
Qu’est-ce que la Crawlabilité : 11 façons de corriger les erreurs de Crawl
Bonjour, chers amis et passionnés de SEO ! Aujourd’hui, j’aimerais vous parler de la crawlabilité, des problèmes de crawlabilité les plus courants et des solutions pour y remédier. Ce facteur vital peut nuire à votre classement, à votre trafic et à la visibilité de votre site Web dans les résultats de recherche. Avant de plonger dans les erreurs de crawl, découvrons ce qu’est la crawlabilité et comment elle affecte le référencement.

Qu’est-ce que la crawlabilité ?
En termes simples, la crawlabilité fait référence à la capacité des robots des moteurs de recherche à détecter et à parcourir correctement les pages de votre site web. En ce qui concerne le référencement technique, il s’agit d’un élément important que vous devez vérifier, car si Googlebot ne peut pas trouver vos pages web, elles ne seront jamais classées en tête des résultats des moteurs de recherche.
Notez que la navigabilité et l’indexabilité sont deux choses différentes. Cette dernière fait référence à la capacité des moteurs de recherche à trouver correctement le contenu qu’ils explorent et à l’ajouter à leur index. Google n’affiche dans les résultats des moteurs de recherche que les pages web qui peuvent être explorées et indexées.
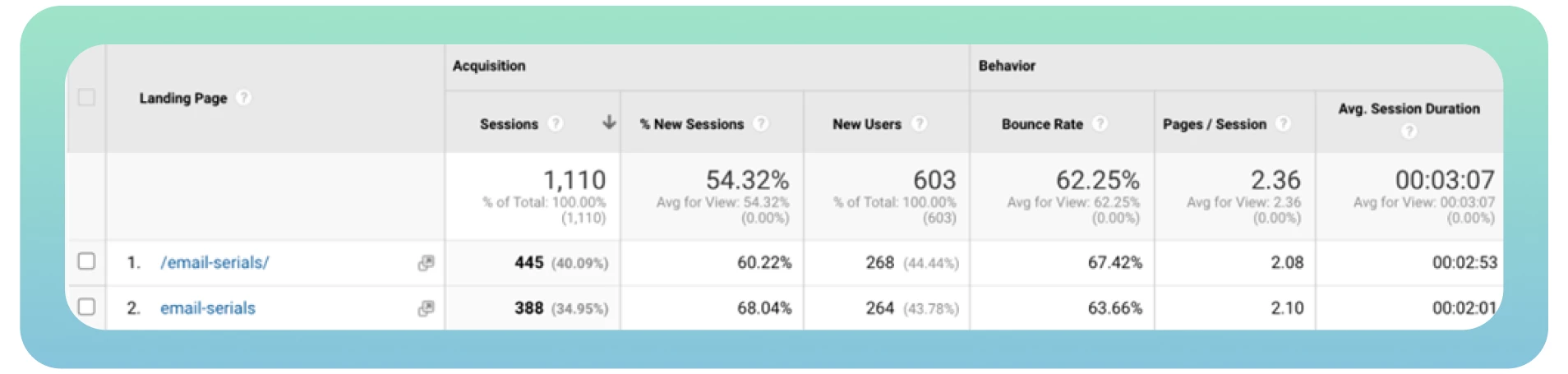
Pour savoir combien de pages de votre site web ont été indexées, allez sur Google et tapez « site : » avec l’URL du site. Vous pouvez consulter l’exemple ci-dessous, mais si vous souhaitez que tout soit fait pour vous, nous vous invitons à sous-traiter avec nous !
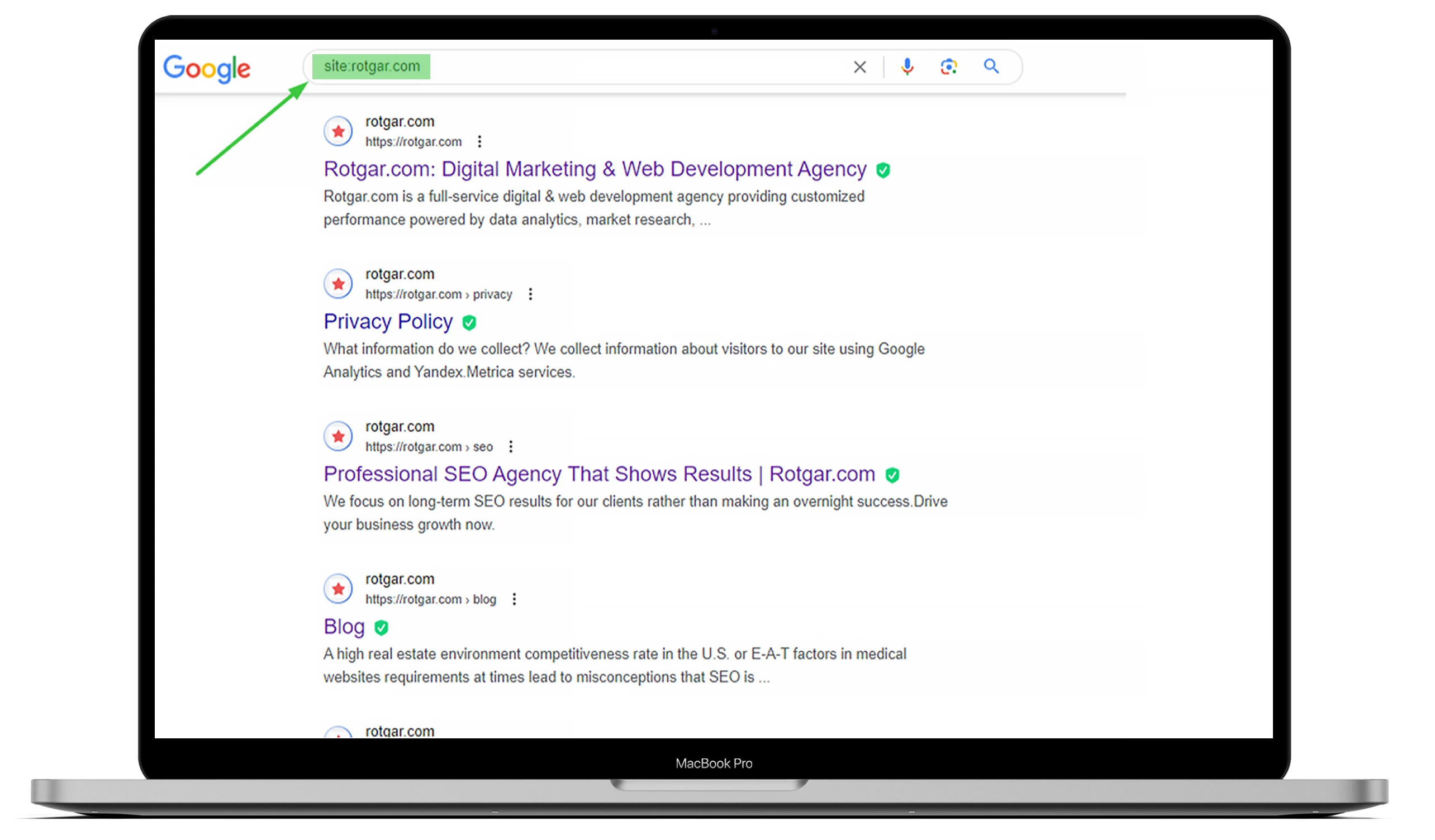
Vous devez comprendre que les robots des moteurs de recherche, également connus sous le nom de « web crawlers », travaillent toujours, analysent le contenu et indexent les pages web qu’ils trouvent. Dès qu’un Googlebot détecte un changement, il met à jour les données.
