentro desses blocos.
Etiquetas HTML semânticas estruturais
● <header> – define o conteúdo que deve ser considerado como informação introdutória da página ou de uma secção.
● <nav> – utilizado para ligações de navegação. Pode ser colocada dentro da etiqueta <header>, mas as etiquetas <nav> secundárias para navegação também são frequentemente utilizadas noutras partes da página, como na barra lateral.
● <main> – contém o conteúdo principal (também chamado de corpo) da página. Deve haver apenas uma tag <main> por página.
● <article> – uma unidade independente e autónoma de conteúdo, por exemplo, um comentário, tweet, artigo, post, etc.
●<secção>– uma forma de agrupar conteúdos estreitamente relacionados com base num tema semelhante.
● <aside> – define conteúdo menos importante. É frequentemente utilizado para barras laterais.
● <footer> – usado na parte inferior da página. Inclui normalmente informações de contacto, direitos de autor e alguma navegação no sítio.
Erros comuns e recomendações.
Aqui vamos reforçar o material para cada tag, cuja ausência simplificará muito a sua vida no futuro.
◼️ <header>.
É preferível ter um título dentro, embora muitas vezes seja permitida a confusão com o uso das tags <section> e <div>.<main>.
É importante que a tag esteja presente numa única instância na página, com base na sua definição, e um erro comum é que ela pode conter elementos não únicos, que se repetem em outras páginas – como navegação, direitos autorais e afins.
◼️ <nav>
Utilizado para a navegação principal, não para todos os grupos de hiperligações possíveis. No entanto, o facto de considerar a navegação como principal ou não fica ao critério do programador. Por exemplo, se tiver um menu no rodapé do sítio, não é necessário envolvê-lo em <nav>. O rodapé geralmente contém uma breve lista de links, como um link para a página inicial, copyright e termos.
A interligação deste formato não é considerada navegação principal. Para esse tipo de informação, do ponto de vista semântico, a tag <footer> é a mais indicada.
Quanto aos erros comuns, muitos acreditam erroneamente que apenas uma lista de links de navegação é permitida dentro da tag <nav>, mas de acordo com a especificação, ela pode conter navegação em qualquer formato.
◼️ <main>
É importante que a etiqueta esteja presente numa única instância na página, com base na sua definição. Um erro comum é incluir nela elementos não exclusivos, como navegação e direitos autorais, que se repetem em outras páginas.
◼️ <article>
Preferencialmente, esta tag deve conter um título, e um erro comum é confundi-la com as tags <section> e <div>.
◼️ <section>
Uma secção semântica do documento (página), distinta, ao contrário de <article>. É preferível que, tal como o <artigo>, contenha um título. Um erro comum é confundi-lo com as tags <article> e <div>.
◼️ <aside>
Esta etiqueta pode ter o seu próprio título e pode aparecer várias vezes numa página. No entanto, muitas vezes é erradamente considerada apenas como uma etiqueta para a barra lateral e é utilizada para marcar o conteúdo principal que está relacionado com os elementos circundantes.
◼️ <footer>
Este elemento pode aparecer várias vezes numa página e não é necessário que a etiqueta esteja no fim da secção. No entanto, um erro comum é utilizá-lo exclusivamente como rodapé do sítio Web.
Já que começámos a falar de erros, eis uma comparação da estrutura das duas etiquetas <nav>e <body> utilizando exemplos simples com marcação semântica e sem marcação semântica.
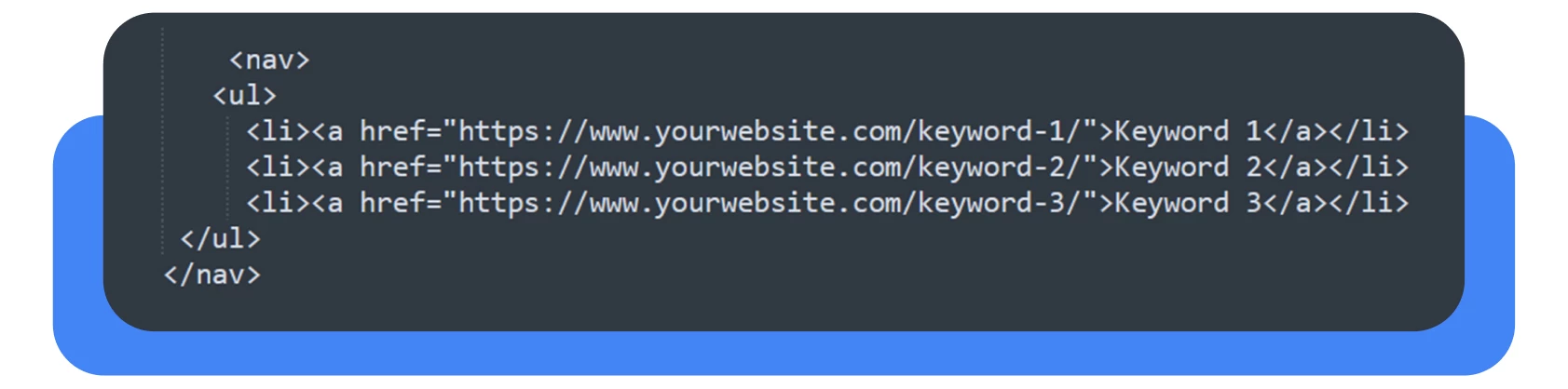
Com esta estrutura de código, o código é bastante limpo e legível. Cada ponto da nossa lista contém as palavras-chave necessárias.
