
Was ist Crawlability: 11 Wege zur Behebung von Crawl-Fehlern
Hallo, meine lieben SEO-versierten Freunde und Enthusiasten! Heute möchte ich über Crawlability, die häufigsten Crawlability-Probleme und Lösungen dafür sprechen. Dieser wichtige Faktor kann sich negativ auf Ihre Rankings, Ihren Traffic und die Sichtbarkeit Ihrer Website in den Suchergebnissen auswirken. Bevor wir uns den Crawl-Fehlern widmen, sollten wir herausfinden, was Crawlability ist und wie sie sich auf SEO auswirkt.

Was ist Crawlability?
Einfach ausgedrückt, bezieht sich die Crawlability auf die Fähigkeit der Suchmaschinen-Bots, Ihre Website-Seiten korrekt zu erkennen und zu crawlen. Was die technische SEO betrifft, ist dies ein wichtiger Punkt, den Sie überprüfen sollten, denn wenn Googlebot Ihre Webseiten nicht finden kann, werden sie niemals ganz oben in den Suchmaschinenergebnissen erscheinen.
Beachten Sie, dass Crawlability und Indexability unterschiedliche Dinge sind. Letzteres bezieht sich auf die Fähigkeit von Suchmaschinen, den Inhalt, den sie crawlen, korrekt zu finden und in ihren Index aufzunehmen. Google zeigt nur crawlbare und indizierbare Webseiten in den Suchmaschinenergebnissen an.
Um herauszufinden, wie viele Seiten Ihrer Website indexiert wurden, geben Sie bei Google „site:“ und die URL Ihrer Website ein. Sie können sich das folgende Beispiel ansehen, aber wenn Sie möchten, dass alles für Sie erledigt wird, können Sie gerne mit uns outsourcen!
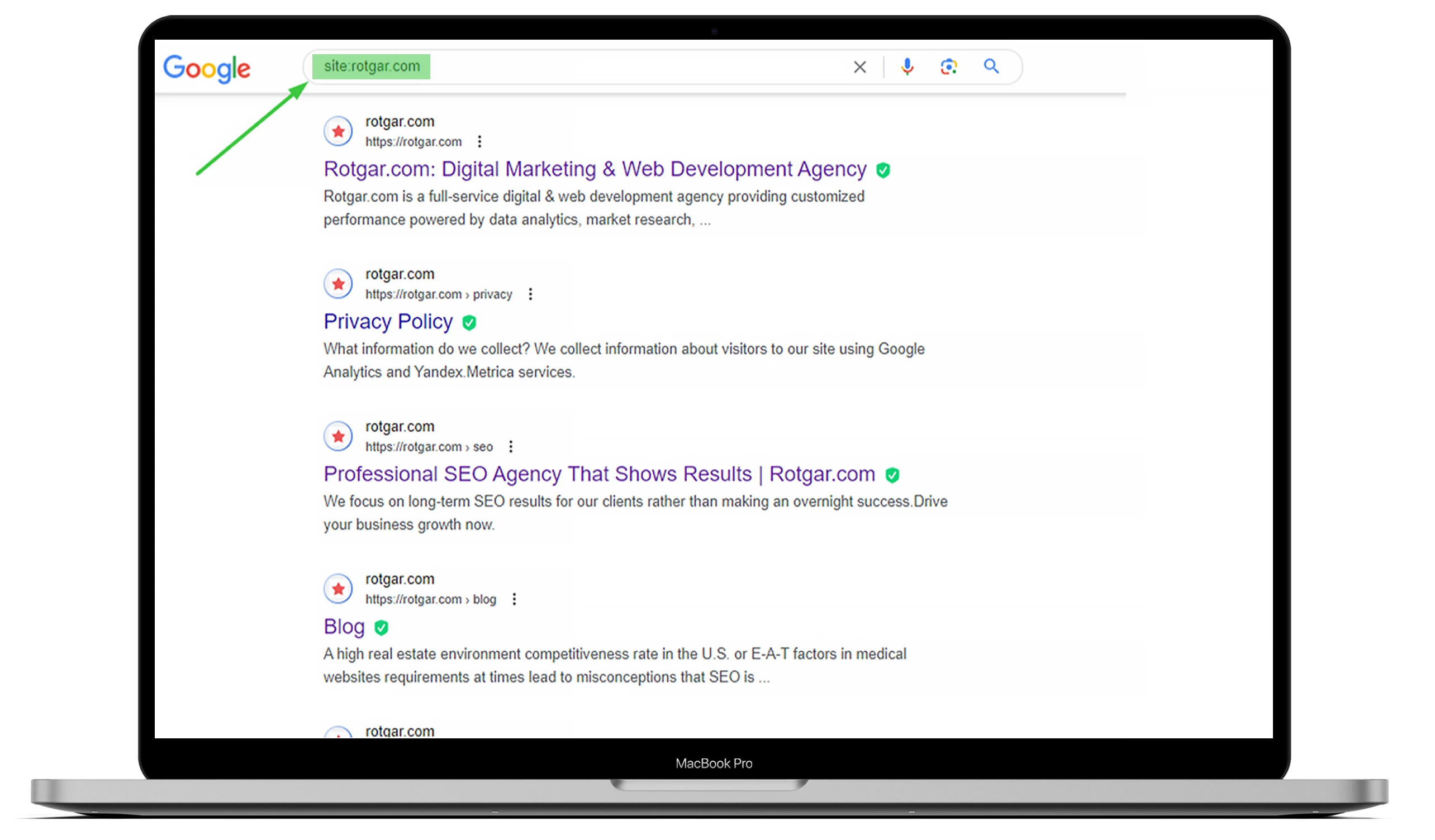
Sie sollten wissen, dass Suchmaschinen-Bots, auch bekannt als Web-Crawler, immer arbeiten, den Inhalt scannen und die gefundenen Webseiten indexieren. Sobald ein Googlebot eine Änderung feststellt, wird er die Daten aktualisieren.
Viele Dinge können die Crawlability Ihrer Website beeinträchtigen, aber in diesem Artikel werden die häufigsten Probleme erläutert.
Die Auswirkungen von Crawl-Fehlern auf SEO
Wenn die Suchmaschinenbots Probleme mit der Crawlability Ihrer Website haben, kann dies Ihre Suchmaschinenoptimierung erheblich beeinflussen. Ihre Webseiten werden nicht in den Suchergebnissen erscheinen, wenn ein Googlebot nicht weiß, ob der Inhalt für einen bestimmten Suchbegriff relevant ist.
Das bedeutet, dass sie nicht indiziert werden können, was zu einem Verlust an Konversionen und organischem Verkehr führen kann. Deshalb sind crawlbare und indizierbare Seiten für eine gute Platzierung in Suchmaschinen unerlässlich. Mit anderen Worten: Je besser Ihre Website crawlbar ist, desto wahrscheinlicher ist es, dass Ihre Seiten indiziert werden und einen besseren Platz in Google erhalten.
Wie man Crawl-Fehler in der Google Search Console findet
Jetzt wissen wir, was Crawlability und Crawl-Fehler sind und wie sie sich auf Ihre SEO auswirken. Nun ist es an der Zeit, diese Fehler schnell über das Dashboard zu finden. Wie Sie vielleicht wissen, unterteilt die Google Search Console Crawl-Fehler in zwei Bereiche: Website-Fehler und URL-Fehler. Auf diese Weise lassen sich Fehler auf Site- und Seitenebene gut unterscheiden.
In der Regel werden Site-Fehler als dringlicher eingestuft und erfordern sofortige Maßnahmen, um eine Beeinträchtigung der Nutzbarkeit Ihrer Website zu verhindern. Ich empfehle, diesen Bereich zu 100 % fehlerfrei zu halten.
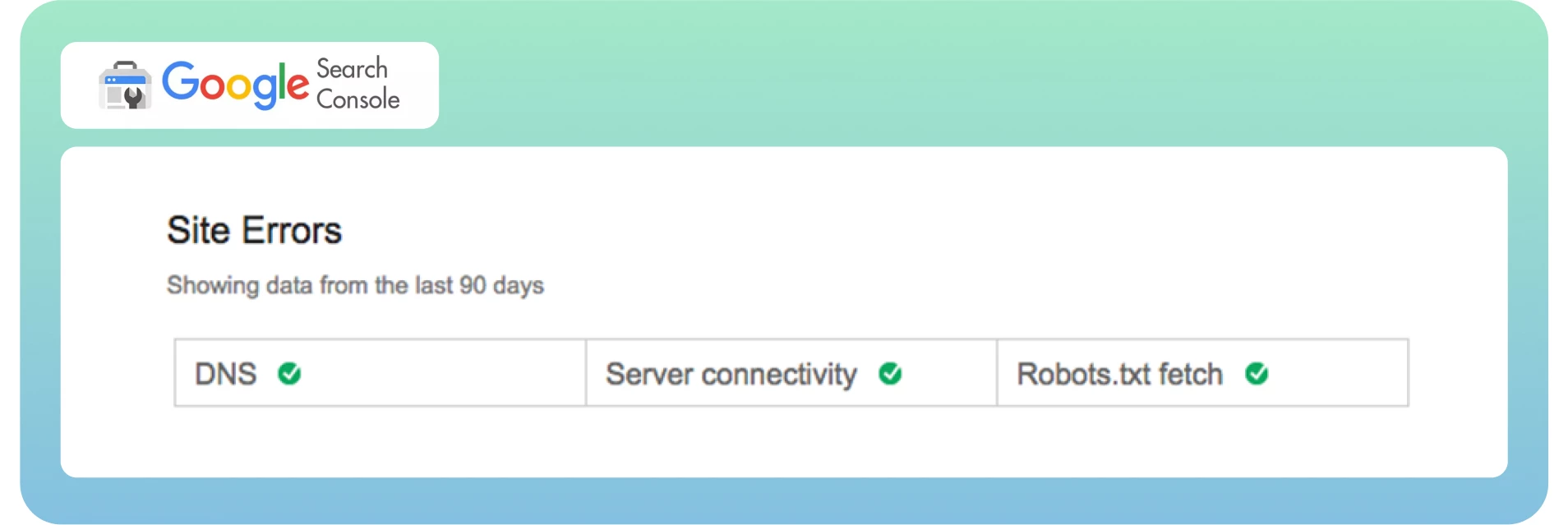
URL-Fehler klingen weniger katastrophal und sind spezifischer für einzelne Webseiten, da diese Fehler nur bestimmte Seiten und nicht die gesamte Website beeinflussen.
Am besten finden Sie Ihre Crawl-Fehler, indem Sie im Haupt-Dashboard den Abschnitt „Crawl“ aufrufen und auf „Crawl-Fehler“ klicken.
