
What is Crawlability: 11 Ways to Fix Crawl Errors
Hello, my dear SEO-savvy friends and enthusiasts! Today, I would like to talk about crawlability, the most common crawlability problems, and solutions to them. This vital factor can hurt your rankings, traffic, and website visibility in search results. Before diving into the crawl errors, let’s find out what crawlability is and how it affects SEO.

What is Crawlability?
In simple terms, crawlability refers to the ability of search engine bots to detect and crawl your website pages correctly. What concerns technical SEO, it is an important thing you should check out because if Googlebot can’t find your web pages, they will never rank at the top of search engine results.
Notice that crawlability and indexability are different things. The last one refers to the ability of search engines to correctly find the content they crawl and add it to their index. Google only shows crawlable and indexable web pages in search engine results.
To know how many pages on your website have been indexed, go to Google and type “site:” with the website URL. You can check out the example below but if you want everything to be done for you, welcome to outsourcing with us!
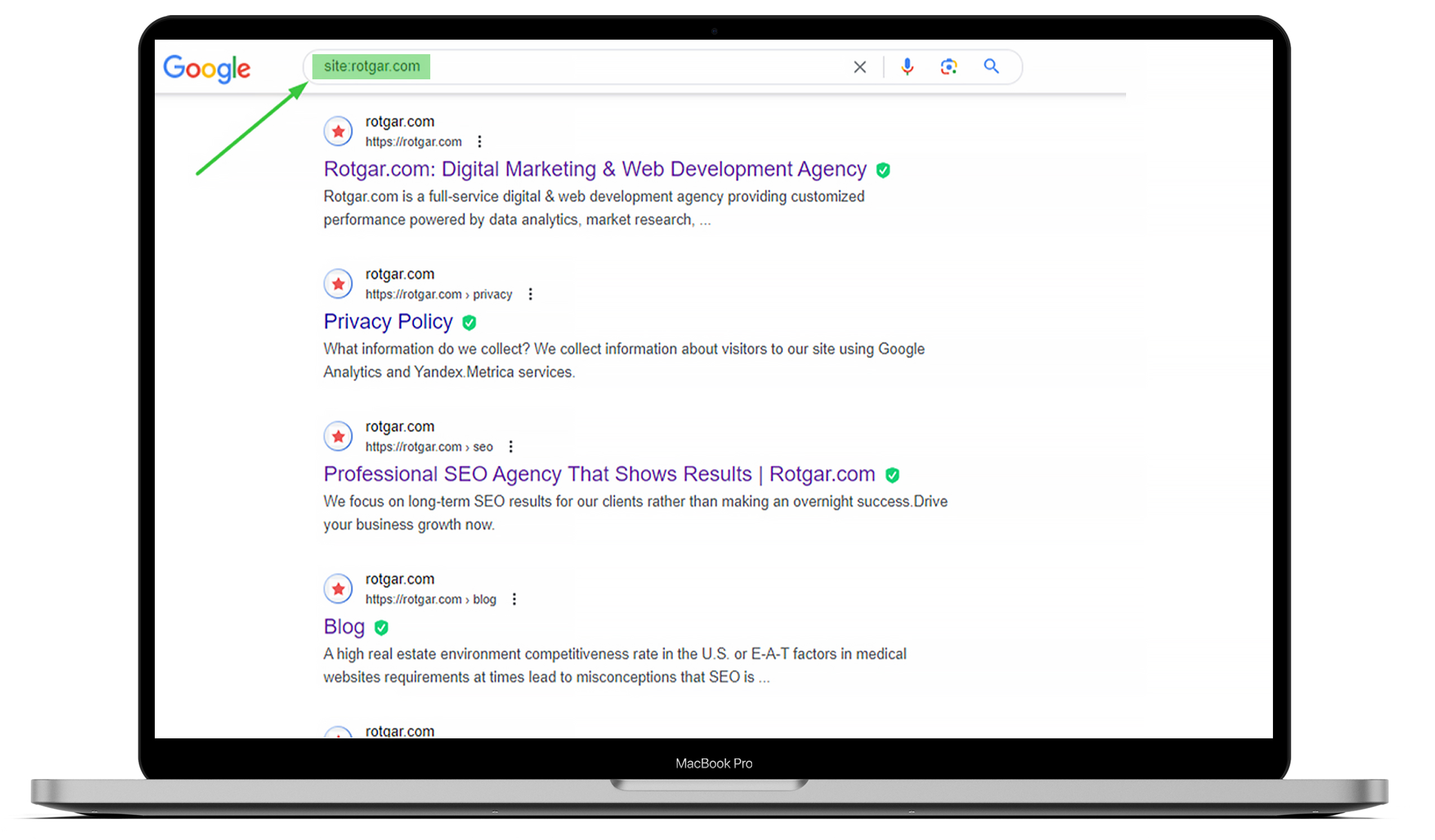
You should understand that search engine bots, also known as web crawlers, always work, scan the content, and index web pages they find. Once a Googlebot detects any change, it will update the data.
Many things can affect your website’s crawlability, but this article will explain the most common problems.
The Impact of Crawl Errors on SEO
If search engine bots face crawlability problems on your website, it can significantly influence your SEO. Your web pages won’t appear in search results if a Googlebot doesn’t know whether the content is relevant to a specific search term.