De nombreux éléments peuvent affecter la navigabilité de votre site web, mais cet article explique les problèmes les plus courants.
L’impact des erreurs de crawl sur le référencement
Si les robots des moteurs de recherche rencontrent des problèmes d’indexation sur votre site web, cela peut avoir une incidence considérable sur votre référencement. Vos pages web n’apparaîtront pas dans les résultats de recherche si un Googlebot ne sait pas si le contenu est pertinent par rapport à un terme de recherche spécifique.
Cela signifie qu’il ne peut pas les indexer, ce qui peut entraîner une perte de conversions et de trafic organique. C’est pourquoi il est essentiel d’avoir des pages accessibles et indexables pour obtenir un bon classement dans les moteurs de recherche. En d’autres termes, plus votre site web est crawlable, plus vos pages sont susceptibles d’être indexées et mieux classées dans Google.
Comment trouver les erreurs d’indexation dans Google Search Console ?
Nous savons maintenant ce que sont la crawlabilité et les erreurs de crawl, et comment elles affectent votre référencement. Il est temps de trouver rapidement ces erreurs à partir du tableau de bord. Comme vous le savez peut-être, Google Search Console divise les erreurs de crawl en deux sections : Erreurs de site et Erreurs d’URL. C’est un excellent moyen de distinguer les erreurs au niveau du site et de la page.
En général, les erreurs de site sont considérées comme plus urgentes et nécessitent une action immédiate pour éviter de nuire à la convivialité de votre site web. Je recommande un taux d’absence d’erreurs de 100 % dans cette section.
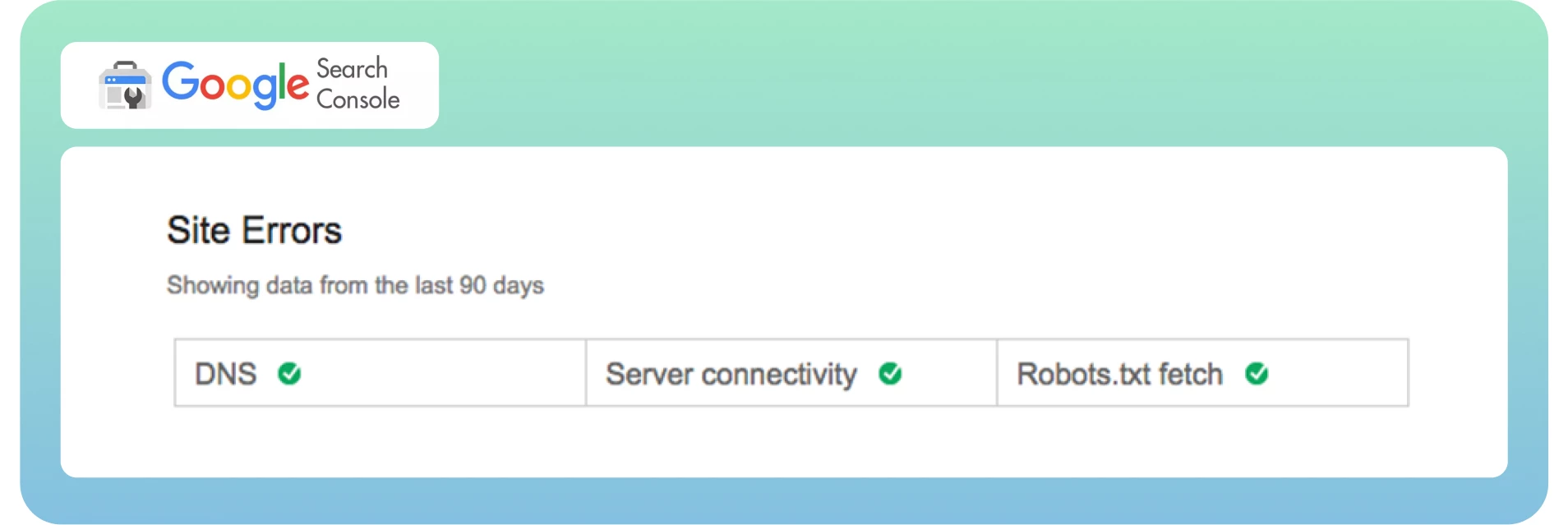
Les erreurs d’URL sont moins catastrophiques et plus spécifiques aux pages web individuelles, car elles n’influencent que certaines pages, et non l’ensemble du site web.
La meilleure façon de trouver vos erreurs de crawl est d’aller dans le tableau de bord principal, de voir la section « Crawl » et de cliquer sur « Crawl Errors ».
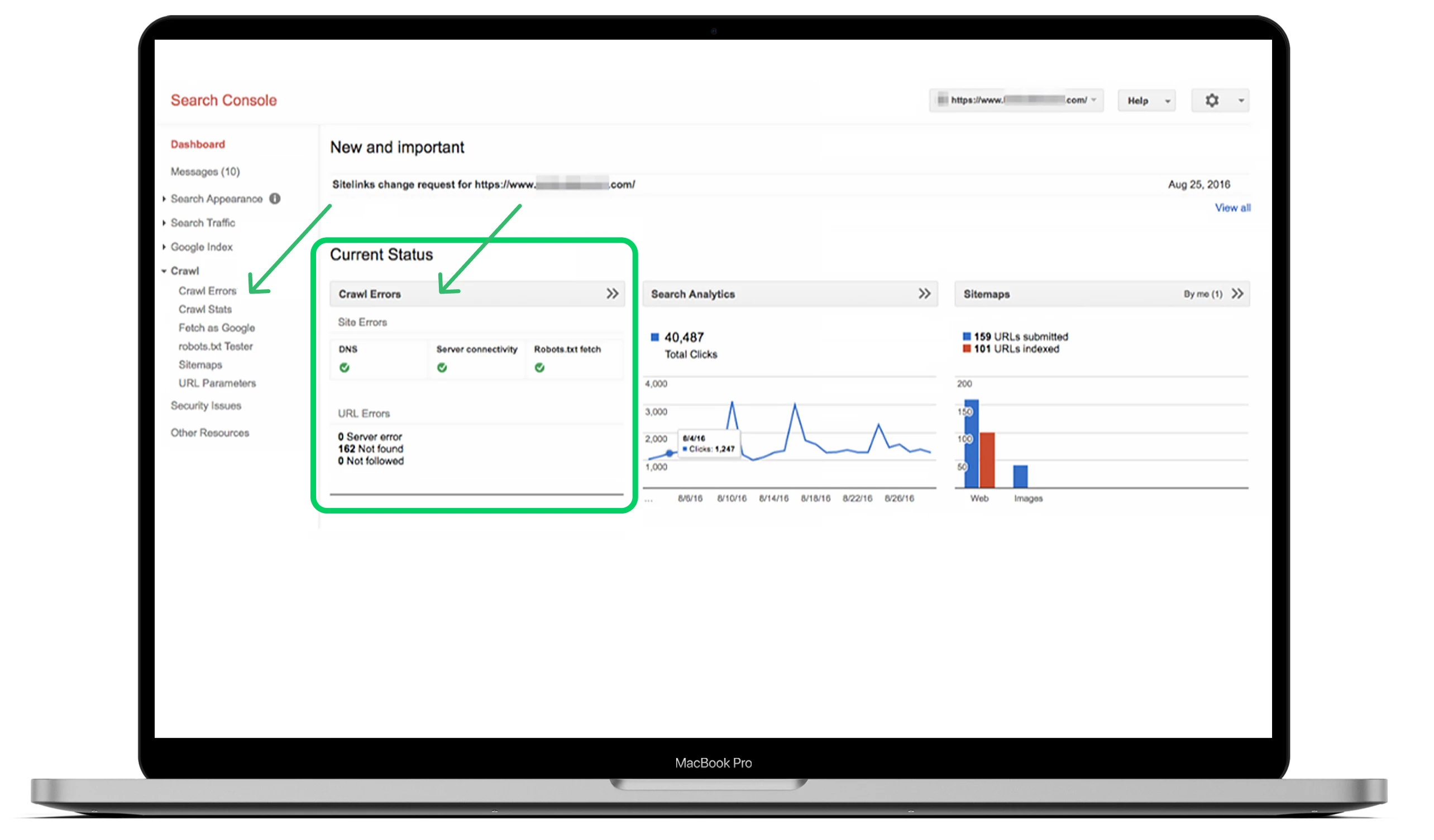
Idéalement, vous devriez vérifier les erreurs de crawl au moins tous les trois mois pour éviter les problèmes graves et maintenir la santé de votre site à l’avenir
Les 10 principaux problèmes de crawlabilité et comment les résoudre
Examinons maintenant les problèmes de crawlabilité les plus courants et leurs solutions afin d’optimiser votre site en conséquence.