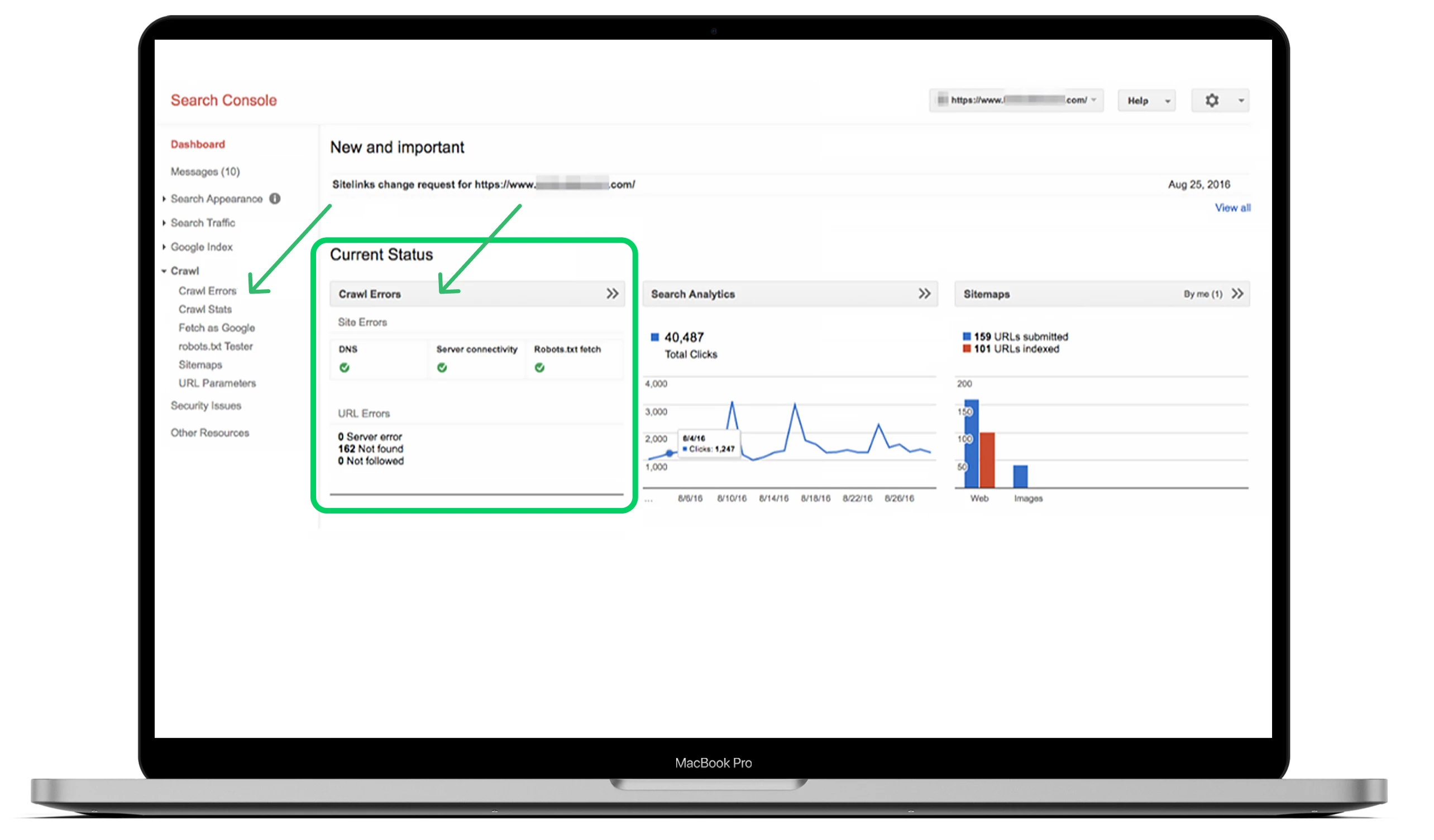
Idealerweise sollten Sie mindestens alle drei Monate nach Crawl-Fehlern suchen, um schwerwiegende Probleme zu vermeiden und die Gesundheit Ihrer Website auch in Zukunft zu erhalten.
Die 10 wichtigsten Crawl-Probleme und ihre Behebung
Sehen wir uns nun die häufigsten Crawlability-Probleme und ihre Lösungen an, um Ihre Website entsprechend zu optimieren.
1. 404-Fehler
Ein 404-Fehler ist eines der komplexesten und gleichzeitig einfachsten Probleme aller Fehler.
In der Theorie bezieht sich ein 404-Fehler auf die Fähigkeit des Googlebot, eine bestimmte Seite zu crawlen, die nicht auf Ihrer Website zu finden ist.
In der Praxis können Sie viele Seiten als 404-Fehler in der Google Search Console sehen.
Hier ist, was Google sagt:

„404-Fehler beeinträchtigen die Leistung und das Ranking Ihrer Website in Google nicht sehr stark, sodass Sie sie getrost ignorieren können.“
Es ist wichtig, 404-Fehler zu beheben, wenn Ihre wichtigen Webseiten diese Probleme haben. Achten Sie darauf, zwischen den einzelnen Seiten zu unterscheiden, um Fehler zu vermeiden und die Ursache des Problems zu finden. Letzteres ist besonders wichtig, vor allem, wenn die Seite wichtige Links von externen Quellen erhält und viel organischen Verkehr auf Ihrer Website hat.
Die Lösung
Hier sind einige Schritte, um wichtige Seiten mit 404-Fehlern zu beheben:
Prüfen Sie, ob die 404-Fehlerseite korrekt ist und von Ihrem CMS stammt, aber nicht im Entwurfsmodus ist.
Prüfen Sie, in welcher Version Ihrer Website der Fehler auftritt: WWW vs. Nicht-WWW und http vs. https.
Fügen Sie eine 301-Weiterleitung auf die relevanteste Seite Ihrer Website hinzu, wenn Sie die Seite nicht aktualisieren.
Wenn Ihre Seite nicht mehr aktuell ist, renovieren Sie sie und machen Sie sie wieder aktuell.
Um alle Ihre 404-Fehlerseiten in der Google Search Console zu finden, gehen Sie zu Crawl-Fehler -> URL-Fehler und klicken Sie auf alle Links, die Sie beheben möchten:
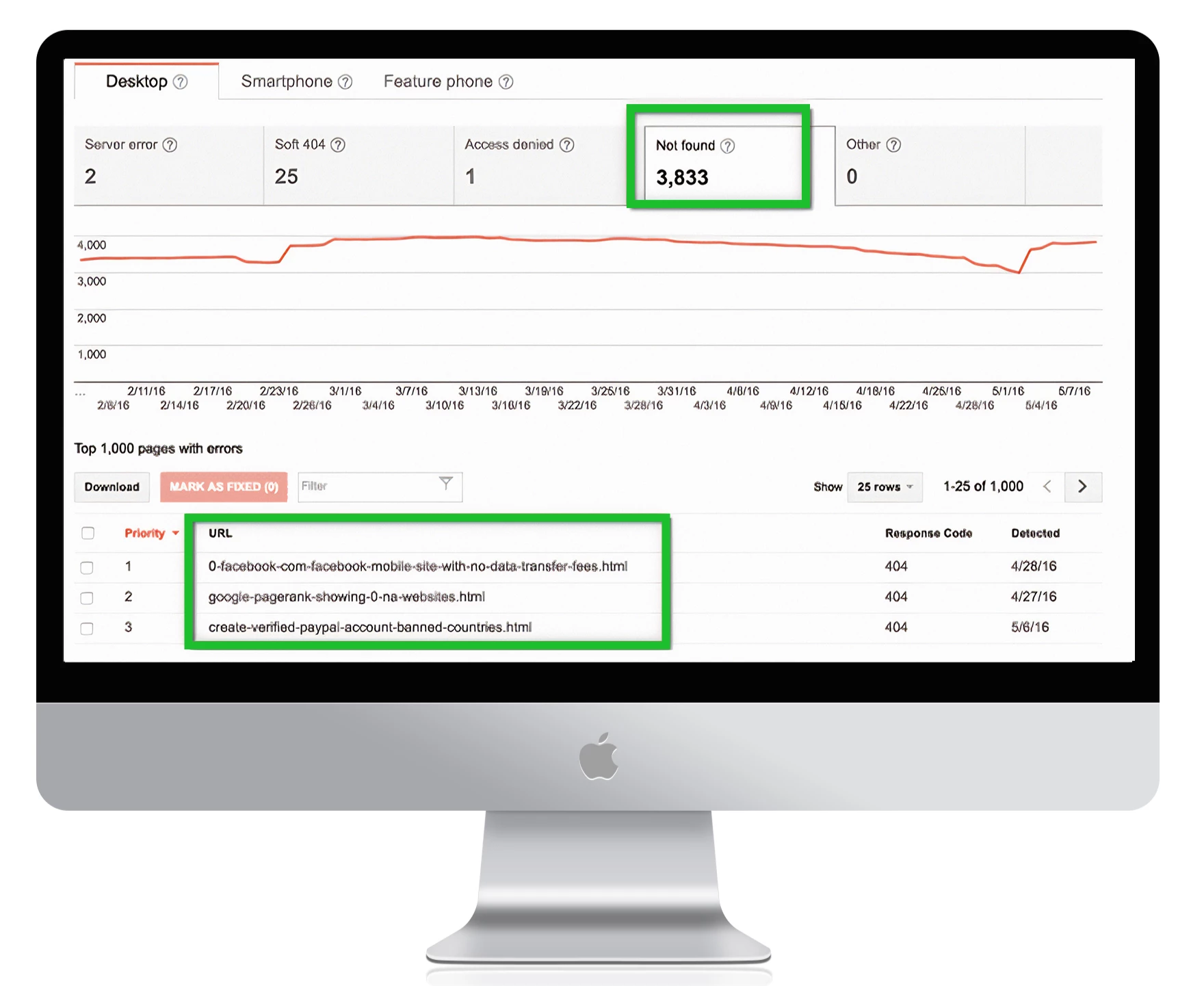
1. Beachten Sie:
Wenn Sie eine benutzerdefinierte 404-Seite haben, die keinen 404-Status zurückgibt, wird sie von Google als „Soft 404″ vermerkt. Das bedeutet, dass die Seite nicht genügend nützlichen Inhalt für die Nutzer hat und einen 200-Status zurückgibt. Technisch gesehen ist die Seite zwar vorhanden, aber leer, was die Crawl-Leistung Ihrer Website beeinträchtigt.
Soft 404-Fehler können Website-Besitzer verwirren, da sie wie eine seltsame Mischung aus 404- und Standard-Webseiten aussehen. Stellen Sie sicher, dass Googleblog die wichtigsten Seiten Ihrer Website nicht als Soft-404-Fehler einstuft.