Agora, aqui está um exemplo de como não marcar a navegação num sítio Web:
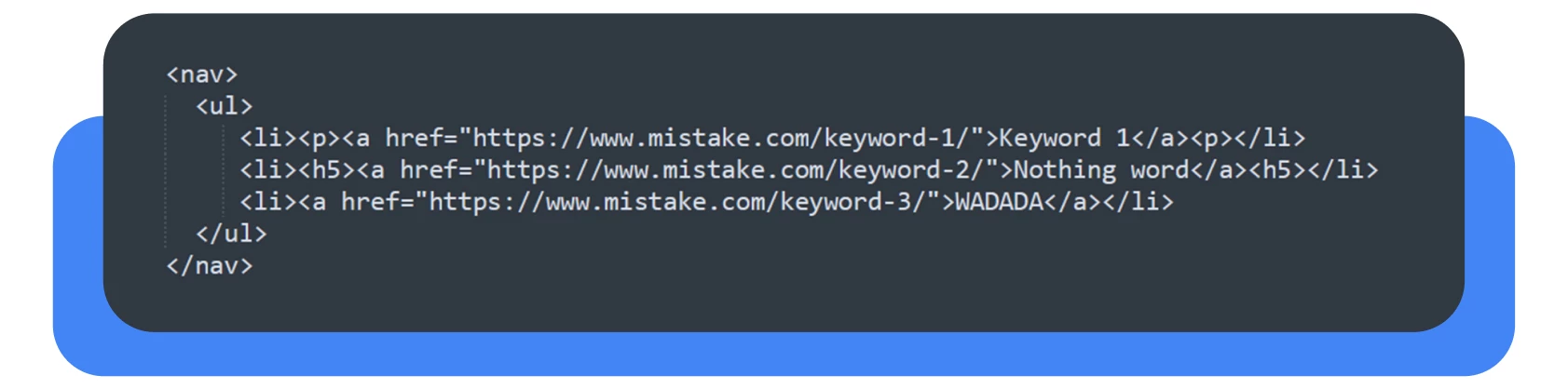
Dentro da lista, as etiquetas de cabeçalho (h1, h2, h3) ou <p>(parágrafo) são frequentemente utilizadas dentro da etiqueta <nav>. Ambas as etiquetas pertencem ao interior da etiqueta <body> para marcar o conteúdo principal.
*Informações adicionais:
Usar palavras-chave dentro de nomes de itens de menu é uma prática de SEO muito boa que é frequentemente ignorada. Sempre que possível, use-a apenas para as palavras-chave mais importantes.
O “corpo” do sítio
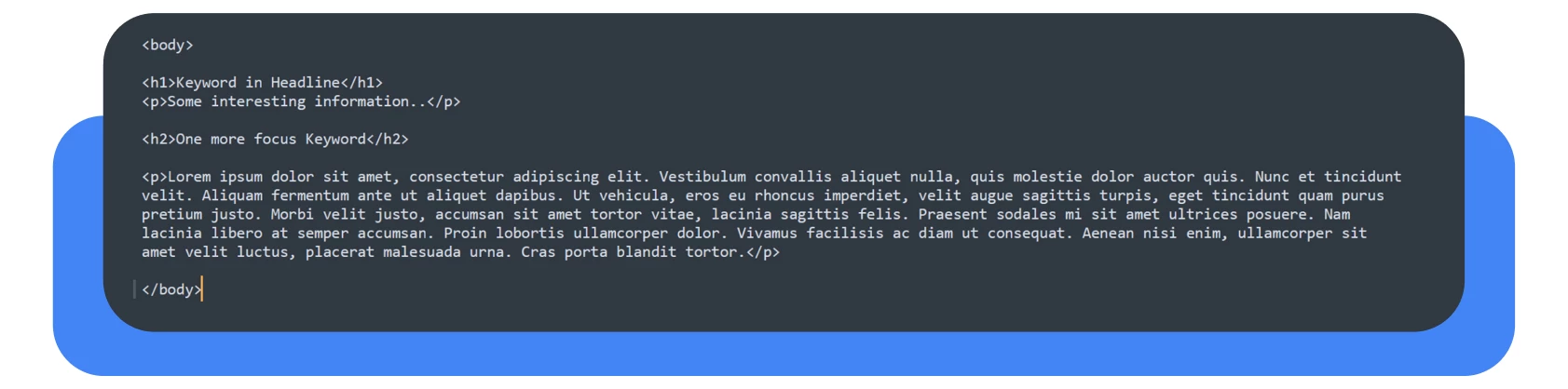
Mais uma vez, código limpo e legível. A tag contém conteúdo com palavras-chave. Idealmente, a tag deve “encapsular” todos os elementos semânticos relacionados com o conteúdo.