That means that they can’t index them, and it can result in a loss of conversions and organic traffic. That’s why it is essential to have crawlable and indexable pages to rank highly in search engines. In other words, the more crawlable your website is, the more likely your pages will index and rank better in Google.
How to Find Crawl Errors in Google Search Console
Now we know what crawlability and crawl errors are and how they affect your SEO. It’s time to find these errors from the dashboard quickly. As you may know, Google Search Console divides crawl errors into two sections: Site Errors and URL Errors. It is a great way to distinguish errors at the site and page levels.
Usually, Site Errors are considered more urgent and require instant action to prevent damage to your website’s usability. I recommend 100% error-free in this section.

URL errors sound less catastrophic and more specific to individual web pages as these mistakes only influence certain pages, not the overall website.
The best way to find your crawl errors is to go to the main dashboard, see the “Crawl” section and click “Crawl Errors.”

Ideally, you should check for crawl errors at least every three months to avoid serious problems and maintain your site’s health in the future
Top 10 Crawlability Problems and How To Fix Them
Now, let’s look at the most common crawlability problems and their solutions to optimize your site accordingly.
1. 404 Errors
–A 404 error is one of the most complex and simplest issues of all errors simultaneously.
–In theory, a 404 error refers to the ability of the Googlebot to crawl a specific page that doesn’t find on your website.
–In practice, you can see many pages as 404s in Google Search Console.
Here is what Google states:

“404 errors don’t hurt your site performance and rankings in Google a lot, so you can safely ignore them.”
Fixing 404 errors when your crucial web pages face these issues is essential. Make sure to distinguish between pages to avoid mistakes and find the problem’s root. The last one really matters, especially if the page gets important links from external sources and has much organic traffic on your site.
The solution
Here are some steps to fix important pages with 404 errors:
- Double-check whether the 404 error page is correct and got from your CMS but not in draft mode.
- Check out which version of your site the error appears on WWW vs. non-WWW and http vs. https.
- Add a 301 redirect to the most relevant page on your site if you don’t update the page.
- If your page is no longer alive, renovate it and make it live again.
To find all your 404 error pages in Google Search Console, go to Crawl Errors -> URL Errors and click all links you want to fix:

1. Notice:
if you have a custom 404 page that doesn’t return a 404 status, Google will note it as a soft 404. That means the page doesn’t have enough useful content for users and returns a 200 status. Technically, it exists but is empty, which decreases the performance of your site’s crawl.
Soft 404 errors can confuse website owners as they look like a strange hybrid of 404 and standard web pages. Ensure that Googleblog doesn’t consider your website’s most important pages as soft 404s.
2. Nofollow Links
It can be a confusing error for search engines not to crawl the links on a website page. The nofollow tag tells the Googlebot not to follow the links, which result in crawlability problems on your site. Here is what the tag looks like:
In most cases, these errors come from Google having trouble with Javascript, Flash, redirects, cookies, or frames. You shouldn’t worry about fixing the error until not followed issues on high-priority URLs. If they come from old URLs that aren’t active or non-indexed parameters that serve as an extra feature, priority will be lower — but you still need to review these errors.
The solution
Here are some steps to fix not followed issues:
● Review all the pages with the nofollow tags using the “Fetch as Google” tool to see the site as Googlebot would.
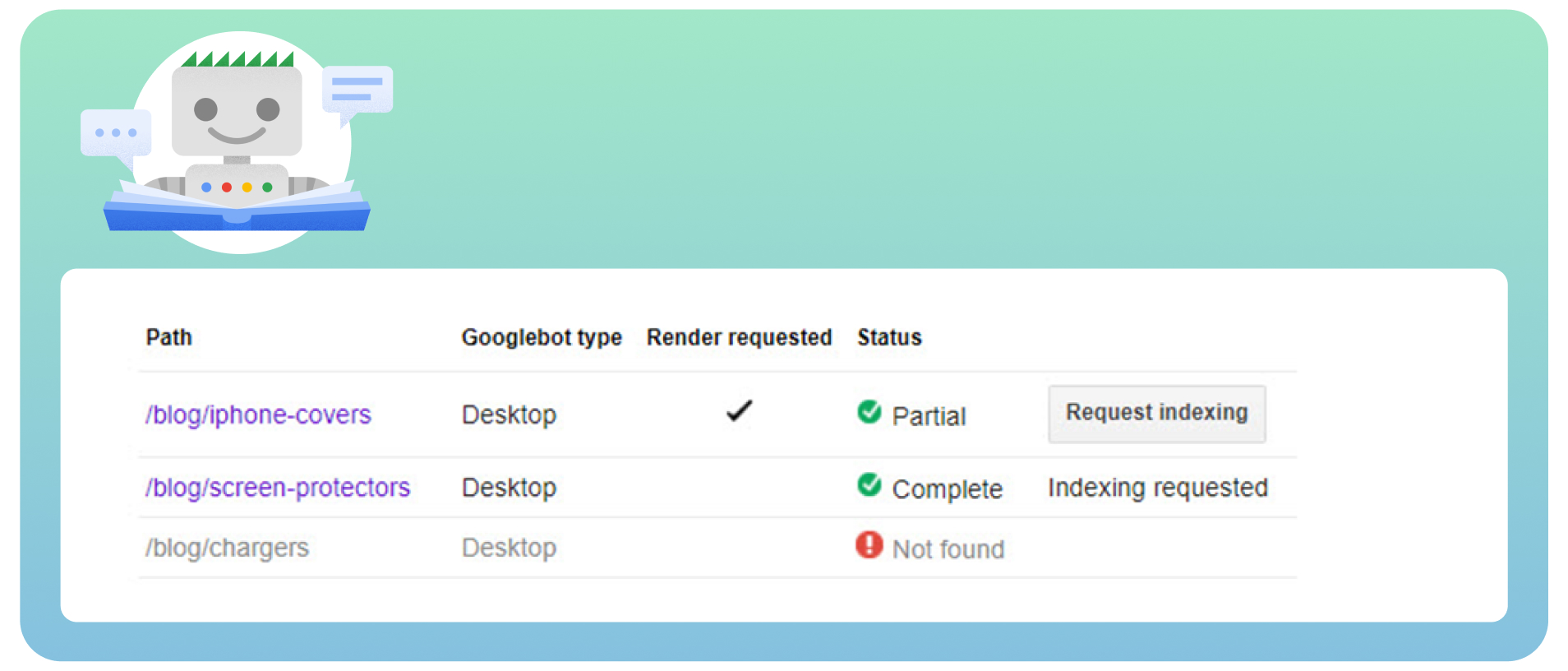
- Check for redirect chains. Google can stop following redirects if you have many loops.