2. Nofollow-Links
Es kann ein verwirrender Fehler für Suchmaschinen sein, die Links auf einer Website-Seite nicht zu crawlen. Das nofollow-Tag weist den Googlebot an, den Links nicht zu folgen, was zu Crawlability-Problemen auf Ihrer Website führt. So sieht der Tag aus:
<meta name=“robots“ content=“nofollow“.
In den meisten Fällen sind diese Fehler darauf zurückzuführen, dass Google Probleme mit Javascript, Flash, Weiterleitungen, Cookies oder Frames hat. Sie sollten sich nicht darum kümmern, den Fehler zu beheben, solange keine Probleme bei URLs mit hoher Priorität folgen. Wenn sie von alten URLs stammen, die nicht aktiv sind, oder von nicht indizierten Parametern, die als zusätzliches Feature dienen, ist die Priorität niedriger – aber Sie müssen diese Fehler trotzdem überprüfen.
Die Lösung
Hier sind einige Schritte, um nicht befolgte Probleme zu beheben:
● Überprüfen Sie alle Seiten mit nofollow-Tags mithilfe des Tools „Fetch as Google“, um die Website so zu sehen, wie es Googlebot tun würde.
Prüfen Sie auf Weiterleitungsketten. Google kann Weiterleitungen nicht mehr verfolgen, wenn Sie viele Schleifen haben.
Nehmen Sie die Ziel-URL, nicht die weitergeleiteten URLs, in die Sitemap auf.
Verbessern Sie Ihre Website-Architektur, damit jede Seite Ihrer Website über statische Links erreicht werden kann.
Entfernen Sie die nofollow-Tags von den Seiten, auf denen sie nicht vorhanden sein sollten.
3. Gesperrte Seiten
Wenn Suchmaschinen-Bots Ihre Website durchsuchen, überprüfen sie zuerst Ihre robots.txt-Datei. Denn sie gibt ihnen vor, welche Webseiten sie crawlen müssen und welche nicht. Hier ist ein Beispiel für die robots.txt-Datei, das zeigt, dass Ihre Website für das Crawling gesperrt ist:
Benutzer-Agent: *
Nicht zulassen: /
Leider ist dies eines der häufigsten Probleme, die die Crawlability Ihrer Website beeinträchtigen und wichtige Webseiten vom Crawling abhalten. Um dieses Problem zu beheben, sollten Sie die Direktive in dieser Datei in „Allow“ ändern, wodurch Suchmaschinen-Bots die gesamte Website crawlen können.
Benutzer-Agent: *
Erlauben: /
Wenn Sie Ihr eigenes Blog erstellen, ist es wichtig, es für das Crawling und die Indexierung zu öffnen, um alle potenziellen SEO-Vorteile zu nutzen, nachdem Sie es auf Ihre Hauptwebsite übertragen haben. Verwenden Sie einfach die Disallow: /blog* in dem unten stehenden Beispiel:
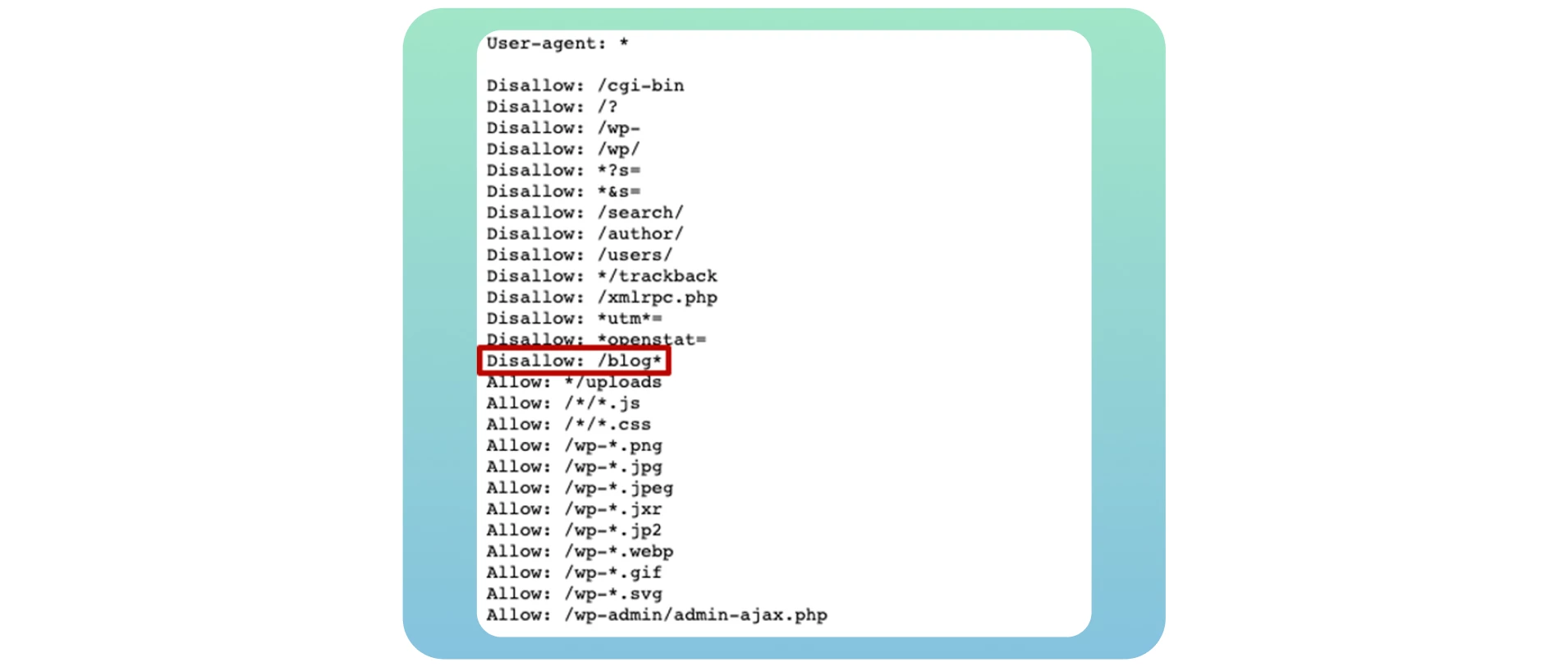
Viele Website-Besitzer bloggen bestimmte Seiten in dieser Datei, wenn sie vermeiden wollen, dass diese in den Suchergebnissen erscheinen. In den meisten Fällen handelt es sich dabei um Anmelde- und Danksagungsseiten. Es handelt sich dabei jedoch nicht um ein Crawlability-Problem, denn Sie wollen nicht, dass diese Seiten in den Suchmaschinenergebnissen angezeigt werden. Die Entdeckung eines Tippfehlers oder eines Fehlers im Regex-Code führt zu schwerwiegenderen Problemen auf Ihrer Website.
Die Lösung
Wenn Sie Ihre Seite crawlbar machen wollen, stellen Sie sicher, dass Sie dies in der robots.txt erlauben. Überprüfen Sie Ihre Datei mit dem robots.txt-Tester, um etwaige Probleme und Warnungen zu finden und bestimmte URLs in Ihrer Datei zu testen.
Sie können robots.txt-Fehler auch mit einem Website-Audit aufspüren. Glücklicherweise gibt es viele wertvolle Tools zur Durchführung eines technischen SEO-Audits, wie Screaming Frog oder Semrush. Aber zuerst sollten Sie sich registrieren und Ihre Website hinzufügen, um Ergebnisse zu erhalten.
4. Noidex“-Tags
„Noindex“-Tags teilen den Suchmaschinen mit, welche Seiten sie nicht indizieren müssen. Der Tag sieht wie folgt aus:
<meta name=“robots“ content=“nodiex“.
Die Verwendung von „noindex“-Tags auf Ihrer Website kann die Crawlbarkeit und Indexierbarkeit durch Suchmaschinen beeinträchtigen, wenn Sie diese Tags lange Zeit auf Ihren Webseiten belassen. Bei der Live-Schaltung vergessen Webentwickler oft, den „noindex“-Tag von der Website zu löschen.
Google betrachtet „noindex“-Tags als „nofollow“ und hört auf, die Links auf diesen Seiten zu crawlen. Es ist gängige Praxis, ein „noindex“-Tag auf Dankes-, Anmelde- und Verwaltungsseiten einzufügen, um eine Indizierung durch Google zu verhindern. In anderen Fällen ist es an der Zeit, diese Tags zu entfernen, wenn Sie möchten, dass Suchmaschinen-Bots Ihre Seiten crawlen.
Die Lösung
Hier sind einige Schritte, um „noindex“-Probleme zu beheben:
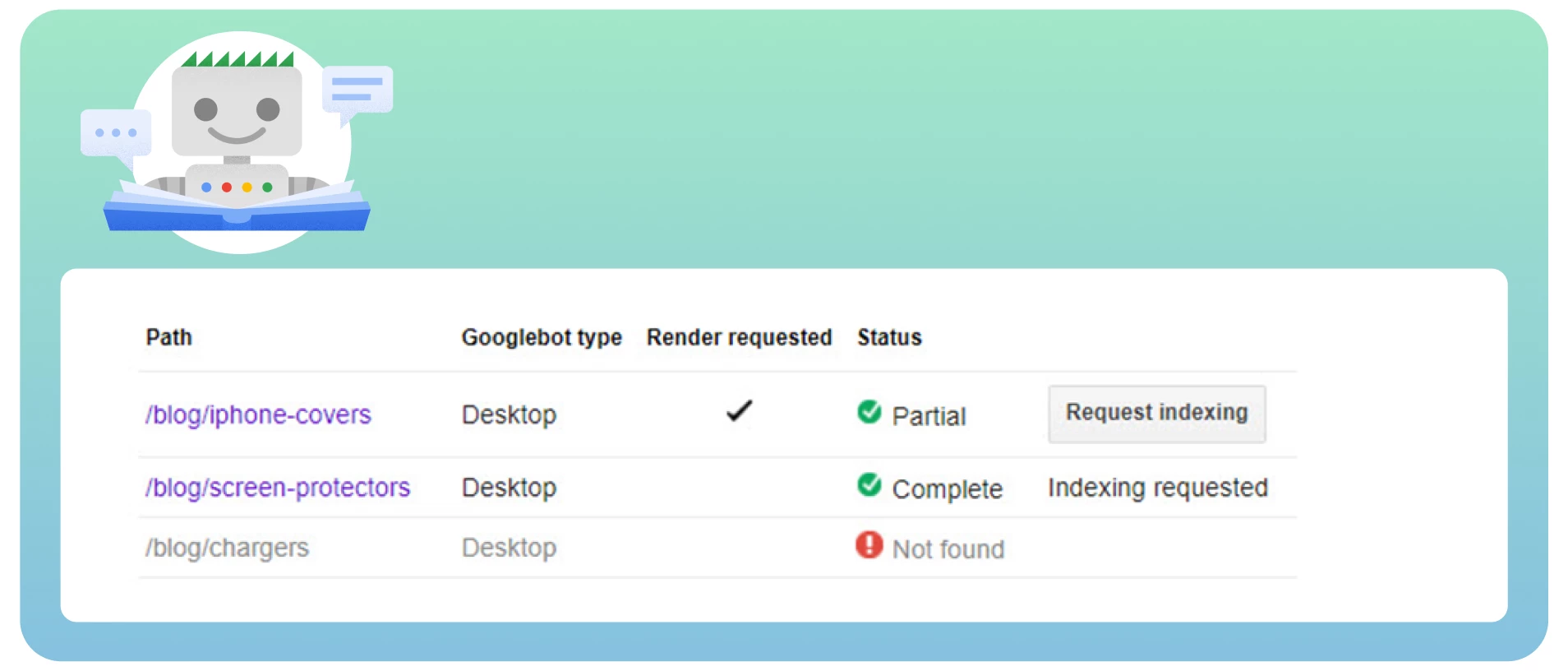
● Analysieren Sie Ihre Crawl-Statistiken in der Google Search Console, um festzustellen, wie häufig der Googlebot Ihre Website besucht.