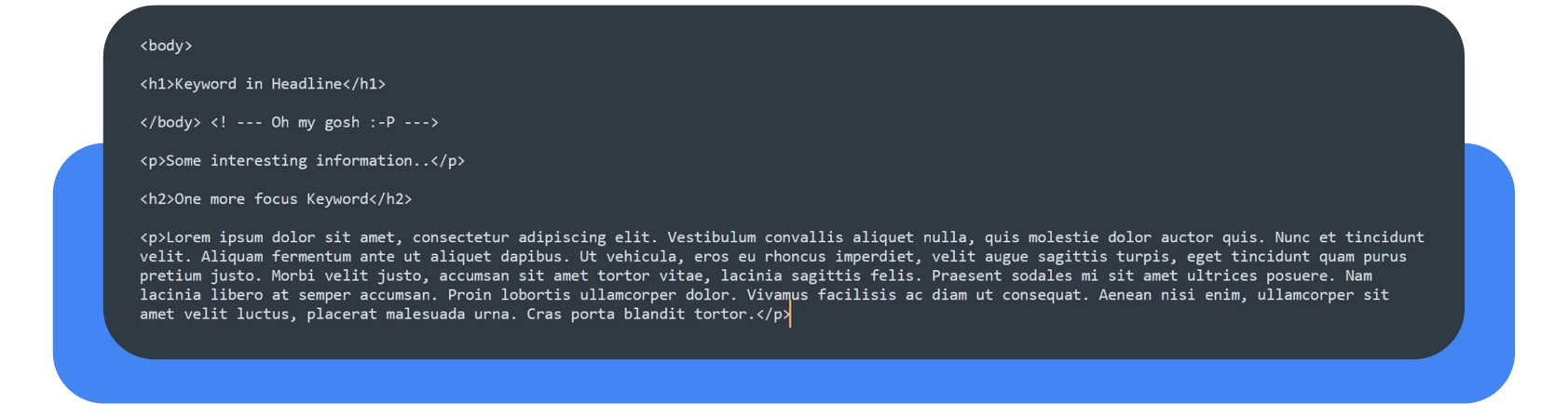
Infelizmente, estes problemas ocorrem com mais frequência do que se possa imaginar. Tente prestar atenção a estes erros, especialmente quando o conteúdo da página se estende para além da etiqueta </body>, sobretudo se estiver a trabalhar com construtores de páginas como o Elementor ou o Bakery.
Tags HTML semânticas para texto
● <h1> (cabeçalho)
A etiqueta H1 indica um título de nível superior. Normalmente, existe apenas um título H1 numa página.
● <h2> a <h6> (subtítulos)
Subtítulos de diferentes níveis de importância. Podem existir vários títulos do mesmo nível numa página.
● <p> (parágrafo)
Um parágrafo separado de texto.
● <a> (âncora)
Utilizado para criar hiperligações de uma página para outra.
● <ol> (lista ordenada)
Uma lista de itens apresentados numa sequência específica, começando com marcadores. A etiqueta <li> (item de lista) contém um único item de lista.
● <ul> (lista não ordenada)
Uma lista de itens que não seguem necessariamente uma sequência específica, começando com marcadores. A etiqueta <li> (item de lista) contém um único item de lista.
● <q> (citação em bloco)
Citação de texto. Use <blockquote> para citações longas e de várias linhas e <q> para citações curtas em linha.
● <em> (ênfase)
Usado para texto que precisa ser enfatizado.
● <strong>(ênfase forte)
Usado para texto que precisa de ser particularmente enfatizado.
● <code>
Bloco de código de computador.
Não utilize etiquetas HTML semânticas para estilizar. Apesar do facto de, ao utilizar estas etiquetas, os estilos serem automaticamente aplicados no browser (por exemplo, o texto dentro da etiqueta <a> é normalmente azul e sublinhado), isto não significa que as etiquetas HTML semânticas se destinem à formatação de texto.
Seguem-se alguns exemplos típicos de utilização incorrecta de etiquetas semânticas:
1. Usar as etiquetas <h1> a <h6> para texto que não é um título, simplesmente para alterar o tamanho da fonte.
2. Usar mais de uma tag <h1> numa página. A regra é simples: uma página, um <h1>.
3. Usar <blockquote> apenas para alinhar texto que não é uma citação.
4. Usar <strong> ou <em> apenas para adicionar formatação em negrito ou itálico a texto que não precisa de ênfase.
Para estilizar, use sempre folhas de estilo – CSS.
A propósito, é melhor não usar certos elementos semânticos em <nav> e <footer>. Especialmente tags de cabeçalho, por exemplo, <h2> – este é um poderoso elemento HTML para SEO, e se for encontrado no rodapé ou na navegação, o rastreador do motor de busca ficará confuso.