1. Erreurs 404
-Une erreur 404 est l’un des problèmes les plus complexes et les plus simples de toutes les erreurs à la fois.
-En théorie, une erreur 404 fait référence à la capacité du Googlebot à explorer une page spécifique qui ne se trouve pas sur votre site web.
-En pratique, vous pouvez voir de nombreuses pages comme 404 dans Google Search Console.
Voici ce que dit Google :

« Les erreurs 404 ne nuisent pas beaucoup aux performances de votre site et à son classement dans Google, vous pouvez donc les ignorer en toute sécurité. »
Il est essentiel de corriger les erreurs 404 lorsque vos pages web cruciales sont confrontées à ces problèmes. Veillez à faire la distinction entre les pages pour éviter les erreurs et trouver l’origine du problème. Ce dernier point est très important, surtout si la page reçoit des liens importants de sources externes et que le trafic organique sur votre site est important.
La solution
Voici quelques étapes pour corriger les pages importantes contenant des erreurs 404 :
Vérifiez que la page d’erreur 404 est correcte et qu’elle provient de votre CMS, mais qu’elle n’est pas en mode brouillon.
Vérifiez la version de votre site sur laquelle l’erreur apparaît : WWW ou non, http ou https.
Ajoutez une redirection 301 vers la page la plus pertinente de votre site si vous ne mettez pas la page à jour.
Si votre page n’est plus vivante, rénovez-la et redonnez-lui vie.
Pour trouver toutes vos pages d’erreur 404 dans Google Search Console, allez dans Crawl Errors -> URL Errors et cliquez sur tous les liens que vous souhaitez corriger :
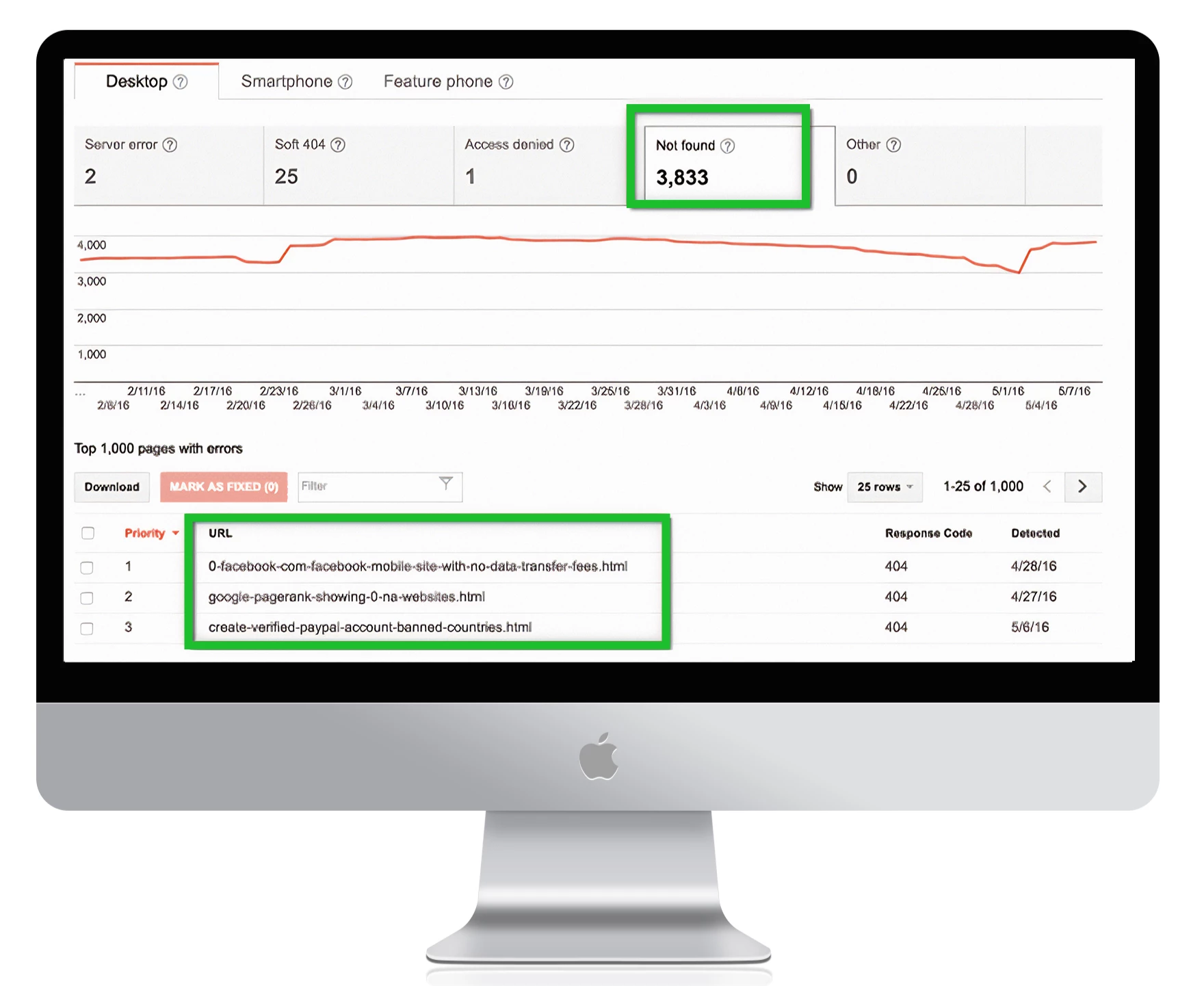
1. Remarque :
si vous avez une page 404 personnalisée qui ne renvoie pas d’état 404, Google la notera comme un soft 404. Cela signifie que la page ne contient pas suffisamment de contenu utile pour les utilisateurs et renvoie un statut 200. Techniquement, la page existe, mais elle est vide, ce qui réduit les performances de l’exploration de votre site.