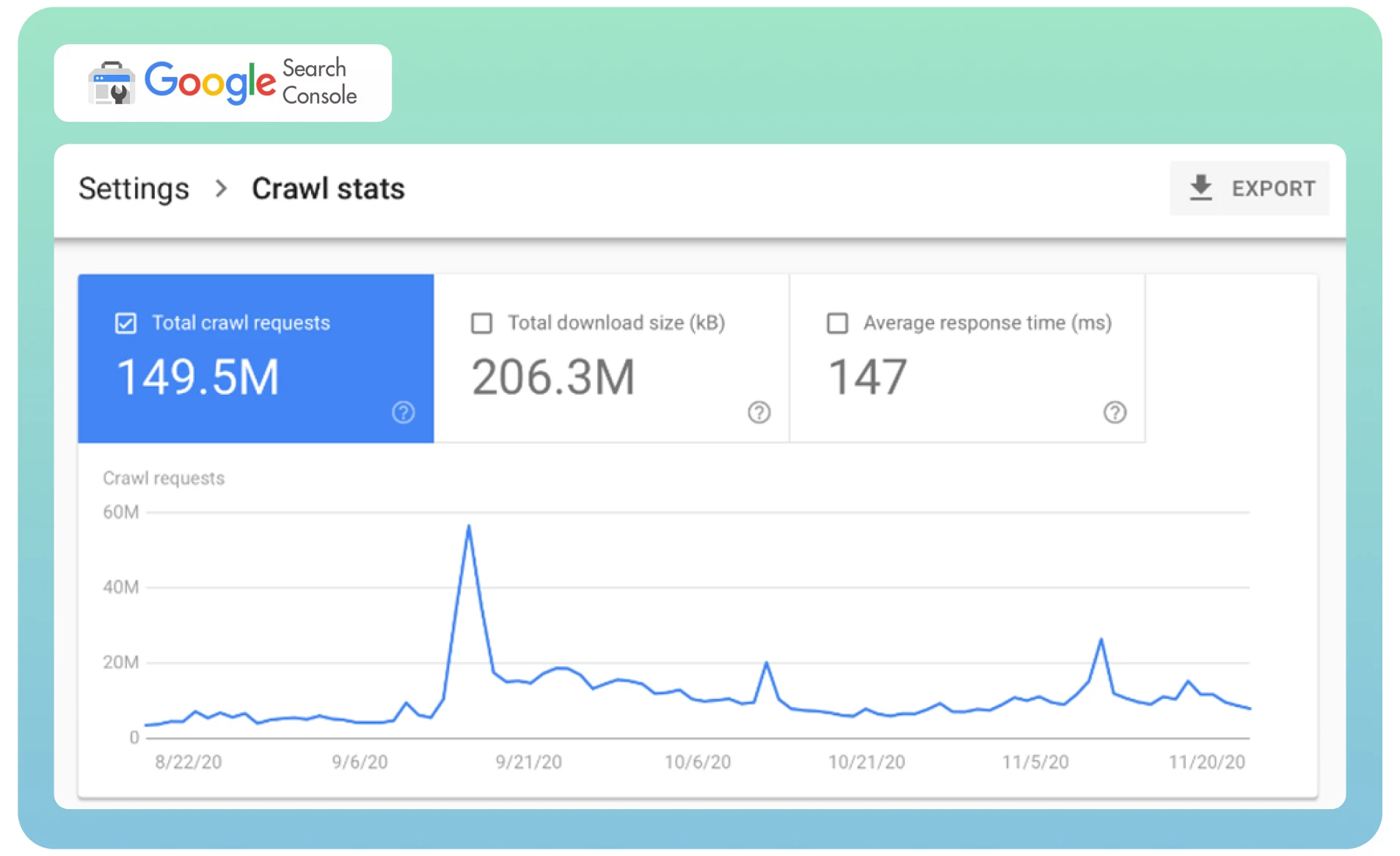
Fordern Sie Google auf, Ihre Seite mithilfe des Tools „Entfernen“ neu zu crawlen, um die bereits indizierte Seite sofort aus den SERPs zu entfernen. Dies kann einige Zeit in Anspruch nehmen.
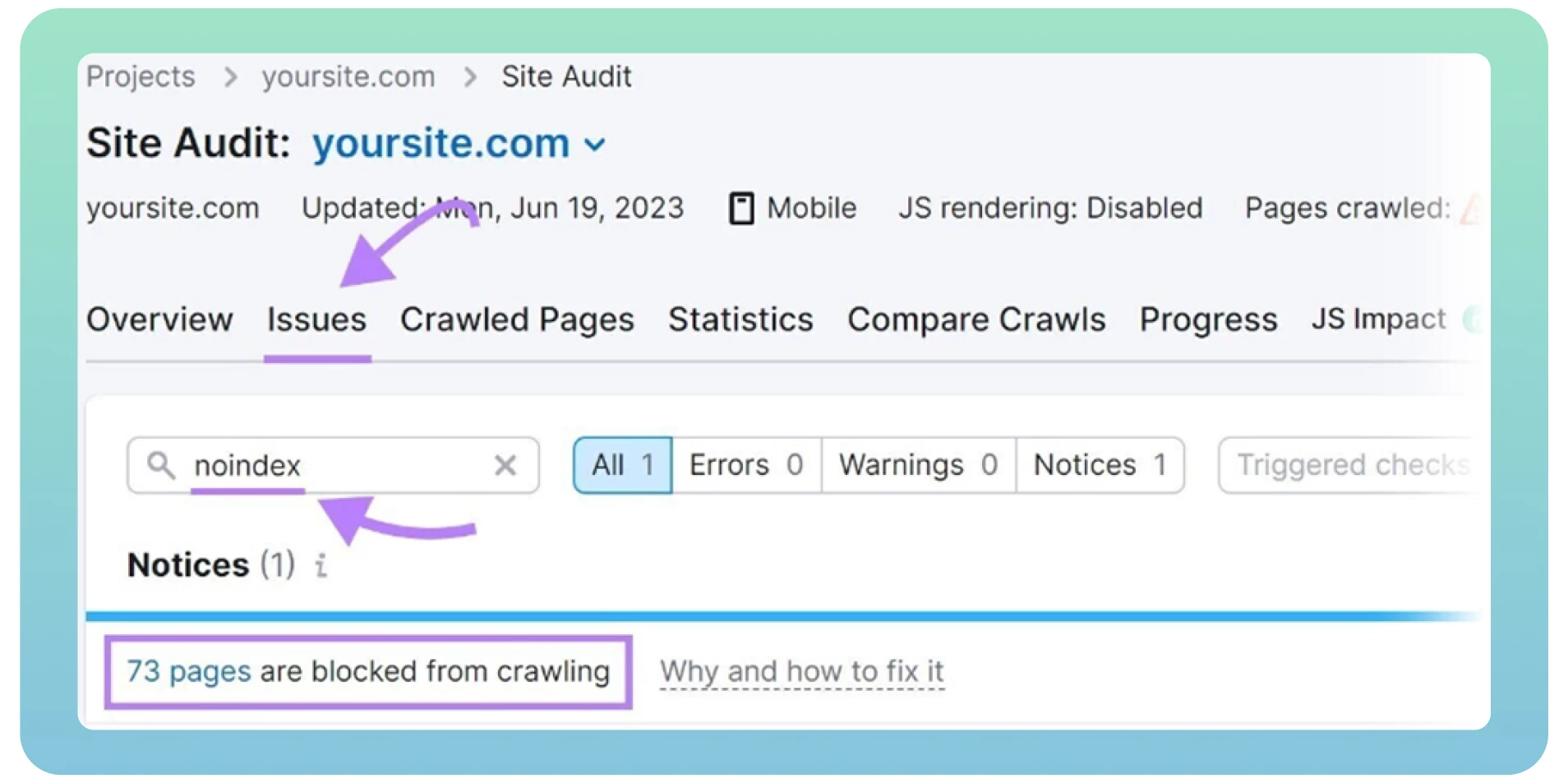
Verwenden Sie ein Website-Audit-Tool wie Semrush, um Seiten mit „noindex“-Tags zu erkennen. Es zeigt eine Liste der Seiten auf Ihrer Website an, überprüft sie und entfernt sie bei Bedarf.
5. Seitenduplikate
Oft werden verschiedene Webseiten mit demselben Inhalt von verschiedenen URLs geladen, was zu Seitenduplikaten führt. Sie haben beispielsweise zwei Versionen Ihrer Domain (www und non-www), die zur Startseite Ihrer Website führen. Diese Seiten haben keinen Einfluss auf Ihre Website-Besucher, können aber die Wahrnehmung Ihrer Website durch Suchmaschinen beeinträchtigen.
Das Schlimmste ist, dass die Suchmaschinen nicht erkennen können, welche Seite aufgrund von doppeltem Inhalt als vorrangig zu betrachten ist. Der Googlebot durchforstet jede Seite schnell und wird denselben Inhalt erneut indexieren.
Idealerweise sollte der Bot jede Seite nur einmal crawlen und indexieren. Außerdem erhalten verschiedene Versionen derselben Seite organischen Traffic und Page Rank, was die Analyse von Traffic-Metriken in Google Analytics erschwert.
Die Lösung
Die Kanonisierung ist die bevorzugte Methode für Duplikate, um SEO-Autorität zu erhalten. Hier sind einige Tipps zu beachten:
● Verwenden Sie kanonische Tags, damit Google die ursprüngliche URL einer Seite leicht erkennen kann. Der Link mit diesem Tag sollte wie folgt aussehen:
<link rel=“canonical“ href=“https://example.com/page/“ />
● Überprüfen Sie die Warnmeldungen in der Google Search Console – es kann etwas wie „Zu viele URLs“ oder ähnliches sein, wenn Google auf mehr URLs und Inhalte stößt, als es sein sollte.