Vamos considerar um exemplo simples:
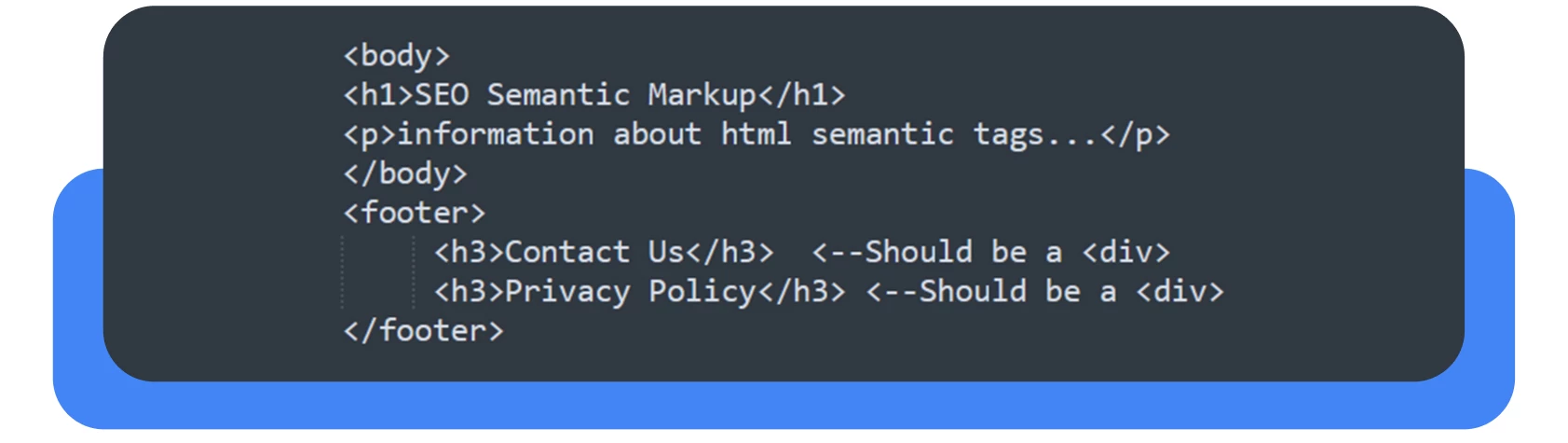
Ele vê um elemento <h1>, assumindo que a página está optimizada para motores de busca, e depois vê uma série de etiquetas H3 em ligações de rodapé. Se as etiquetas de cabeçalho acabarem onde não têm qualquer relação com o conteúdo que está a tentar promover através de SEO, então está a desperdiçar recursos.
O objetivo final ao trabalhar com marcação semântica é tomar decisões significativas, reduzir a confusão e, consequentemente, melhorar os resultados da pesquisa.
Como verificar as marcas semânticas numa página
Neste artigo, vamos considerar três opções, em complexidade crescente. No entanto, podem existir muitas mais opções, dependendo das ferramentas que estiver a utilizar.
O primeiro método consiste em visualizar o código da página.
É muito simples. Aceda à página de que necessita. Para dar um exemplo, vamos utilizar o Google.com.