- Include the destination URL, not redirected URLs, in the sitemap.
- Improve your site architecture to let each page on your site be reached from static links.
- Remove the nofollow tags from the pages where they shouldn’t be there.
3. Blocked Pages
When search engine bots crawl your website, they first check out your robots.txt file. Because it will direct and tell them what web pages they need and don’t need to crawl. Here is an example of the robots.txt file below that shows your website is blocked from crawling:
User-agent: *
Disallow: /
Unfortunately, it is one of the most common issues that affect your website’s crawlability and blocks crucial web pages from crawling. To fix this problem, you should change the directive in this file to “Allow,” which will allow search engine bots to crawl the overall website.
User-agent: *
Allow: /
If you create your own blog, opening it up for crawling and indexing is essential to get all the potential SEO benefits after transferring it to your main website. Just use the Disallow: /blog* directive in the example below:

Many website owners blog specific pages in this file when they want to avoid ranking them in search results. In most cases, this refers to login and thank you pages. But it’s not a crawlablity problem because you don’t want them to be visible in search engine results. Finding a typo or a mistake in regex code will result in more severe issues on your site.
The solution
If you want to make your page crawlable, ensure to allow it in the robot.txt. Check your file using the robots.txt tester to find any issues and warnings and test specific URLs in your file.
You can also find any robots.txt errors using a website audit. Fortunately, there are many valuable tools to conduct a technical SEO audit, like Screaming Frog or Semrush. But first, you should register and add your site to get results.
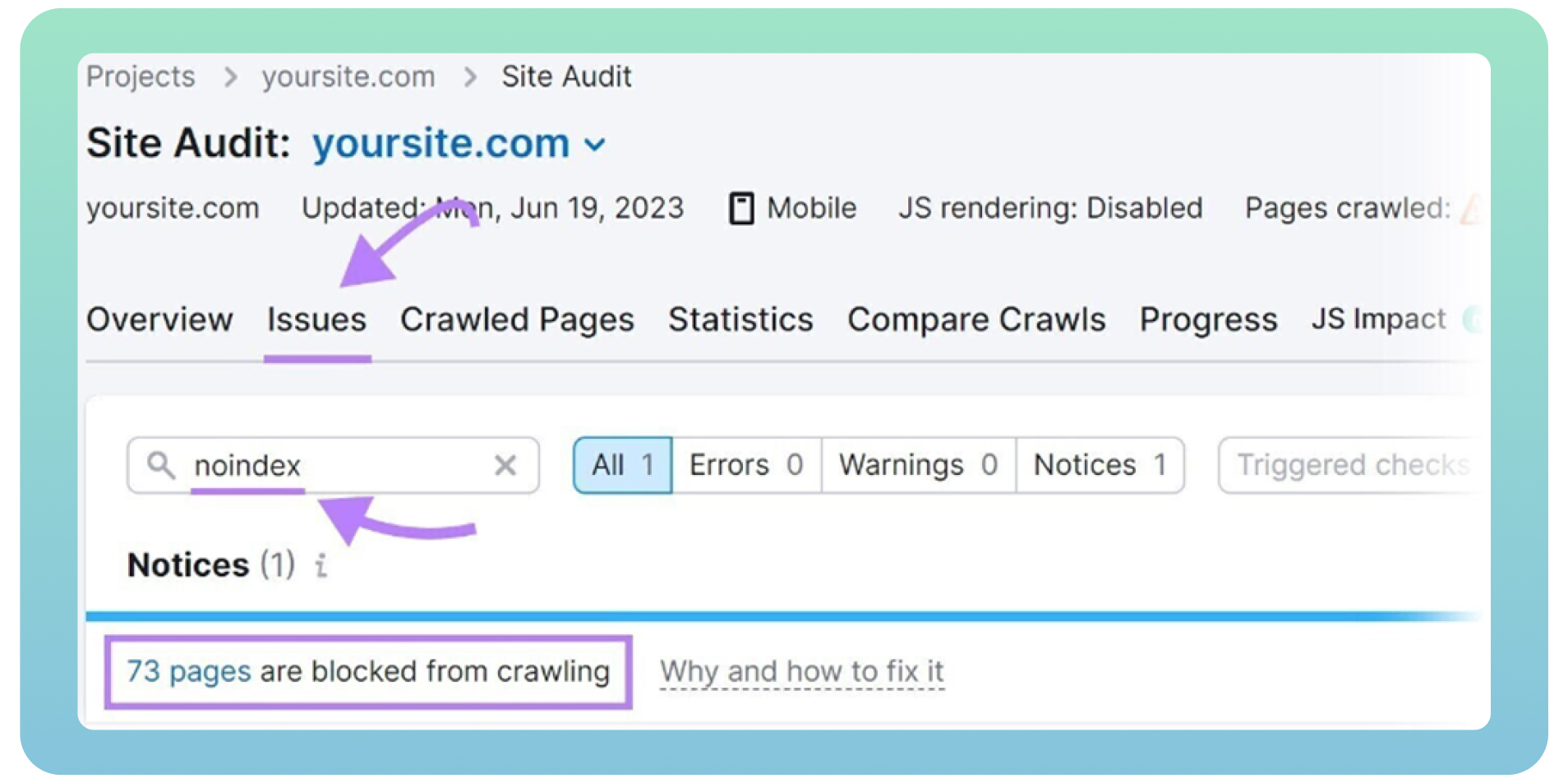
4. ‘Noidex’ Tags
“Noindex” tags tell search engines which pages they don’t need to index. Here is what the tag looks like below:
Having “noindex” tags on your website can affect its crawlability and indexability on search engines if you leave it on your web pages for a long time. When launching it live, web developers often forget to delete the “noindex” tag from the website.
Google regards “noindex” tags as “nofollow” and stops crawling the links on those pages. It is common practice to include a “noindex” tag on thank you, login, and admin pages to prevent Google from indexing. In other cases, it is time to remove these tags if you want search engine bots to crawl your pages.
The solution
Here are some steps to fix “noindex” issues:
● Analyze your crawl stats in Google Search Console to determine how frequently the Googlebot visits your website.
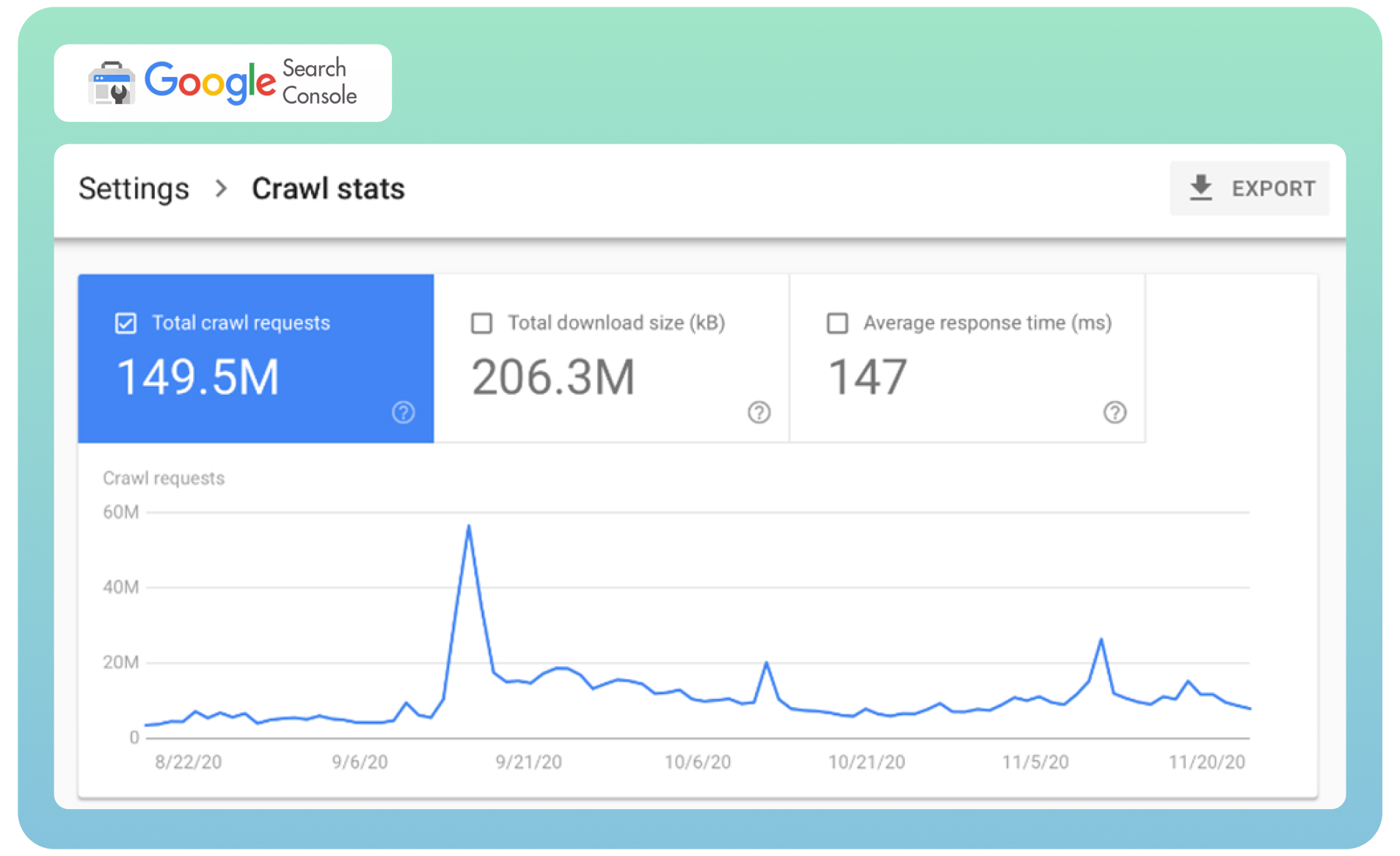
- Request Google to recrawl your page using the Removals tool to remove the already indexed page from SERPs instantly. It can take some time to do that.