Les erreurs Soft 404 peuvent dérouter les propriétaires de sites web, car elles ressemblent à un étrange hybride de 404 et de pages web standard. Assurez-vous que Googleblog ne considère pas les pages les plus importantes de votre site web comme des soft 404.
2. Liens en nofollow
Les moteurs de recherche peuvent commettre une erreur déroutante en ne parcourant pas les liens d’une page web. La balise nofollow indique au Googlebot de ne pas suivre les liens, ce qui entraîne des problèmes d’indexation sur votre site. Voici à quoi ressemble cette balise :
<meta name= »robots » content= »nofollow ».
Dans la plupart des cas, ces erreurs sont dues au fait que Google a des problèmes avec Javascript, Flash, les redirections, les cookies ou les cadres. Vous ne devriez pas vous préoccuper de corriger l’erreur tant que les problèmes ne sont pas suivis sur les URL prioritaires. Si elles proviennent d’anciennes URL qui ne sont pas actives ou de paramètres non indexés qui servent de fonction supplémentaire, la priorité sera moindre – mais vous devez tout de même examiner ces erreurs.
La solution
Voici quelques étapes pour résoudre les problèmes de non suivi :
● Passez en revue toutes les pages comportant les balises nofollow à l’aide de l’outil « Fetch as Google » pour voir le site comme le ferait Googlebot.
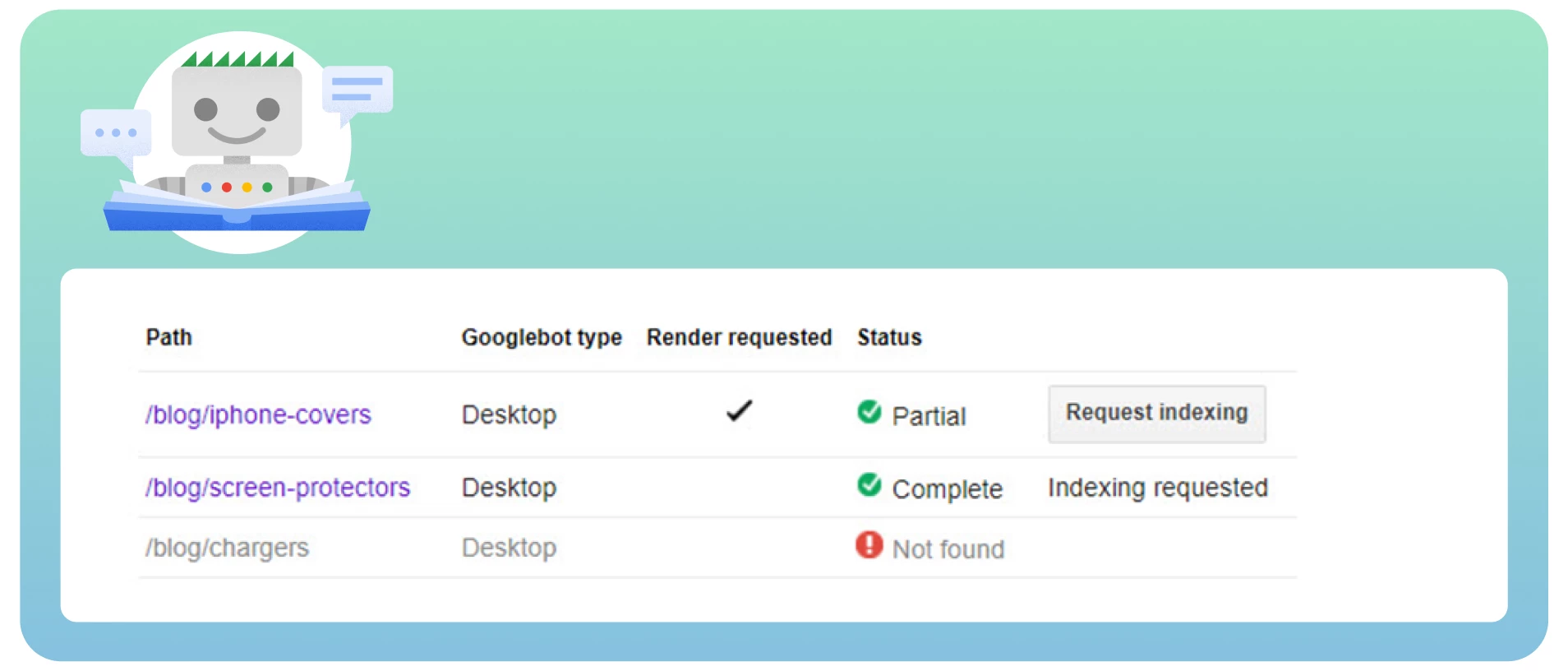
Vérifiez les chaînes de redirection. Google peut cesser de suivre les redirections si vous avez de nombreuses boucles.
Incluez l’URL de destination, et non les URL redirigées, dans le sitemap.
Améliorez l’architecture de votre site pour que chaque page de votre site soit accessible à partir de liens statiques.
Supprimez les balises nofollow des pages où elles ne devraient pas se trouver.
3. Pages bloquées
Lorsque les robots des moteurs de recherche parcourent votre site web, ils consultent d’abord votre fichier robots.txt. En effet, ce fichier leur indique les pages web qu’ils doivent ou ne doivent pas explorer. Voici un exemple de fichier robots.txt qui montre que votre site web est bloqué :
User-agent : *
Disallow : /
Malheureusement, il s’agit de l’un des problèmes les plus courants qui affectent l’indexation de votre site web et qui bloquent l’indexation de pages web cruciales. Pour résoudre ce problème, vous devez remplacer la directive de ce fichier par « Allow », ce qui permettra aux robots des moteurs de recherche d’explorer l’ensemble du site web.