● Verwenden Sie nicht gleichzeitig kanonische und noindex-Tags, da Suchmaschinen-Bots kanonische Webseiten als Duplikate betrachten können.
● Kanonisieren Sie auf die Seite „Alle anzeigen“.
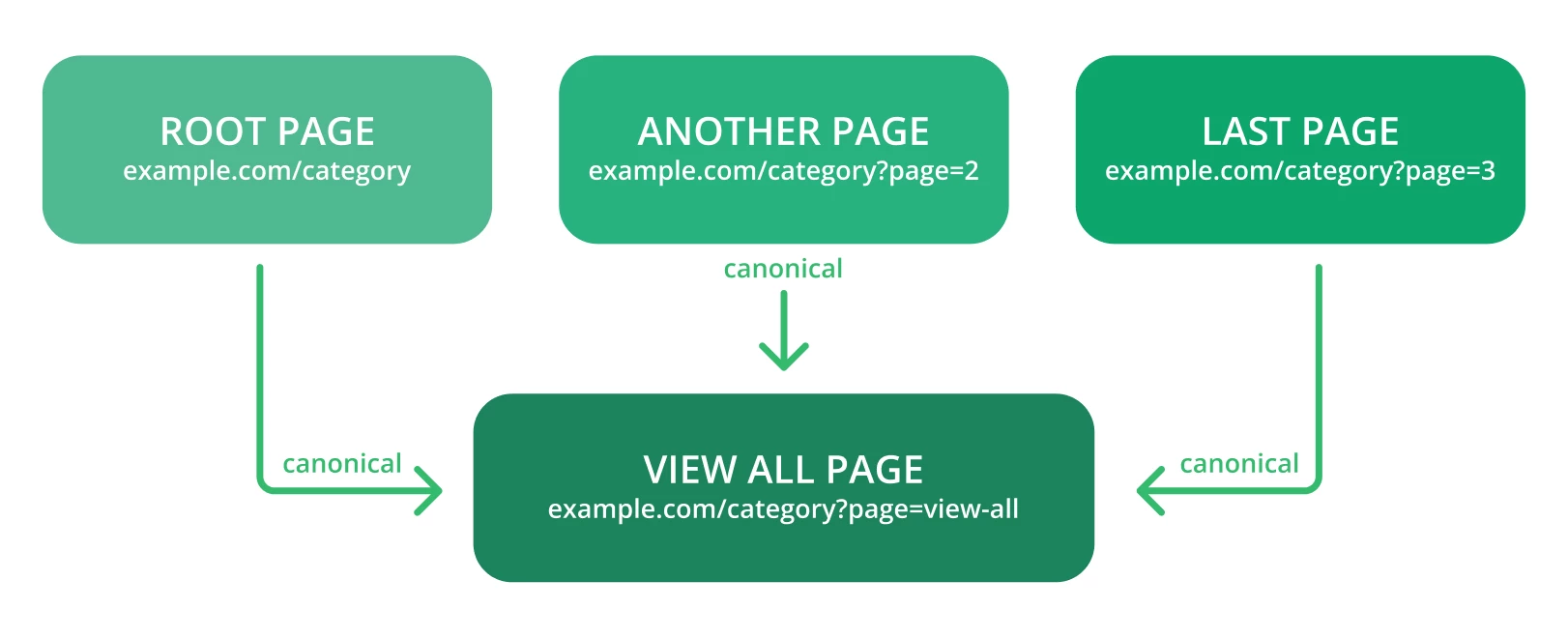
Kanonisieren Sie jede URL, die durch eine facettierte Navigation erstellt wurde.
6. Langsame Ladegeschwindigkeit
Die Ladegeschwindigkeit einer Seite ist einer der wichtigsten Faktoren, die die Crawlability Ihrer Website beeinflussen. Eine langsame Ladegeschwindigkeit kann zu einem schlechten Benutzererlebnis führen und die Anzahl der Seiten reduzieren, die von Suchmaschinen-Bots innerhalb einer Crawl-Sitzung gecrawlt werden können. Das kann dazu führen, dass wichtige Webseiten vom Crawling ausgeschlossen werden.
Mit einfachen Worten: Je schneller Ihre Webseiten geladen werden, desto schneller kann der Googlebot den Inhalt der Website crawlen und eine bessere Platzierung in den Suchergebnissen erzielen. Deshalb ist die Verbesserung der gesamten Website-Leistung und -Geschwindigkeit so wichtig.
Die Lösung
Hier sind einige nützliche Tipps, die Sie bei der Optimierung der Website-Geschwindigkeit berücksichtigen sollten:
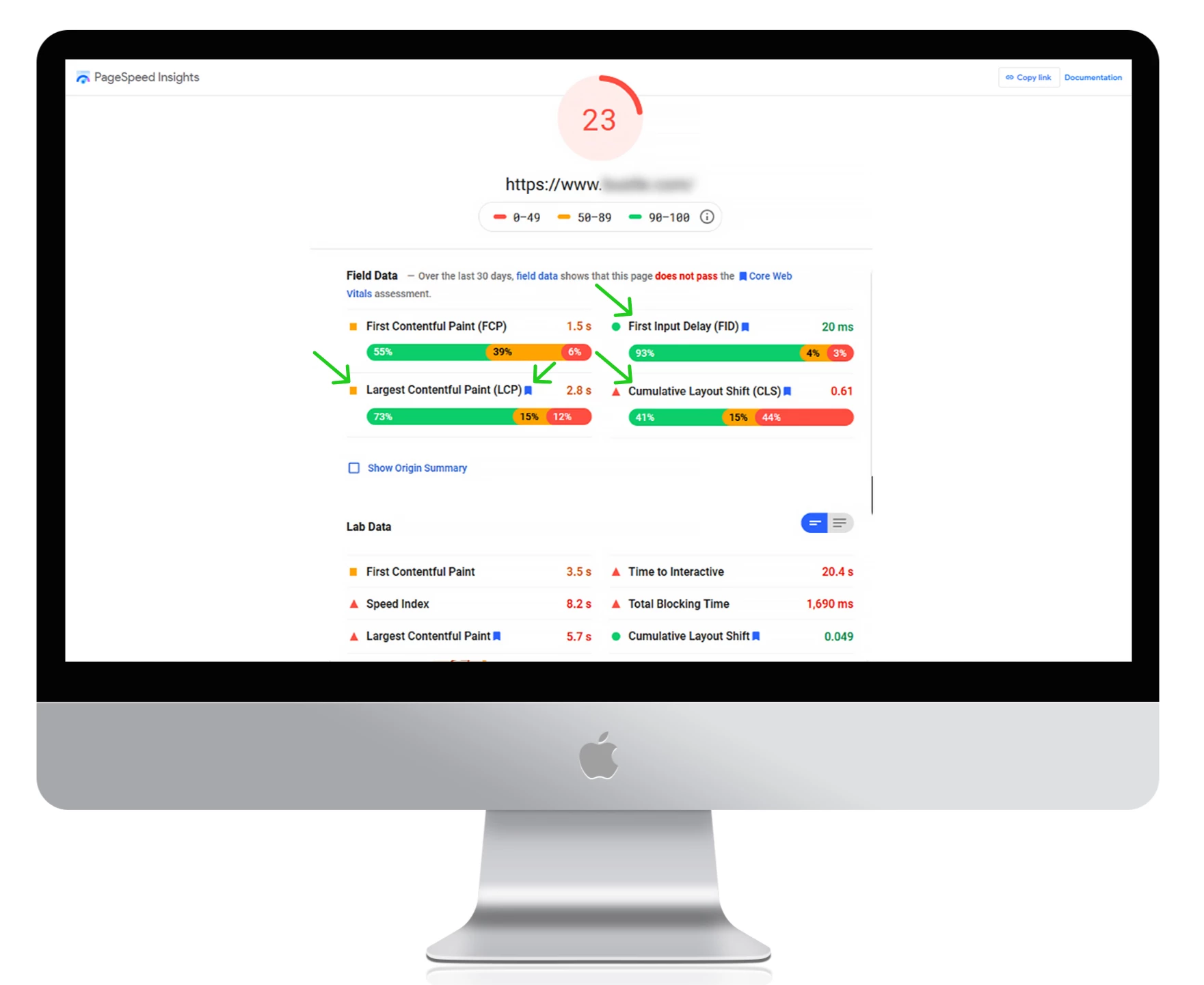
● Verwenden Sie Google PageSpeed Insights, um Ihre aktuellen Ladezeiten zu messen, mögliche Fehler zu erkennen und umsetzbare Tipps zur Verbesserung der Website-Leistung zu erhalten.
Verwenden Sie ein Content Delivery Network (CDN), um Ihre Inhalte über verschiedene Server weltweit umzuleiten. Dadurch wird die Latenzzeit verringert und Ihre Website arbeitet schneller.
Wählen Sie einen schnellen Webhosting-Anbieter.
Komprimieren Sie die Dateigrößen von Bildern und Videos, um die Ladegeschwindigkeit zu erhöhen.
Entfernen Sie unnötige Plugins und reduzieren Sie die Anzahl der CSS- und JacaScript-Dateien auf Ihrer Website.
7. Fehlende interne Links
Webseiten mit einem Mangel an internen Links können Crawlability-Probleme aufweisen. Interne Links beziehen sich auf die Verknüpfung einer Seite mit einer anderen relevanten Seite innerhalb der gleichen Domain. Sie erleichtern den Benutzern die Navigation innerhalb Ihrer Website und liefern den Suchmaschinen hilfreiche Informationen über Ihre Struktur und Hierarchie.
Jede Seite Ihrer Website sollte mindestens einen internen Link haben, der zu ihr führt. Das zeigt den Suchmaschinen, dass Ihre Seiten zusammenhängen und miteinander verbunden sind. Isolierte Seiten machen es den Bots schwer, sie als Teil Ihrer Website zu betrachten. Je mehr relevante interne Links Sie haben, desto einfacher und schneller crawlen die Bots die gesamte Website.
Die Lösung
Hier sind einige praktische Tipps, die Sie berücksichtigen sollten:
● Führen Sie ein SEO-Audit durch, um festzustellen, wo Sie mehr interne Links von relevanten Seiten Ihrer Website einfügen sollten.
● Schauen Sie sich die Analysen der Website an, um zu sehen, wie die Nutzer durch die Website strömen, und finden Sie Wege, sie mit Ihren relevanten Inhalten anzusprechen. Achten Sie auf Seiten mit hohen Absprungraten, um sie zu verbessern und mehr hochwertige Inhalte hinzuzufügen.