- Use a website audit tool like Semrush to detect pages with “noindex” tags. It will show a list of pages on your site, review them, and remove them where needed
5. Page Duplicates
Often different web pages with the same content can be loaded from different URLs, which results in page duplication. For example, you have two versions of your domain (www and non-www) leading to your site’s homepage. These pages don’t affect your website visitors, but they can affect the perception of your website by search engines.
The worst thing is that search engines can’t identify which page to consider as a top priority due to duplicate content. The Googlebot crawls each page quickly and will index the same content again.
Ideally, the bot should crawl and index every page just once. Moreover, different versions of the same page get organic traffic and page rank, making analyzing traffic metrics in Google Analytics complicated.

The Solution
Canonicalization is the most preferred way for duplicates to keep SEO authority. Here are some tips to consider:
● Use canonical tags to tell Google easily detect the original URL of a page. Here is how the link with this tag should look like below:
● Check the alerts in Google Search Console — it can be something like “Too Many URLs” or similar language when Google encounters more URLs and content than it should be.
● Don’t use canonical and noindex tags simultaneously, as search engine bots can regard noindex canonical web pages and duplicates.
● Canonicalize to the “View All” page.
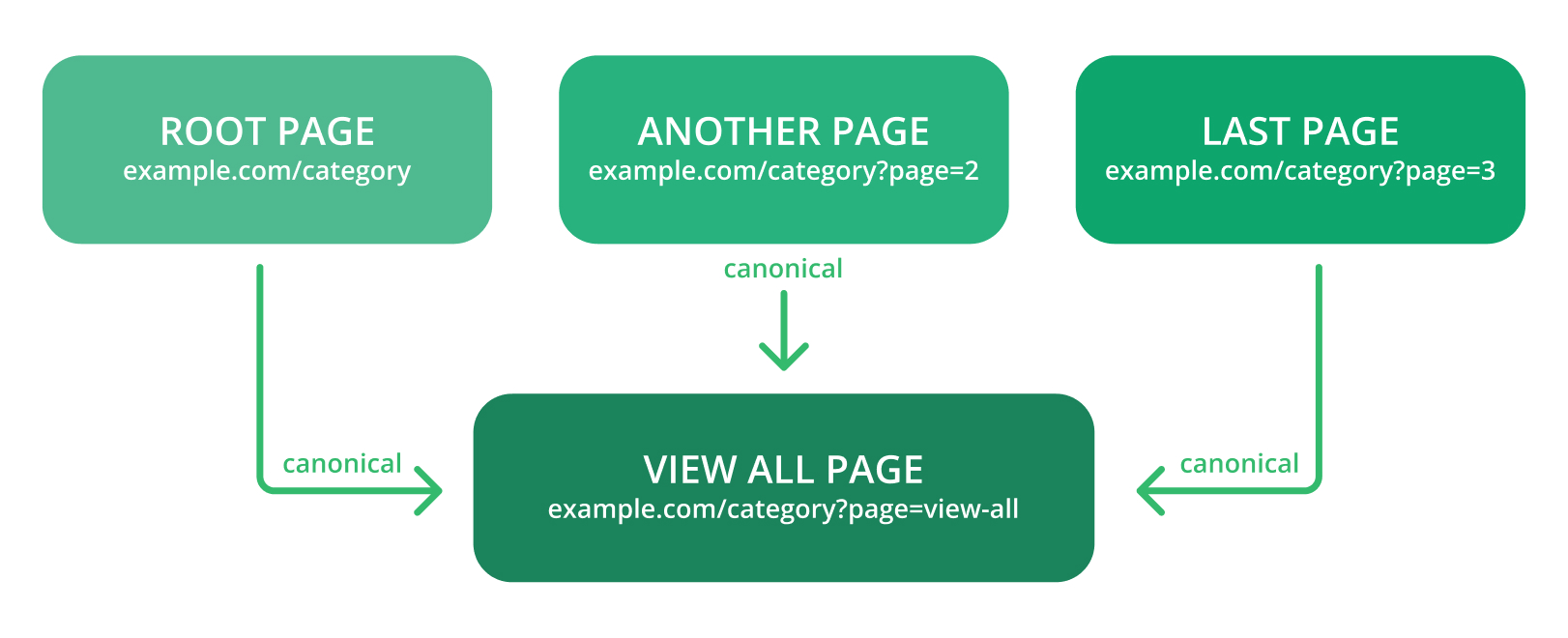
● Canonicalize every URL created by faceted navigation
6. Slow Load Speed
Page load speed is one of the most critical factors that affect the crawlability of your website. Slow load speed can create a poor user experience and reduce the number of pages search engine bots can crawl within a crawl session. That can result in the exclusion of crucial web pages from crawling.