E agora, vamos mover o cursor para um espaço vazio sem elementos e clicar com o botão direito do rato, depois selecionar “Ver fonte da página” ou utilizar o atalho Ctrl + U. E voilà:
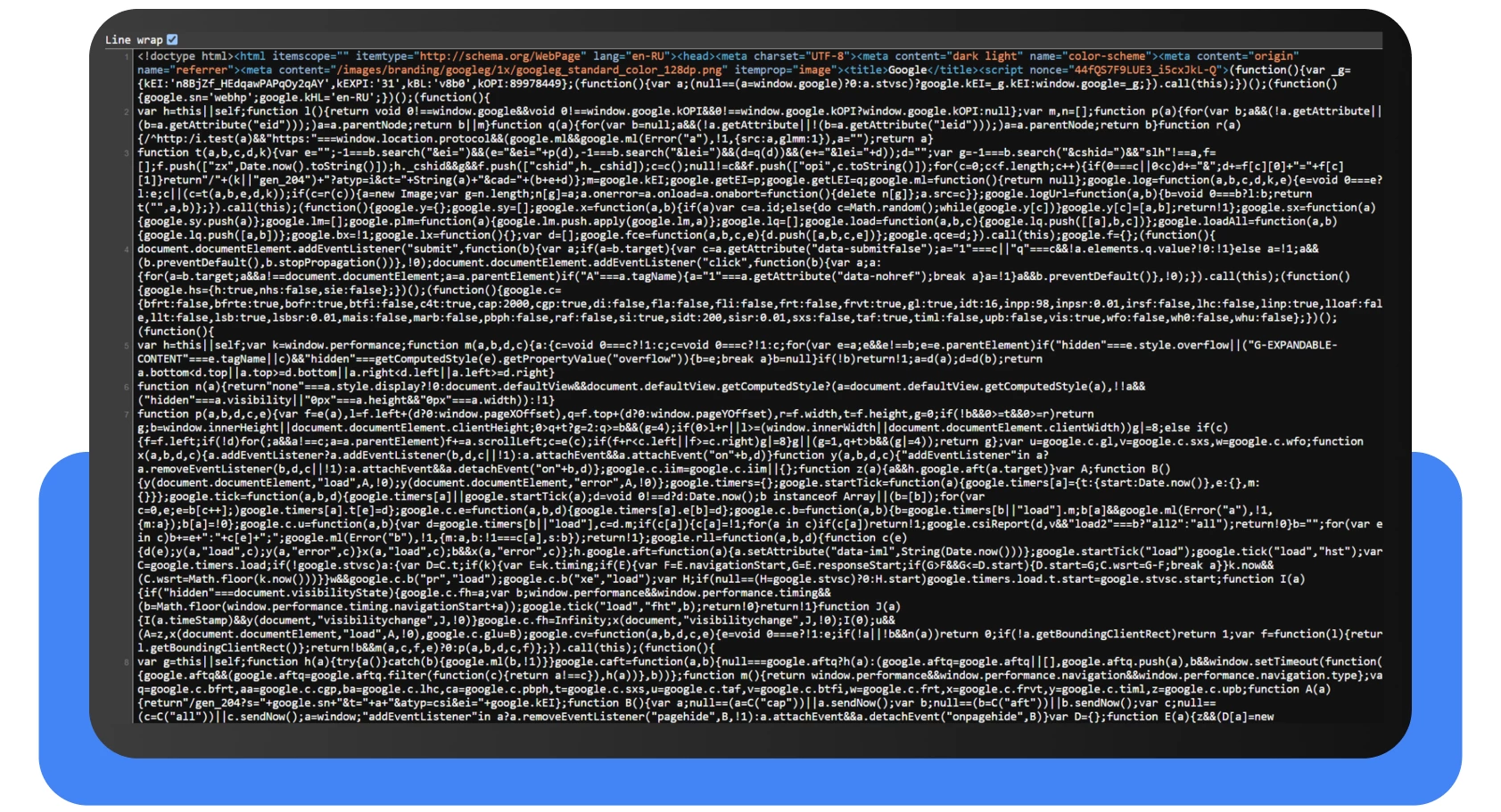
Tem o código HTML completo da página de que precisa. Estude-o e verifique se as etiquetas necessárias estão correctas. É mais fácil encontrá-las utilizando Ctrl + F (procurar na página).
O segundo método é a Chrome Dev Tool
Em geral, é muito semelhante ao primeiro método, mas existem algumas diferenças. Para começar, é a mesma coisa. Vá para a página de que precisa, mova o cursor para um espaço vazio sem elementos, clique com o botão direito do rato, mas desta vez escolha “Inspecionar” ou utilize o atalho F12.
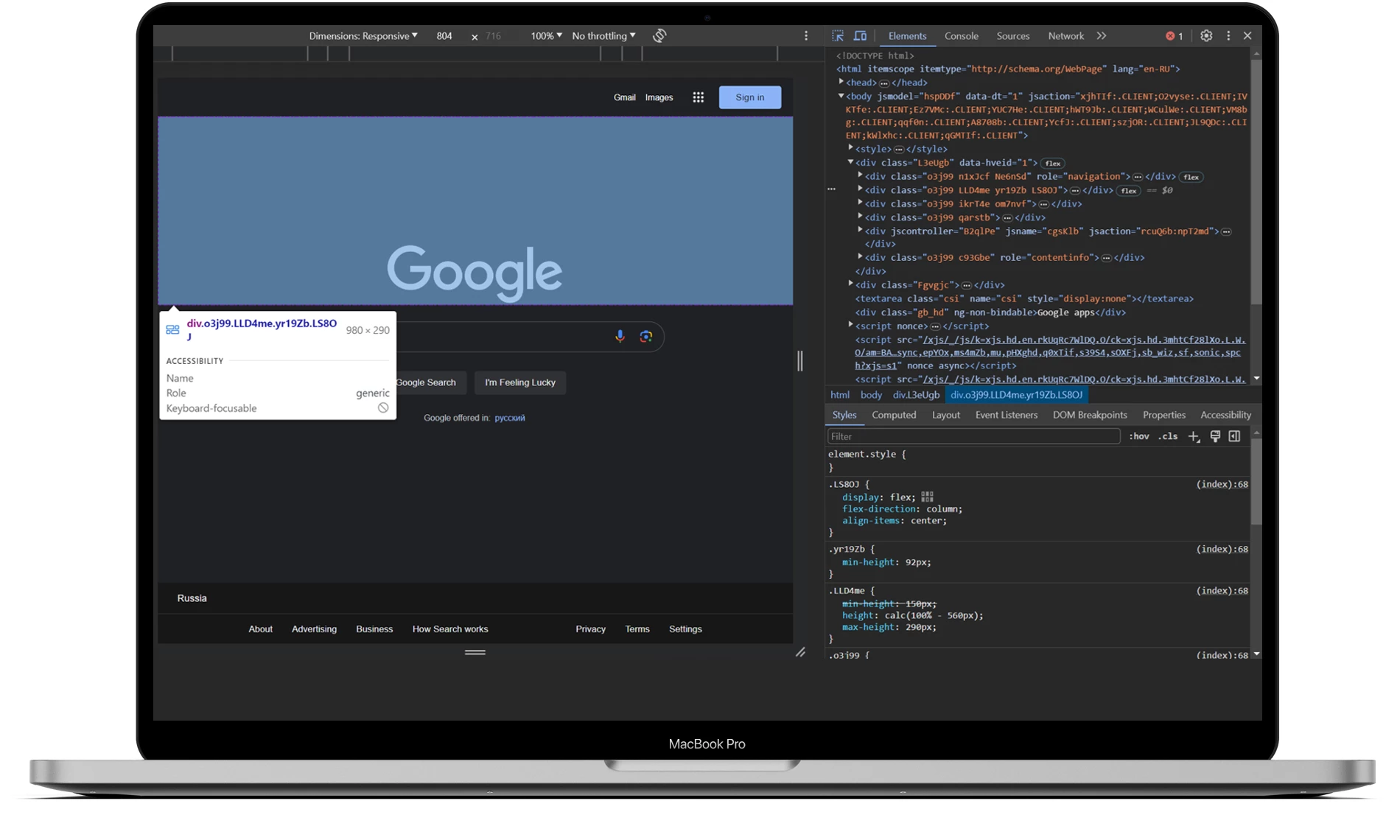
Seleccione “Elementos” no menu superior e prima Ctrl + Shift + C para entrar no modo de cursor. Agora, mova o cursor sobre qualquer elemento da página e o código será automaticamente destacado na parte direita do ecrã.