Priorisieren Sie wichtige Seiten, indem Sie sie in der Website-Hierarchie höher stellen und mehr interne Links zu ihnen hinzufügen.
Fügen Sie beschreibende Ankertexte ein, um den Inhalt der verlinkten Seiten darzustellen.
Aktualisieren Sie Ihre alten URLs oder entfernen Sie defekte Links. Stellen Sie sicher, dass jede Verbindung auf Ihrer Website relevant und aktiv ist.
Überprüfen Sie alle Tippfehler in der URL, die Sie auf Ihren Webseiten angeben, und entfernen Sie sie.
8. Verwendung von HTTP anstelle von HTTPS
Die Serversicherheit ist nach wie vor einer der wichtigsten Faktoren beim Crawlen und Indizieren. HTTP ist das Standardprotokoll, das Daten von einem Webserver zu einem Browser überträgt. HTTPS gilt als die sicherste Alternative zur HTTP-Version.
In den meisten Fällen bevorzugen die Browser HTTPS-Seiten gegenüber HTTP-Seiten. Letzteres wirkt sich negativ auf das Ranking und die Crawlability einer Website aus.
Die Lösung
Besorgen Sie sich ein SSL-Zertifikat, damit Google Ihre Website schnell crawlen kann und eine sichere und verschlüsselte Verbindung zwischen Ihrer Website und den Nutzern besteht.
Schalten Sie Ihre Website auf die HTTPS-Version um.
Überwachen und aktualisieren Sie die Sicherheitsprotokolle. Vermeiden Sie abgelaufene SSL-Zertifikate, alte Protokollversionen oder die falsche Registrierung Ihrer Website-Informationen.
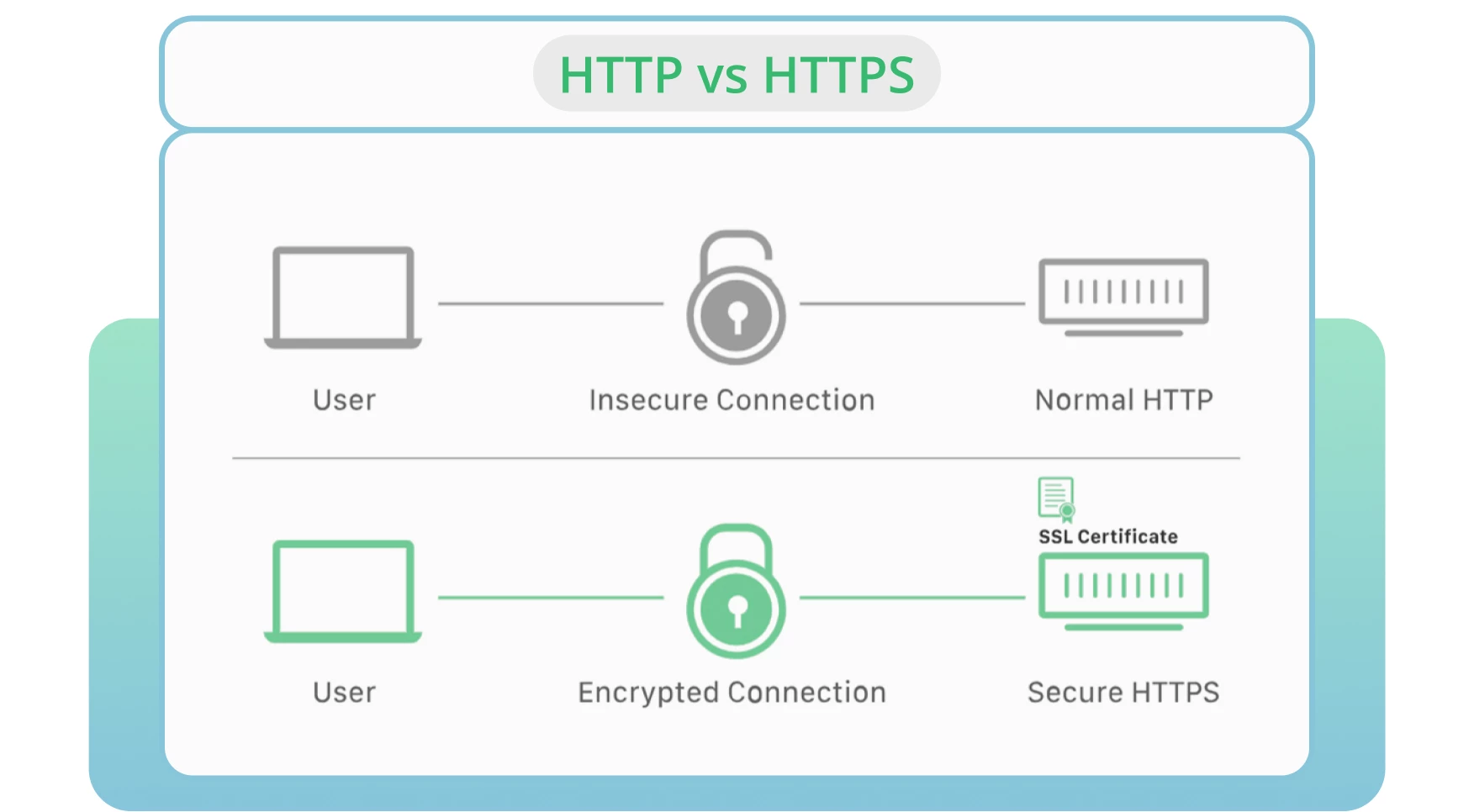
9. Umleitungsschleifen
Umleitungen sind unerlässlich, wenn Sie Ihre alte URL auf eine neue, relevante Seite umleiten müssen. Leider kommt es oft zu Problemen mit Weiterleitungen, wie z. B. Weiterleitungsschleifen. Das kann Nutzer verärgern und Suchmaschinen davon abhalten, Ihre Seiten zu crawlen.
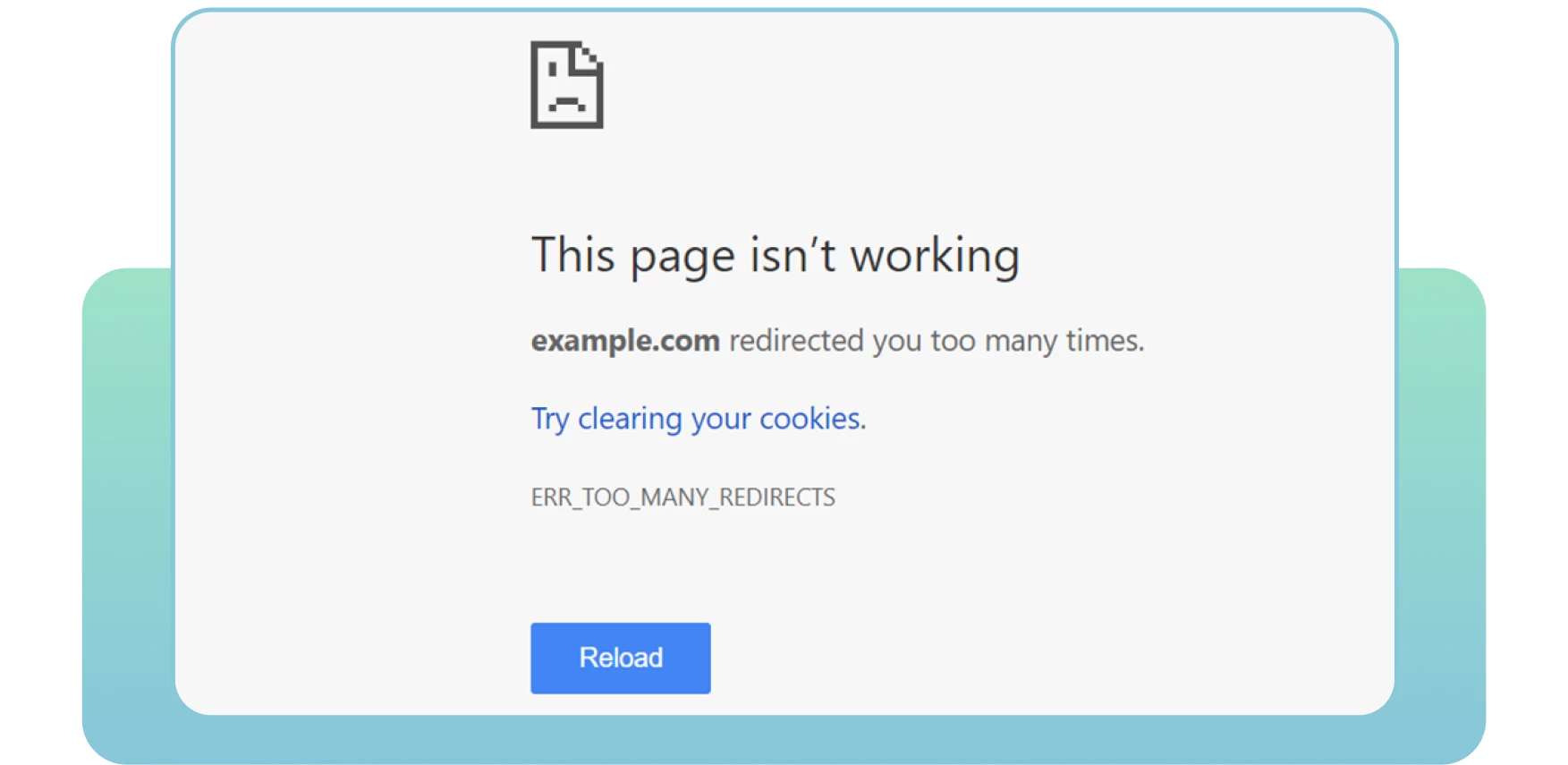
Von einer Umleitungsschleife spricht man, wenn eine URL auf eine andere umleitet und zur ursprünglichen URL zurückkehrt. Dieses Problem führt dazu, dass Suchmaschinen einen endlosen Zyklus von Weiterleitungen zwischen zwei oder mehr Seiten bilden. Dies kann sich auf Ihr Crawl-Budget und das Crawlen Ihrer wichtigen Seiten auswirken.