User-agent : *
Allow : /
Si vous créez votre propre blog, il est essentiel de l’ouvrir à l’exploration et à l’indexation pour bénéficier de tous les avantages potentiels en matière de référencement après l’avoir transféré sur votre site web principal. Il vous suffit d’utiliser la directive Disallow : /blog* dans l’exemple ci-dessous :
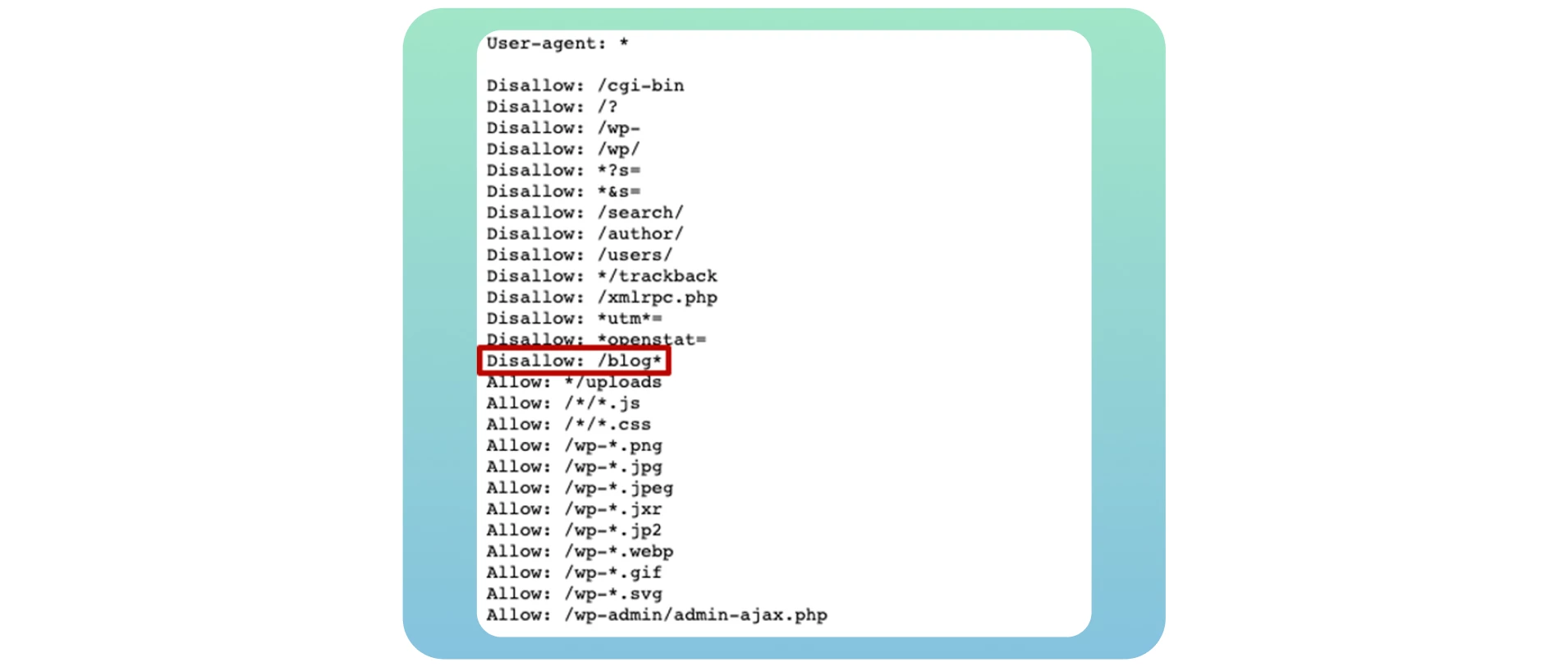
De nombreux propriétaires de sites web bloquent des pages spécifiques dans ce fichier lorsqu’ils veulent éviter de les classer dans les résultats de recherche. Dans la plupart des cas, il s’agit des pages de connexion et de remerciement. Mais il ne s’agit pas d’un problème de crawlablity car vous ne voulez pas qu’elles soient visibles dans les résultats des moteurs de recherche. La découverte d’une coquille ou d’une erreur dans le code regex entraînera des problèmes plus graves sur votre site.
La solution
Si vous voulez rendre votre page crawlable, assurez-vous de l’autoriser dans le fichier robots.txt. Vérifiez votre fichier à l’aide du testeur robots.txt afin de détecter tout problème ou avertissement et testez des URL spécifiques dans votre fichier.
Vous pouvez également trouver des erreurs dans le fichier robots.txt à l’aide d’un audit de site web. Heureusement, il existe de nombreux outils précieux pour réaliser un audit technique de référencement, comme Screaming Frog ou Semrush. Mais avant tout, vous devez vous inscrire et ajouter votre site pour obtenir des résultats.
4. Balises « Noidex
Les balises « Noindex » indiquent aux moteurs de recherche les pages qu’ils n’ont pas besoin d’indexer. Voici à quoi ressemble la balise ci-dessous :
<meta name= »robots » content= »nodiex ».
La présence de balises « noindex » sur votre site web peut nuire à sa navigabilité et à son indexation par les moteurs de recherche si vous les laissez sur vos pages web pendant une longue période. Lors de la mise en ligne, les développeurs web oublient souvent de supprimer la balise « noindex » du site web.
Google considère les balises « noindex » comme des balises « nofollow » et cesse d’explorer les liens sur ces pages. Il est courant d’inclure une balise « noindex » dans les pages de remerciement, de connexion et d’administration afin d’empêcher Google de les indexer. Dans d’autres cas, il est temps de supprimer ces balises si vous souhaitez que les robots des moteurs de recherche explorent vos pages.
La solution
Voici quelques étapes pour résoudre les problèmes de « noindex » :
● Analysez vos statistiques d’exploration dans Google Search Console pour déterminer la fréquence à laquelle le Googlebot visite votre site web.
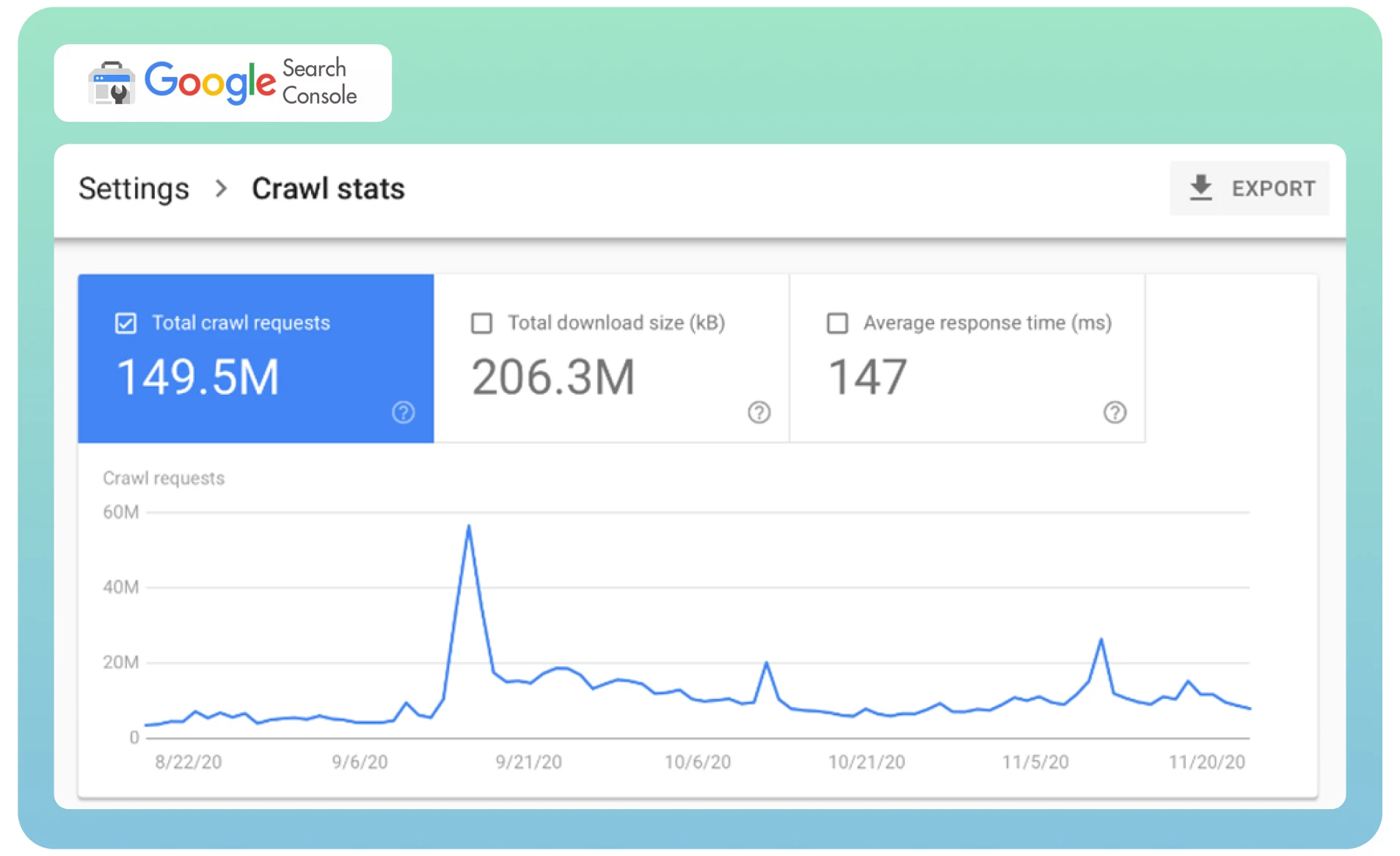
Demandez à Google de recrawler votre page à l’aide de l’outil Suppressions afin de supprimer instantanément la page déjà indexée des SERPs. Cela peut prendre un certain temps.