O terceiro método é a análise no Semrush
Este é o método mais complexo. Se não trabalha regularmente em SEO, é pouco provável que adquira uma subscrição paga. No entanto, na Semrush, pode utilizar uma avaliação gratuita. A ferramenta simplifica significativamente a pesquisa de erros.
Precisamos da ferramenta Auditoria do site. Crie um projeto e introduza o URL do seu site.
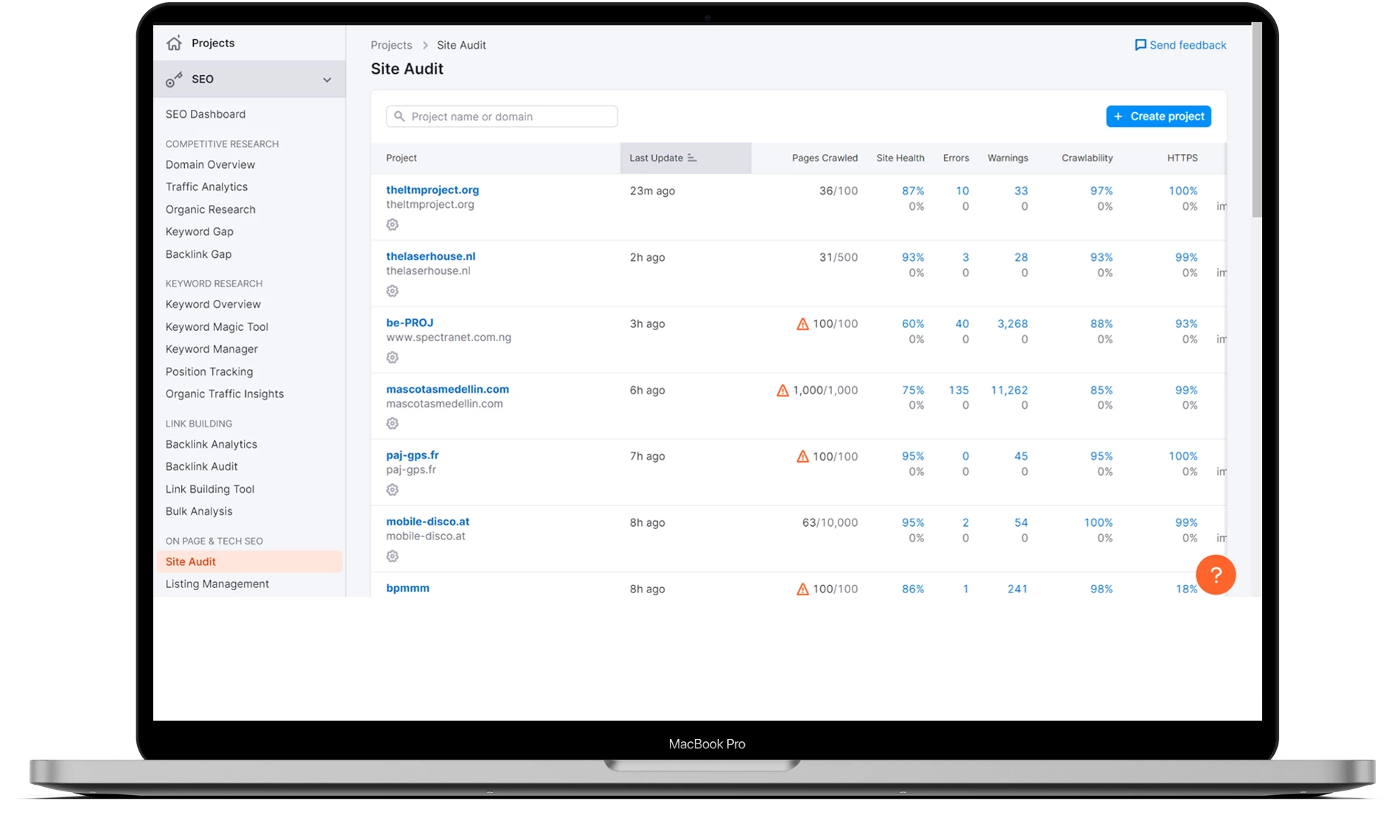
Agora, escolha o número de páginas que o serviço examinará como parte da auditoria.