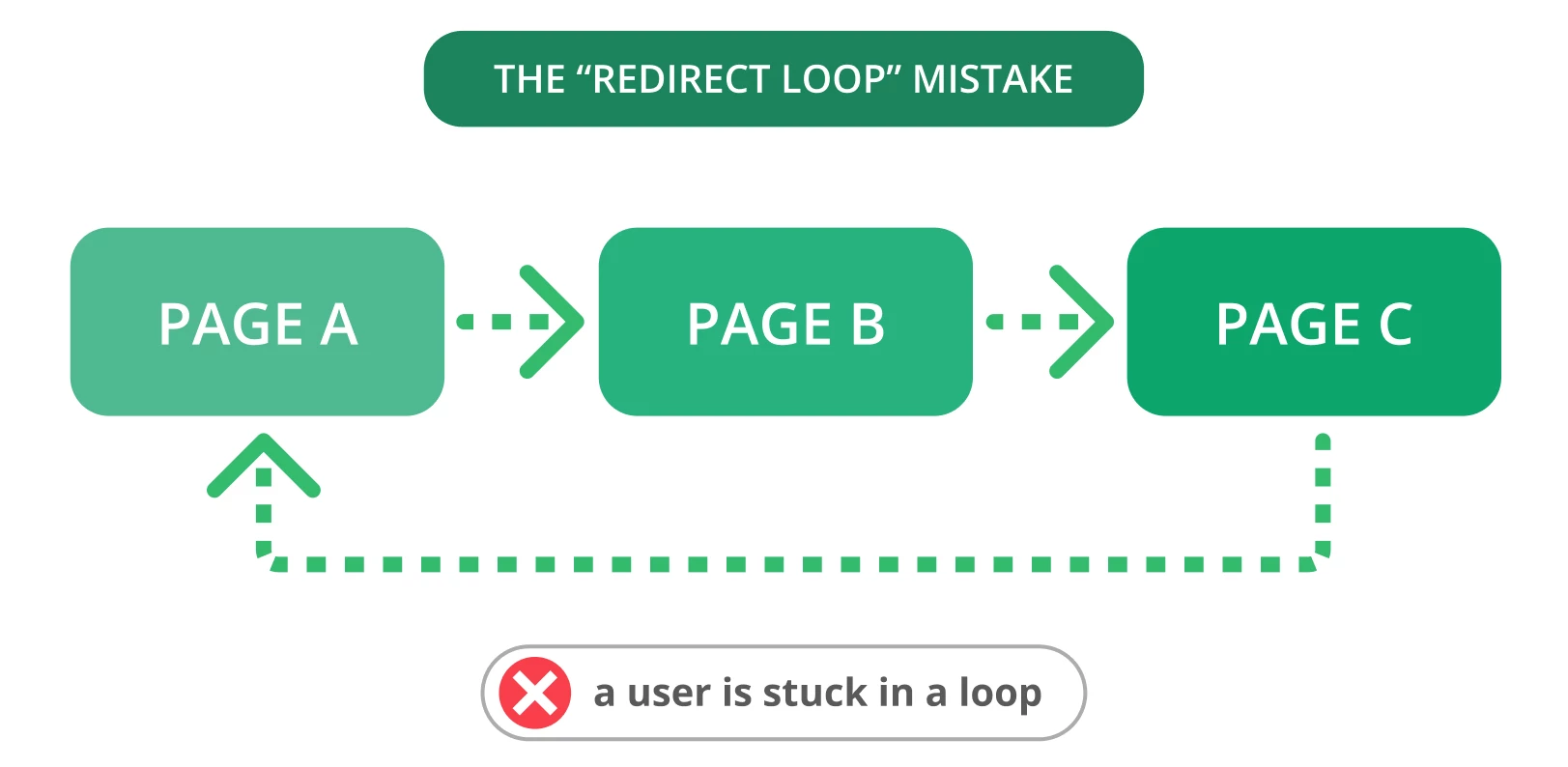
Die Lösung
Hier sind einige Schritte, um Redirect-Schleifen zu beheben:
● Verwenden Sie den HTTP Status Checker, um Weiterleitungsketten und HTTP-Statuscodes schnell zu finden.
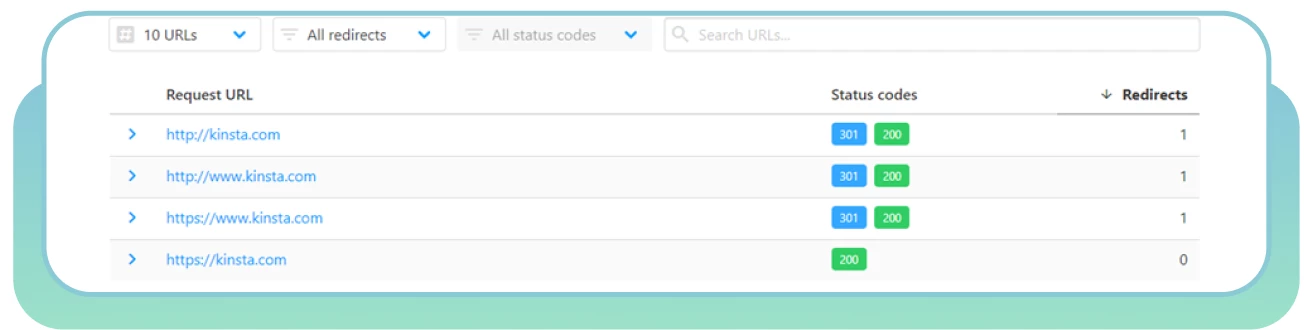
Wählen Sie die „richtige“ Seite und leiten Sie andere Seiten dorthin um.
Löschen Sie den Redirect, der die Schleife verursacht.
Markieren Sie die Seiten mit einem 403-Statuscode als nofollow, um Ihr Crawl-Budget zu optimieren. Diese Seiten können nur für registrierte Benutzer verwendet werden.
Fügen Sie temporäre Weiterleitungen ein, um den Suchmaschinen-Bots mitzuteilen, dass sie zu Ihrer Seite zurückkehren sollen. Verwenden Sie eine permanente Weiterleitung, wenn Sie die ursprüngliche Seite nicht mehr indizieren wollen.
10. Schlechte Website-Architektur
Die Organisation der Seiten und Inhalte Ihrer Website ist einer der wichtigsten Faktoren bei der Optimierung der Crawlability. Eine schlechte Website-Architektur führt zu Crawling-Fehlern, wenn Web-Crawler Webseiten entdecken, die in der Hierarchie weit unten stehen oder nicht verlinkt sind (so genannte „verwaiste Seiten“).
Eine gut strukturierte Website hilft Suchmaschinen, alle Seiten leicht zu finden und aufzurufen, was sich positiv auf Ihre Leistung und SEO auswirken kann. Eine ideale Website-Struktur bedeutet, dass jede Seite nur wenige Klicks von der Startseite entfernt ist, ohne verwaiste Seiten.
Eine typische Website-Struktur kann zum Beispiel wie eine Pyramide aussehen. An der Spitze steht die Homepage, und mehrere Ebenen verweisen auf die Seiten zu den Hauptthemen und führen zu den Unterthemenseiten. Beachten Sie die Beispielseitenstruktur unten.
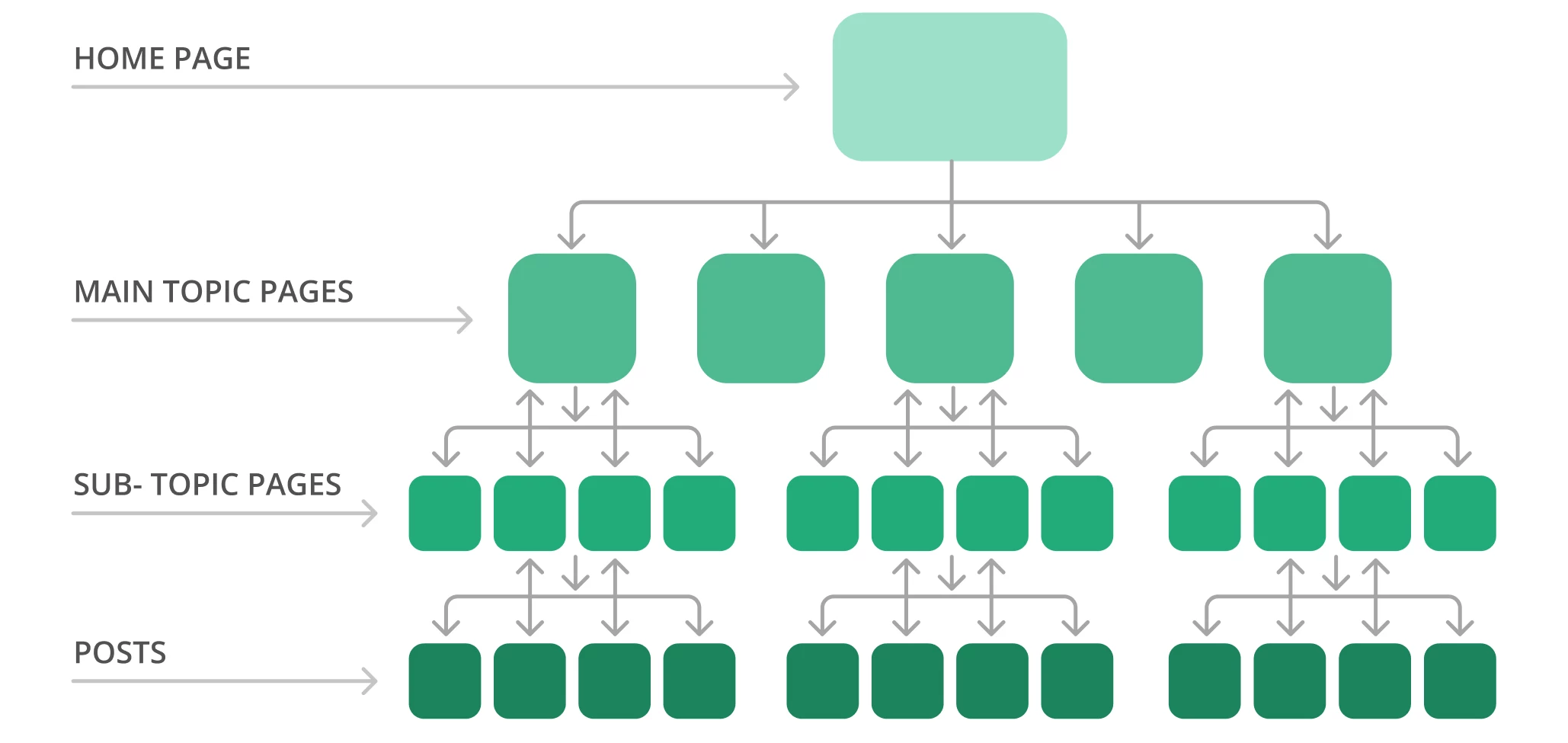
Google durchsucht die Website in der Regel vom Anfang der Homepage bis zum Ende. Mit anderen Worten: Je weiter Ihre Seiten von der Startseite entfernt sind, desto komplizierter werden sie von den Suchmaschinenbots gefunden, vor allem wenn Sie viele verwaiste Seiten haben.
Die Lösung
Hier sind einige Schritte zur Optimierung Ihrer Website-Architektur:
Nutzen Sie Screaming Frog, um Ihre aktuelle Site-Struktur und Crawl-Tiefe zu überprüfen.