Utilisez un outil d’audit de site web tel que Semrush pour détecter les pages comportant des balises « noindex ». Il affichera une liste des pages de votre site, les examinera et les supprimera si nécessaire.
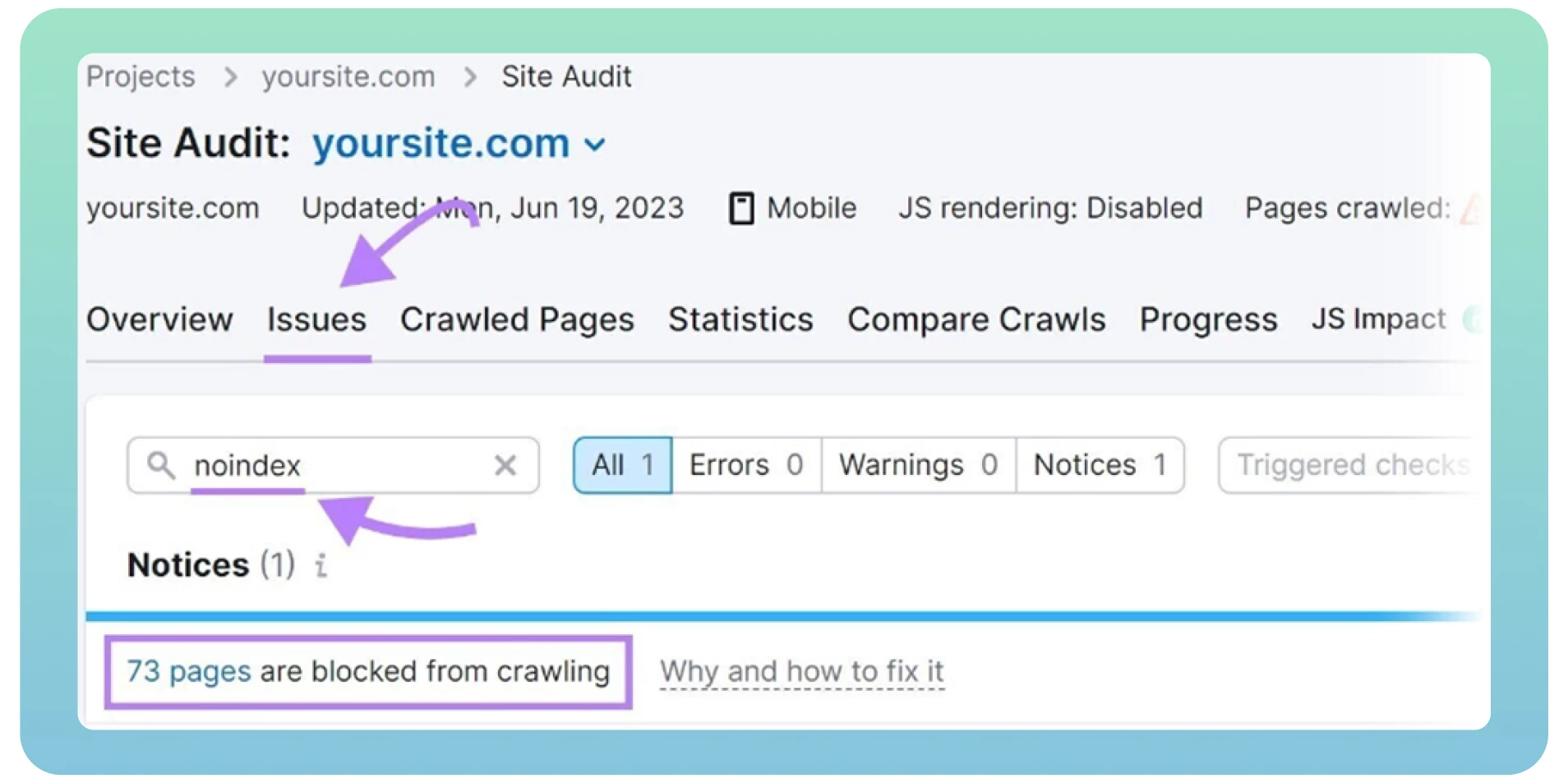
5. Duplicatas de pages
Souvent, des pages web différentes ayant le même contenu peuvent être chargées à partir d’URL différentes, ce qui entraîne une duplication de la page. Par exemple, vous avez deux versions de votre domaine (www et non-www) qui mènent à la page d’accueil de votre site. Ces pages n’affectent pas les visiteurs de votre site web, mais elles peuvent affecter la perception de votre site web par les moteurs de recherche.
Le pire, c’est que les moteurs de recherche ne peuvent pas déterminer quelle page doit être considérée comme prioritaire en raison du contenu dupliqué. Le Googlebot parcourt rapidement chaque page et indexe à nouveau le même contenu.
Idéalement, le robot devrait parcourir et indexer chaque page une seule fois. En outre, les différentes versions d’une même page bénéficient d’un trafic organique et d’un classement des pages, ce qui complique l’analyse des mesures de trafic dans Google Analytics.
La solution
La canonicalisation est le meilleur moyen de conserver l’autorité SEO des pages dupliquées. Voici quelques conseils à prendre en compte :
● Utilisez des balises canoniques pour indiquer à Google de détecter facilement l’URL d’origine d’une page. Voici à quoi doit ressembler le lien avec cette balise ci-dessous :
<link rel= »canonical » href= »https://example.com/page/ » />
● Vérifiez les alertes dans Google Search Console – il peut s’agir de quelque chose comme « Trop d’URL » ou d’un langage similaire lorsque Google rencontre plus d’URL et de contenu qu’il ne le devrait.
● N’utilisez pas simultanément les balises canoniques et noindex, car les robots des moteurs de recherche peuvent considérer les pages web canoniques noindexées comme des doublons.