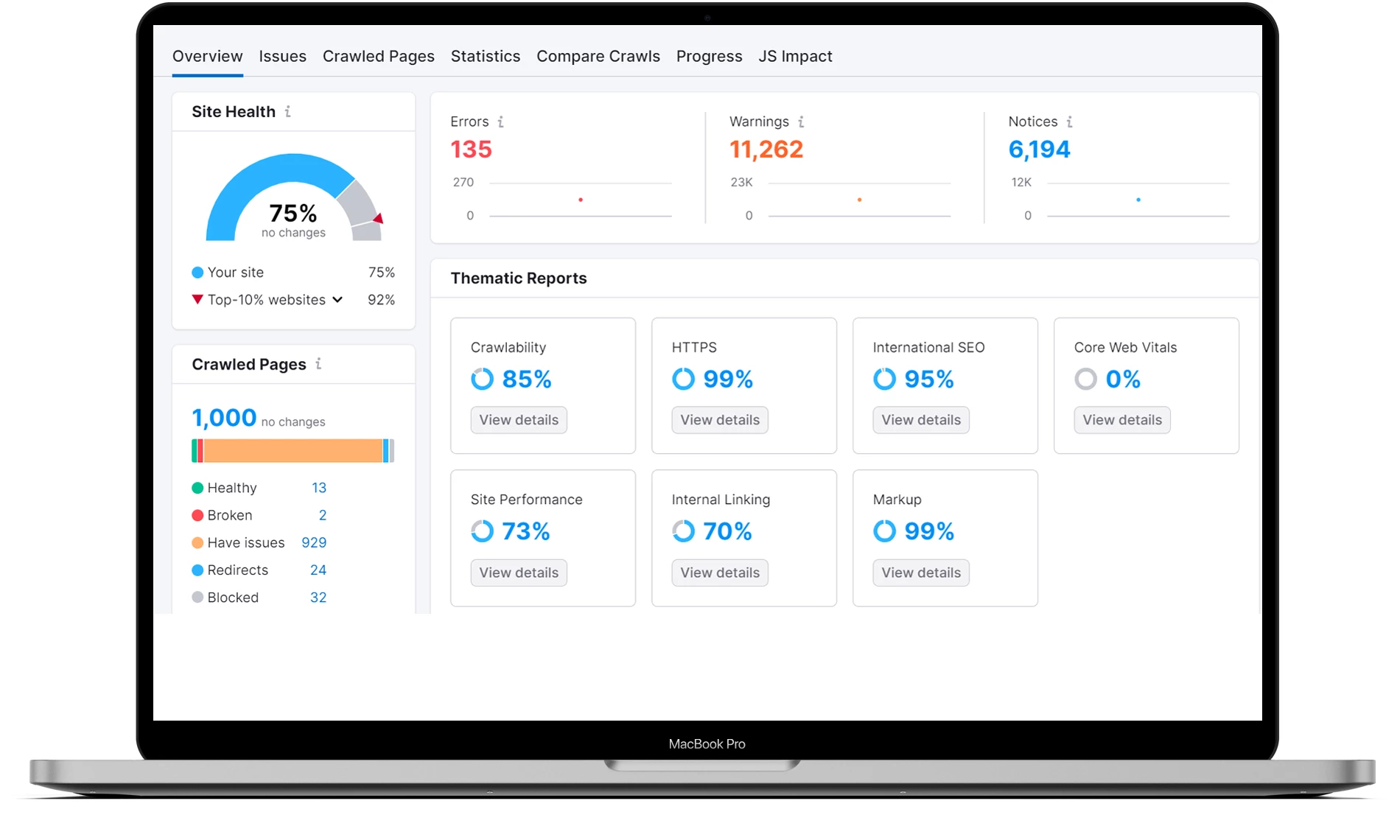
Depois de todas as páginas terem sido analisadas, aceda ao projeto e seleccione a secção “Problemas”.