In simple words, the quicker your web pages load, the faster the Googlebot can crawl the content on the site and better rank in search results. That’s why improving the overall website performance and speed is essential.
The Solution
Here are some useful tips you should consider while optimizing site speed:
● Use Google PageSpeed Insights to measure your current load times, detect possible errors, and get actionable tips for improving site performance.

- Use a content delivery network (CDN) to redirect your content across different servers worldwide. It will reduce latency and make your website work faster.
- Choose a fast web hosting provider.
- Compress images and video file sizes to increase loading speed.
- Remove unnecessary plugins and reduce the number of CSS and JacaScript files on your site.
7. Lack of Internal Links
Web pages with a lack of internal links can meet crawlability problems. Internal links refer to linking one page to another relevant page within the same domain. They help users easily navigate within your website and provide search engines with helpful information about your structure and hierarchy.

Each page on your site should have at least one internal link leading to it. That will show search engines that your pages are interrelated and connected. Isolated pages make it difficult for bots to consider them part of your site. The more relevant internal links you have, the easier and faster the bots crawl the entire website.
The Solution
Here are some actionable tips to consider:
● Conduct an SEO audit to determine where to add more internal links from relevant pages on your site.
● See the website’s analytics to view how users are flowing through the site and find ways to engage them with your relevant content. Look out for pages with high bounce rates to improve them and add more quality content.
- Prioritize crucial pages by putting them higher in the website hierarchy and adding more internal links leading to them.
- Include descriptive anchor texts to show the content of the linked pages.
- Update your old URLs or remove broken links. Ensure that every connection is relevant and active on your site.
- Double-check and remove any typos in the URL you include on your web pages.
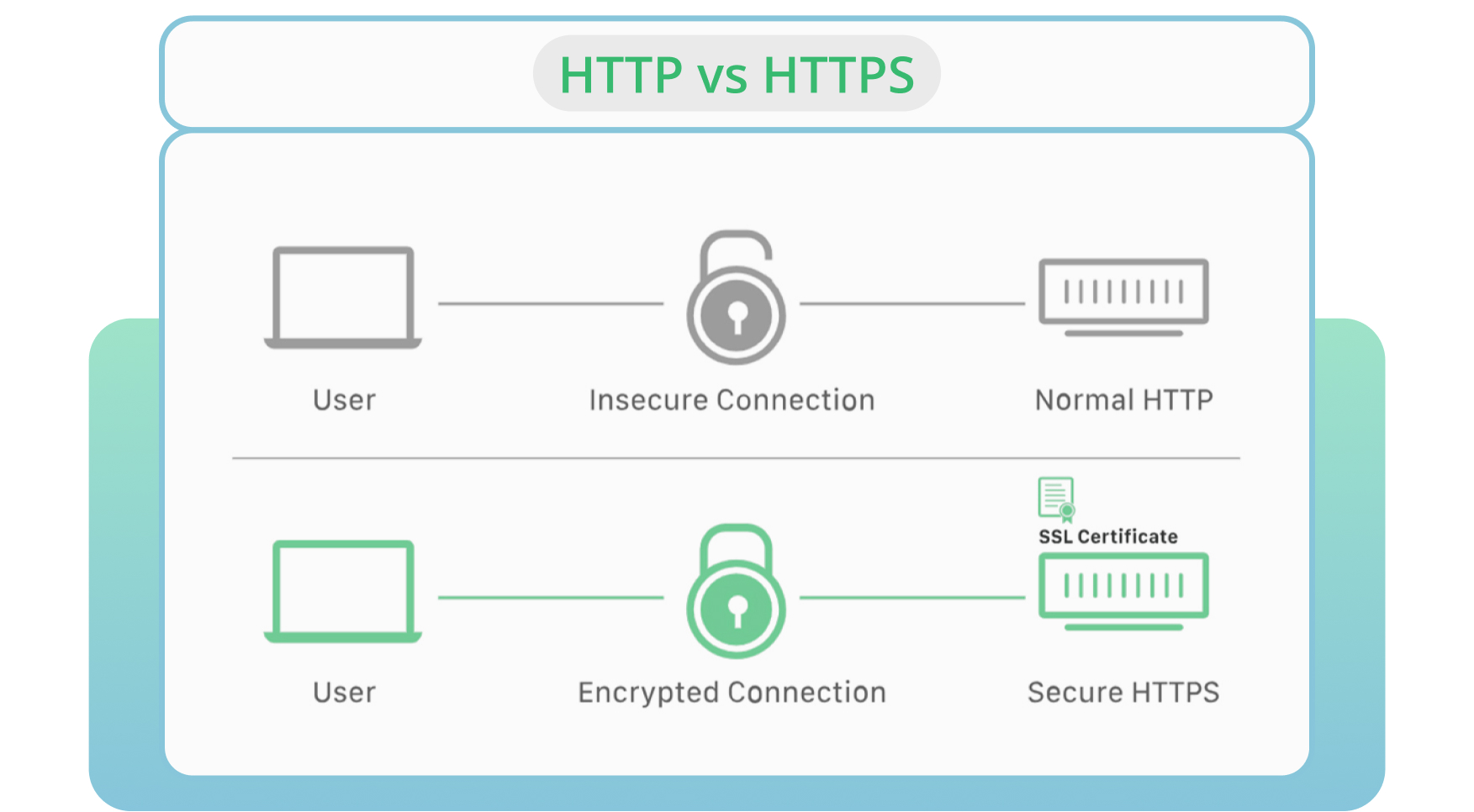
8. Using HTTP Instead of HTTPS
Server security remains one of the primary factors in crawling and indexing. HTTP is the standard protocol that transmits data from a web server to a browser. HTTPS is considered the most secure alternative to the HTTP version.