Organisieren Sie Ihre Seiten logisch in einer Hierarchie mit internen Links. Erreichen Sie Ihre wichtigen Seiten mit zwei oder drei Klicks von der Startseite aus.
● Erstellen Sie eine klare URL-Struktur. Sorgen Sie dafür, dass Suchmaschinen und Benutzer den Kontext und die Relevanz jeder Seite auf Ihrer Website leicht erkennen können. Fügen Sie, wenn möglich, in jede URL die gewünschten Schlüsselwörter ein.
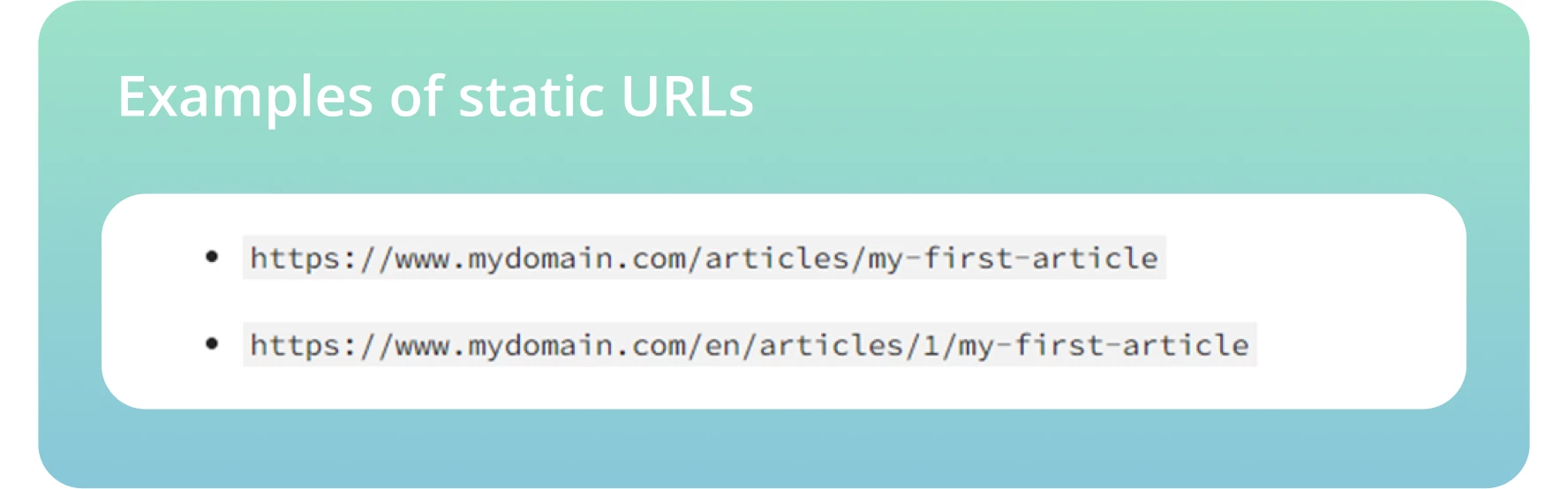
● Verwenden Sie statische URLs und vermeiden Sie dynamische URLs, die Sitzungs-IDs oder andere URL-Parameter enthalten, die das Crawlen und Indizieren durch Bots erschweren.
● Erstellen Sie Breadcrumbs, damit Google Ihre Websites besser versteht und die Nutzer schnell vor- und zurückblättern können.

11. Schlechtes Sitemap-Management
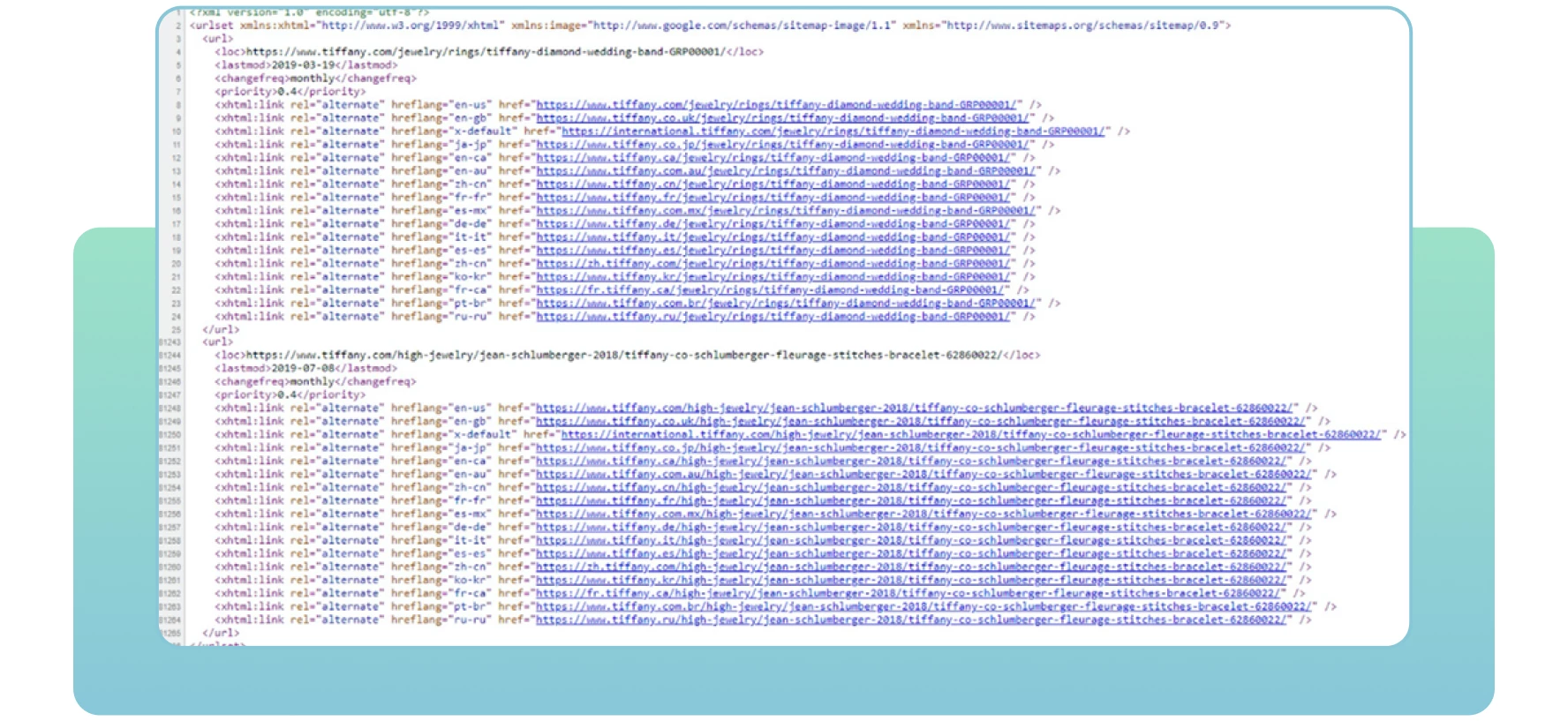
Sitemaps beziehen sich auf XML-Dateien mit wichtigen Informationen über die Seiten Ihrer Website. Sie teilen den Suchmaschinen mit, welche Seiten auf der Website wichtig sind, die Sie crawlen und indexieren möchten. Sitemaps enthalten auch Informationen über die Bilder, Videos und andere Mediendateien Ihrer Website. Unten sehen Sie ein Beispiel für eine Sitemap:
Mit Sitemaps können Suchmaschinen Ihre wichtigen Webseiten finden und effektiv crawlen. Wenn Sie einige Seiten, die indiziert und bewertet werden sollen, nicht einbeziehen, werden sie von den Suchmaschinen möglicherweise nicht bemerkt, was zu Crawl-Problemen und geringerem Website-Traffic führt.
Die Lösung
Im Folgenden finden Sie einige Schritte, die Sie in Bezug auf Sitemaps beachten sollten:
Verwenden Sie das Tool XML-Sitemaps, um eine Sitemap zu erstellen oder zu aktualisieren.
Vergewissern Sie sich, dass alle erforderlichen Seiten darin enthalten sind und dass keine Serverfehler vorliegen, die den Zugriff für Webcrawler erschweren könnten.
Übermitteln Sie Ihre Sitemap an Google. In der Regel finden Sie die Sitemap, indem Sie der URL Ihrer Website folgen, die im Folgenden dargestellt ist: domain.com/sitemap.xml
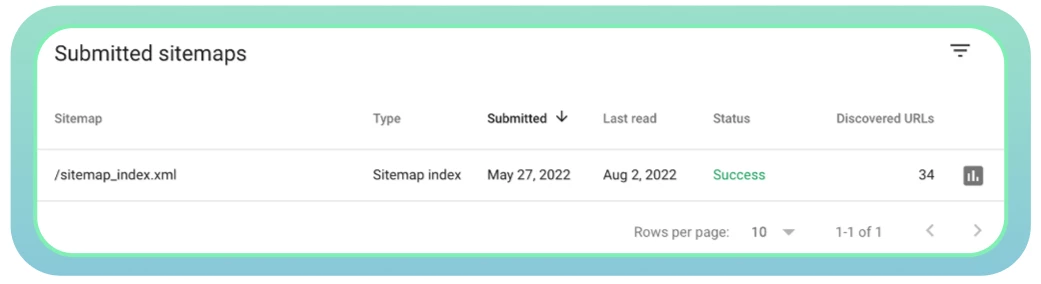
Verwenden Sie die Google Search Console, um den Status Ihrer Sitemap zu überwachen und eventuelle Probleme festzustellen.
● Aktualisieren Sie Ihre Sitemap, sobald neue Seiten hinzugefügt oder von Ihrer Website gelöscht werden. So können Suchmaschinen genaue Informationen über alle Ihre Webseiten erhalten.
Schlussfolgerung
Es gibt viele Gründe, warum einige Ihrer Seiten vor Google verborgen sind und nicht gerankt werden. Prüfen Sie zunächst, ob Ihre Website frei von Crawlability-Problemen ist
Viele Crawling-Fehler können die Leistung Ihrer Website beeinträchtigen und den Suchmaschinen-Bots mitteilen, dass bestimmte Webseiten es nicht wert sind, gecrawlt zu werden. Das hat zur Folge, dass Google Ihre wichtigen Seiten, auf die sie nicht zugreifen können, nicht indiziert und bewertet.
Deshalb ist es wichtig, Crawlability-Probleme zu finden und sie zu beheben. Durch die Umsetzung der oben genannten Lösungen können Sie Ihre Website für eine bessere Leistung optimieren und Suchmaschinen und Nutzern helfen, sie leicht zu finden.
Liebe Freunde! Ich hoffe, dass dieser Artikel interessant war, und würde mich freuen, wenn er Ihnen nützt. Auf baldiges Wiedersehen!