● Créez des liens canoniques vers la page « Afficher tout ».
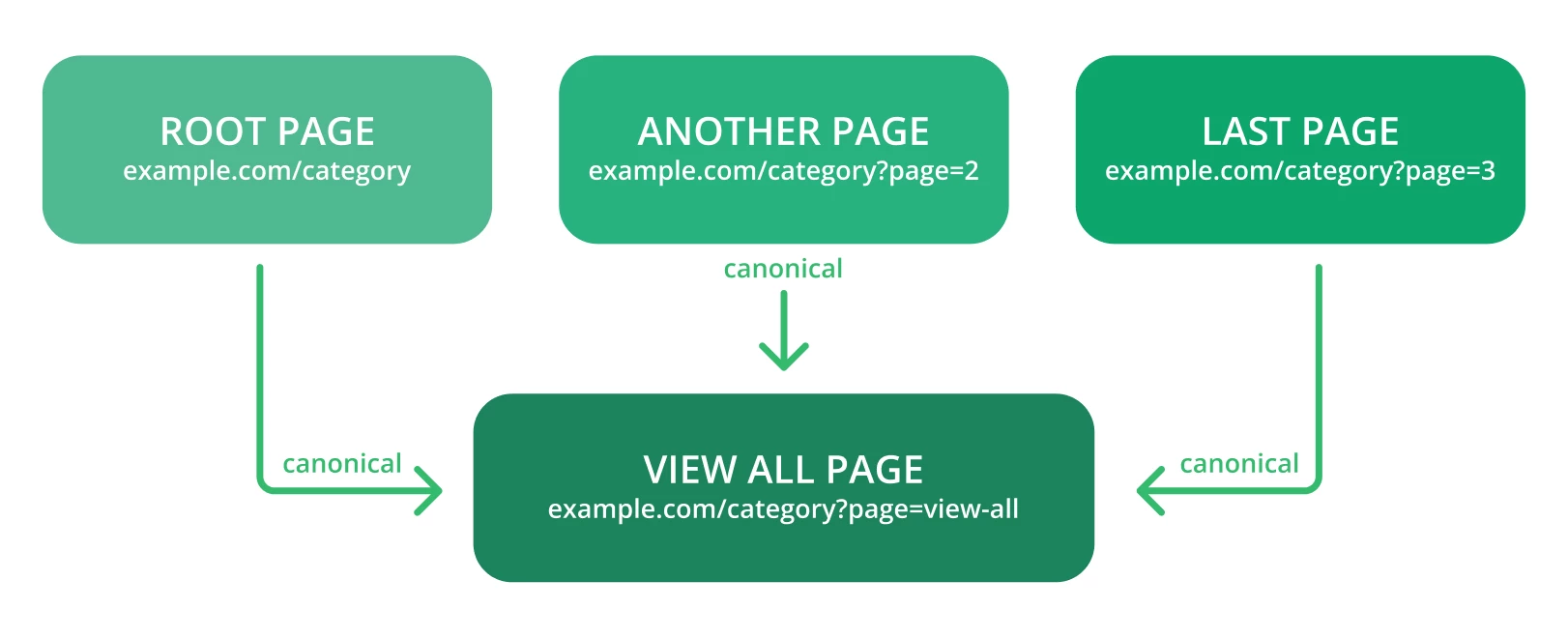
● Canonicaliser chaque URL créée par la navigation à facettes.
6. Vitesse de chargement lente
La vitesse de chargement des pages est l’un des facteurs les plus critiques qui affectent la crawlabilité de votre site web. Une vitesse de chargement lente peut créer une mauvaise expérience utilisateur et réduire le nombre de pages que les robots des moteurs de recherche peuvent explorer au cours d’une session de crawl. Cela peut avoir pour conséquence d’exclure des pages web cruciales de l’exploration.
En d’autres termes, plus vos pages web se chargent rapidement, plus le Googlebot peut explorer rapidement le contenu du site et mieux se classer dans les résultats de recherche. C’est pourquoi il est essentiel d’améliorer la vitesse et les performances globales du site web.
La solution
Voici quelques conseils utiles à prendre en compte lors de l’optimisation de la vitesse du site :
● Utilisez Google PageSpeed Insights pour mesurer vos temps de chargement actuels, détecter d’éventuelles erreurs et obtenir des conseils exploitables pour améliorer les performances du site.
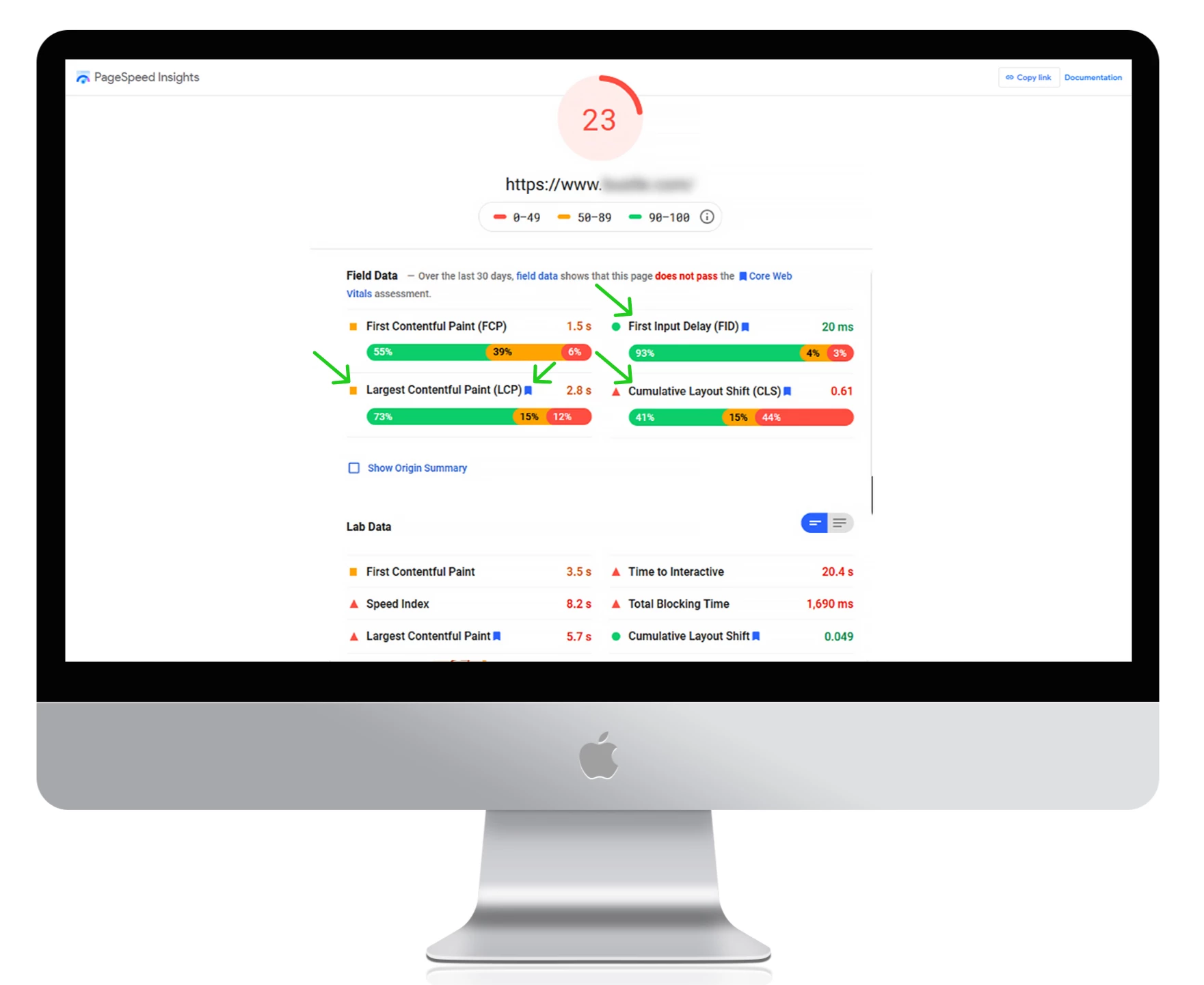
Utilisez un réseau de diffusion de contenu (CDN) pour rediriger votre contenu sur différents serveurs à travers le monde. Il réduira la latence et accélérera le fonctionnement de votre site web.