In most cases, browsers prefer HTTPS pages instead of HTTP ones. The last one negatively affects site rankings and crawlability.
The Solution
- Get an SSL certificate to help Google quickly crawl your website and maintain a safe and encrypted connection between your website and users.
- Turn your website on to the HTTPS version.
- Monitor and update security protocols. Avoid expired SSL certificates, old protocol versions, or incorrectly registering your website information.
9. Redirect Loops
Redirects are essential when you need to direct your old URL to a new, relevant page. Unfortunately, redirect issues, like redirect loops, can often happen. That can upset users and stop search engines from crawling your pages.

A redirect loop is when one URL redirects to another, returning to the original URL. This issue forms search engines with an infinite cycle of redirects between two or more pages. It can affect your crawl budget and crawling of your important pages.

The Solution
Here are some steps to fix redirect loops:
● Use HTTP Status Checker to find redirect chains and HTTP status codes quickly.

- Choose the “correct” page and redirect other pages to it.
- Delete the redirect causing the loop.
- Mark the pages with a 403 status code as nofollow to optimize your crawl budget. These pages can be used for registered users only.
- Include temporary redirects to tell search engine bots to return to your page. Use a permanent redirect if you no longer want to index the original page.
10. Poor Site Architecture
Organizing your website’s pages and content is one of the most critical factors when optimizing crawlability. A poor site architecture will create crawl errors for web crawlers to discover web pages that are low in the hierarchy or not linked (known as “orphan pages”).
A well-structured site can help search engines easily find and access all pages that can positively affect your performance and SEO. An ideal site structure means reaching every page just a few clicks away from the homepage without orphan pages.
For example, a typical site structure can look like a pyramid. You have the homepage at the top, with several layers referring to the main topic pages leading to sub-topic pages. Notice the example site structure below.

Google usually crawls the website from the top of the homepage to the bottom. In other words, the further your pages are from the top, the more complex search engine bots will find them, especially if you have a lot of orphan pages.
The Solution
Here are some steps to optimize your site architecture:
Use Screaming Frog to check out your current site structure and crawl depth.
Organize your pages logically in a hierarchy with internal links. Make your crucial pages with two or three clicks from the homepage.
● Create a clear URL structure. Make it easy to read for search engines and users to understand the context and relevance of each page on your site. Include target keywords in each URL where possible.
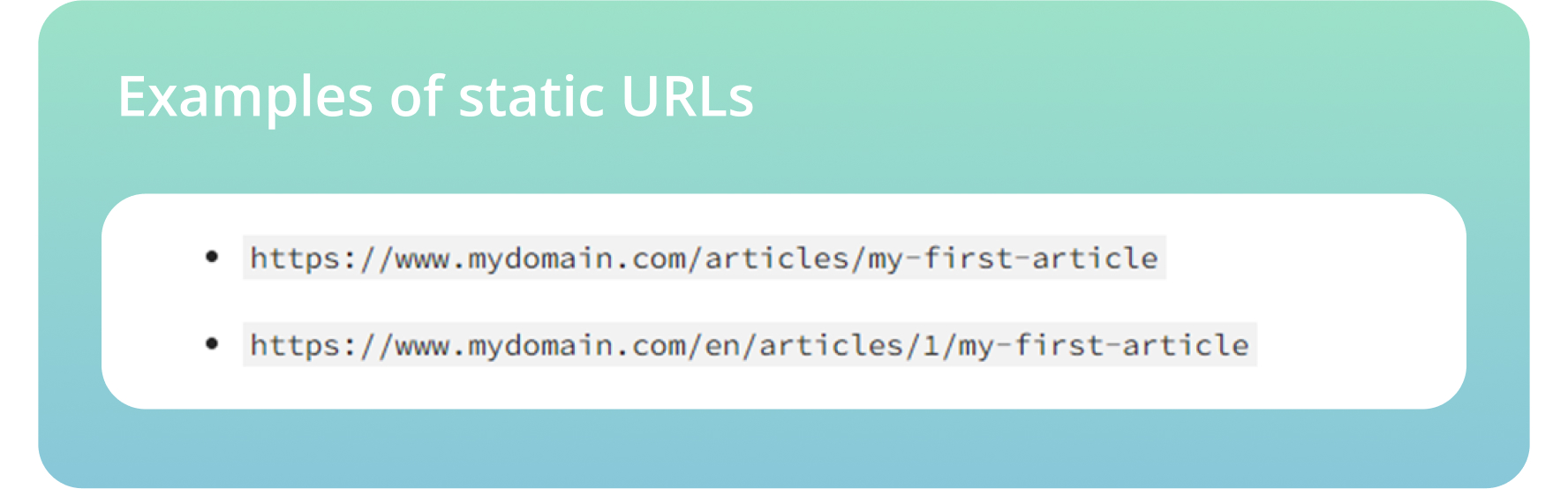
● Use static URLs and avoid using dynamic ones, including session IDs or other URL parameters that make it difficult for bots to crawl and index.