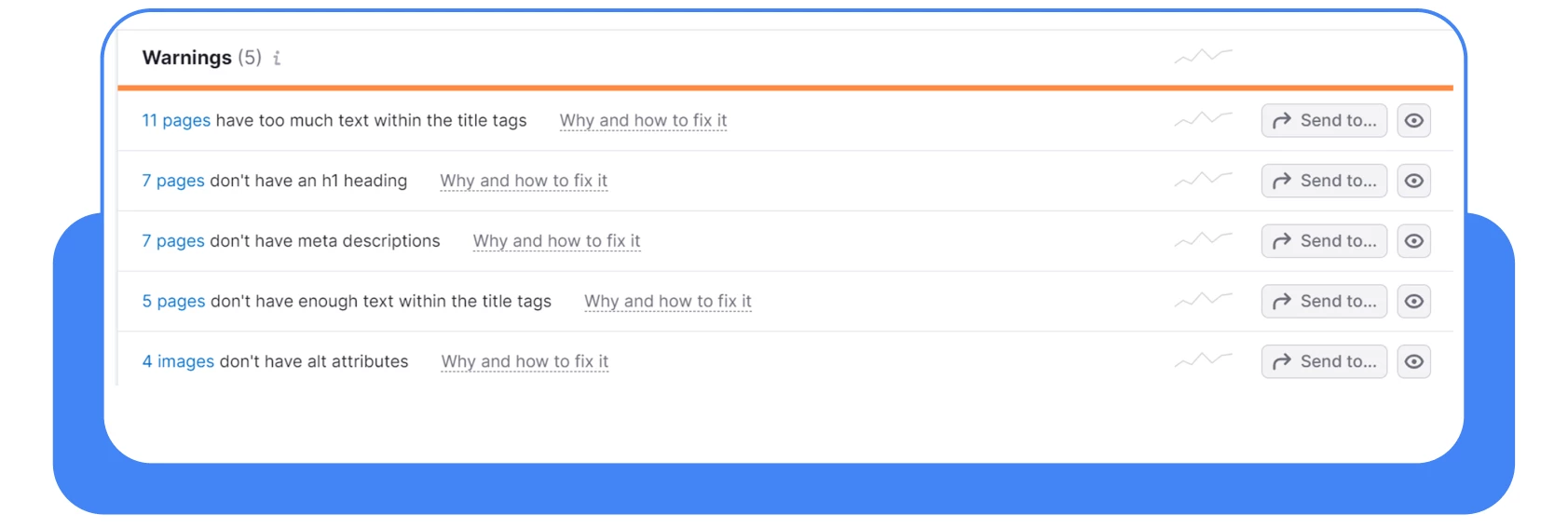
Poderá ver o seguinte erro entre os problemas – “7 páginas não têm um título h1”.
Clique em “Porquê e como corrigi-lo” e siga as recomendações. É assim tão simples e rápido.
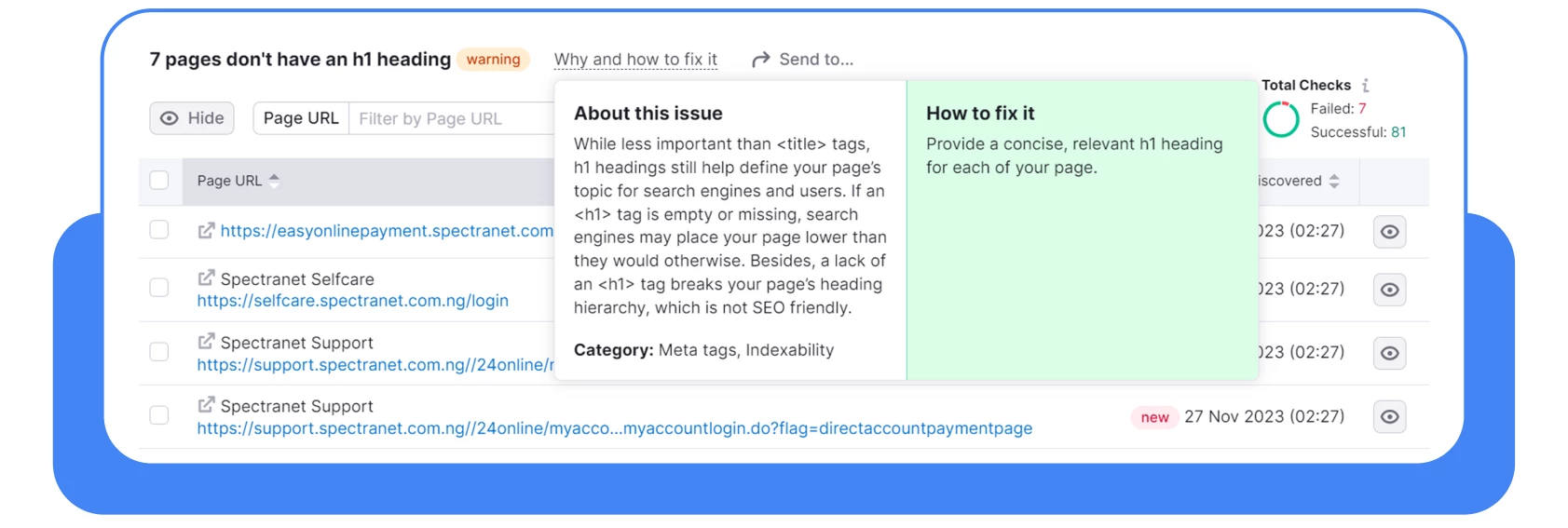
Mais abaixo, verá as páginas onde estes erros foram identificados.
Conclusão
Caros amigos, obrigado por terem lido o nosso artigo até ao fim! Quero dizer que, embora a marcação semântica possa não ser um fator de classificação, não deixa de afetar a relevância da indexação das suas páginas e a perceção do conteúdo das mesmas.
O tópico é bastante simples e não requer conhecimentos profundos de programação; um conhecimento básico de HTML é suficiente e, felizmente, existem inúmeros vídeos e cursos gratuitos de HTML5 disponíveis online.