● Create breadcrumbs to help Google understand your sites and people move forward and backward quickly.

11. Bad Sitemap Management
Sitemaps refer to XML files with important information about your site’s pages. They tell search engines which pages are important on the site you want to crawl and index. Sitemaps also contain information about your site’s images, videos, and other media files. Here is an example of a sitemap below:
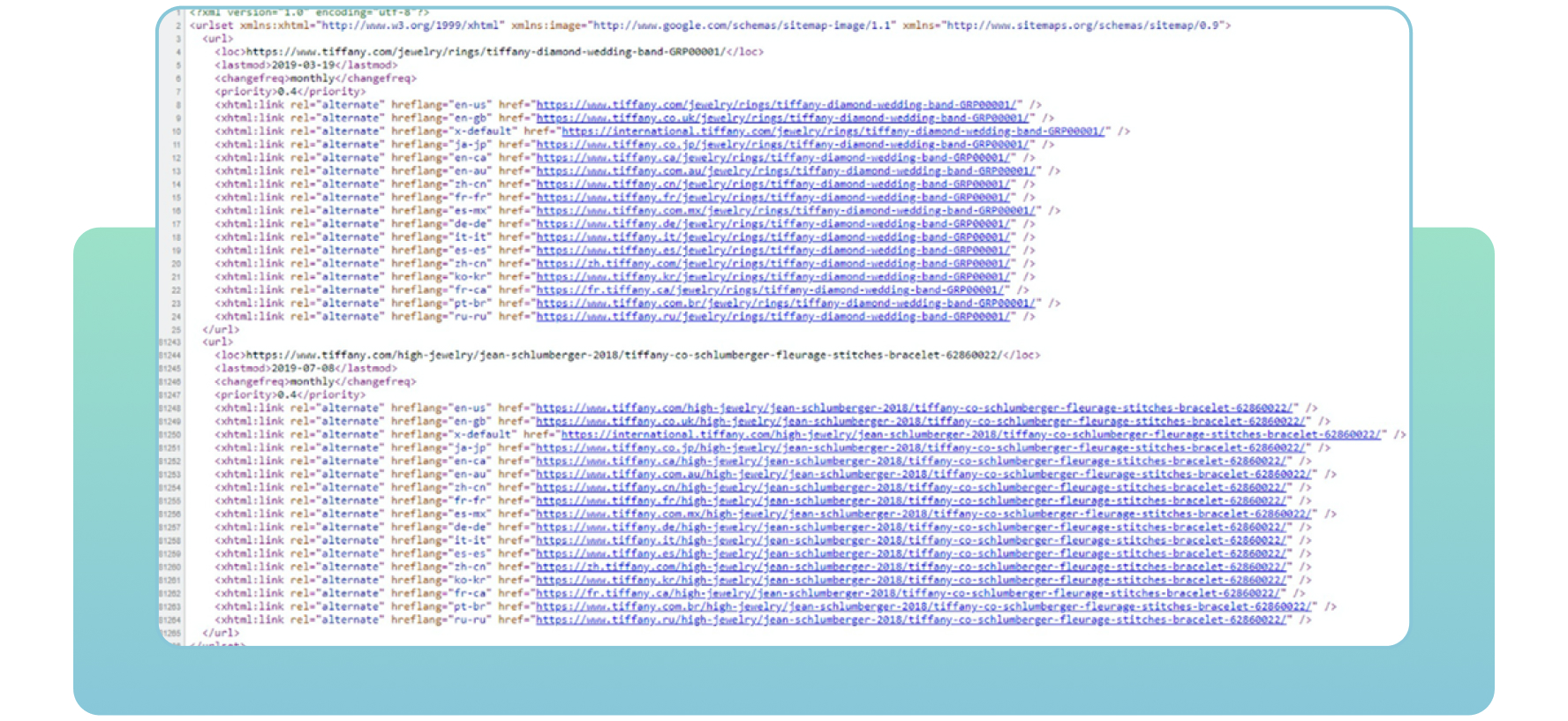
With sitemaps, search engines will find and crawl your essential web pages effectively. If you don’t include some pages you want to index and rank, search engines mightn’t notice them, resulting in crawlability issues and lower site traffic.
The Solution
Here are some steps to consider regarding sitemaps:
- Use the XML Sitemaps tool to create or update a sitemap.
- Ensure that all necessary pages are included within it and there are no server errors that can make it difficult for web crawlers to access.
- Submit your sitemap to Google. You can usually find it by following the URL of your site depicted below: domain.com/sitemap.xml
- Use Google Search Console to monitor the status of your sitemap and check out any issues about it.
● Ensure to update your sitemap once new pages are added or deleted from your website. That will help search engines get accurate information about all your web pages.
Conclusion
There are many reasons why some of your pages are hidden from Google and don’t rank at all. First, consider whether your site is free of any crawlability problems
Many crawl errors can affect your website performance and tell search engine bots that certain web pages aren’t worth crawling. As a result, Google won’t index and rank your crucial pages they can’t access.
That is why it’s essential to find any crawlability problems and do your best to fix them. By implementing the solutions mentioned earlier, you can optimize your site for better performance and help search engines and users easily find it.
Dear friends! I hope the article turned out to be interesting, and I would be very happy if it benefits you. See you soon!