Choisissez un hébergeur rapide.
Compressez la taille des images et des fichiers vidéo pour augmenter la vitesse de chargement.
Supprimez les plugins inutiles et réduisez le nombre de fichiers CSS et JacaScript sur votre site.
7. Absence de liens internes
Les pages web qui manquent de liens internes peuvent rencontrer des problèmes d’indexation. Les liens internes consistent à relier une page à une autre page pertinente au sein du même domaine. Ils aident les utilisateurs à naviguer facilement sur votre site web et fournissent aux moteurs de recherche des informations utiles sur votre structure et votre hiérarchie.
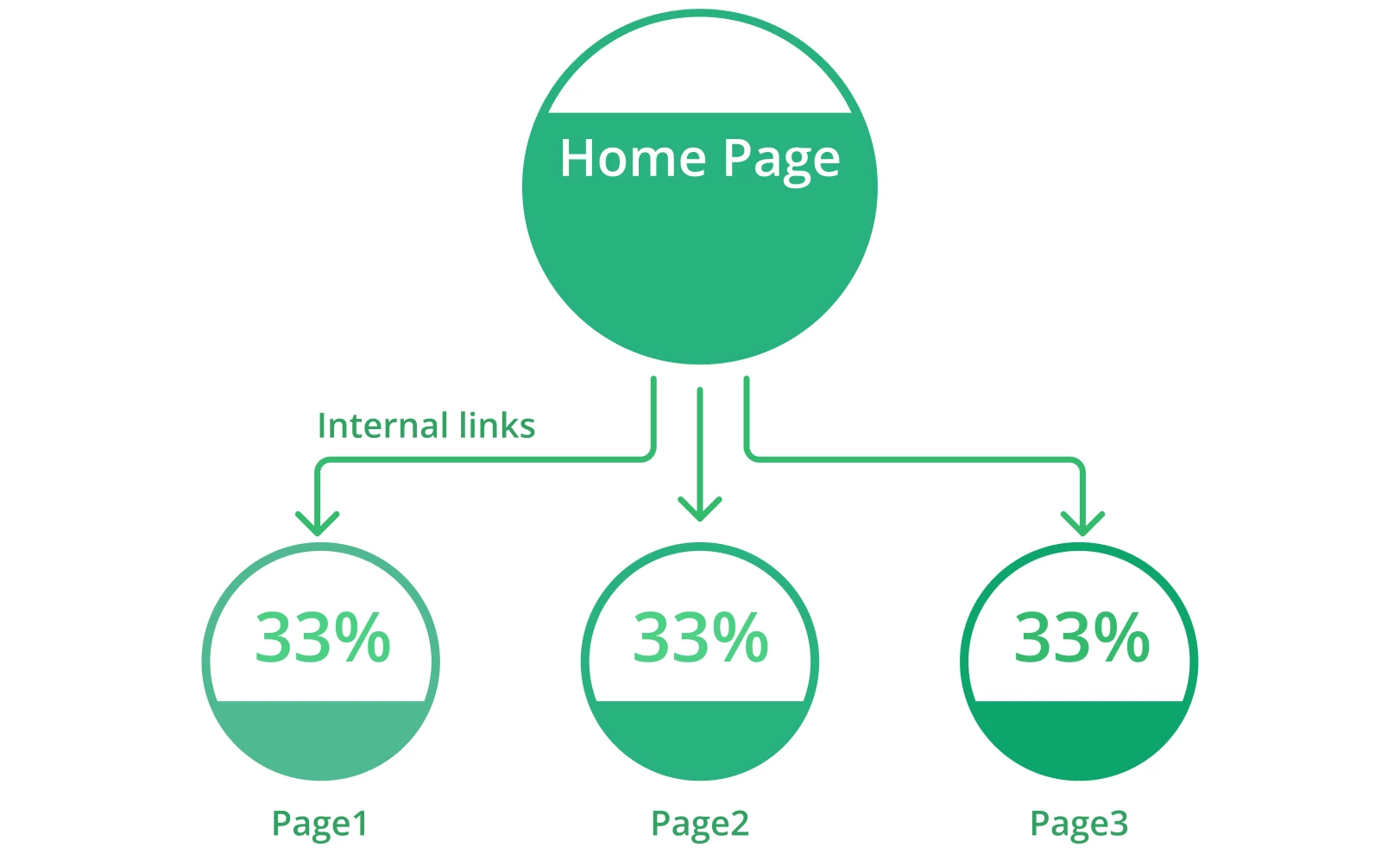
Chaque page de votre site doit comporter au moins un lien interne. Cela montrera aux moteurs de recherche que vos pages sont liées entre elles et connectées. Les pages isolées sont difficilement considérées par les robots comme faisant partie de votre site. Plus il y a de liens internes pertinents, plus les robots parcourent facilement et rapidement l’ensemble du site web.
La solution
Voici quelques conseils exploitables à prendre en compte :
● Réalisez un audit SEO pour déterminer où ajouter davantage de liens internes à partir des pages pertinentes de votre site.
● Consultez les analyses du site web pour voir comment les utilisateurs circulent sur le site et trouver des moyens de les engager avec votre contenu pertinent. Recherchez les pages présentant des taux de rebond élevés afin de les améliorer et d’ajouter davantage de contenu de qualité.
Donnez la priorité aux pages essentielles en les plaçant plus haut dans la hiérarchie du site web et en ajoutant plus de liens internes menant à ces pages.
Incluez des textes d’ancrage descriptifs pour montrer le contenu des pages liées.
Mettez à jour vos anciennes URL ou supprimez les liens brisés. Assurez-vous que chaque lien est pertinent et actif sur votre site.
Vérifiez et supprimez toute faute de frappe dans l’URL que vous incluez dans vos pages web.
8. Utiliser HTTP au lieu de HTTPS
La sécurité du serveur reste l’un des principaux facteurs de l’exploration et de l’indexation. HTTP est le protocole standard qui transmet les données d’un serveur web à un navigateur. HTTPS est considéré comme l’alternative la plus sûre à la version HTTP.
Dans la plupart des cas, les navigateurs préfèrent les pages HTTPS aux pages HTTP. Ce dernier point a un impact négatif sur le classement et la navigabilité des sites.
La solution
Obtenez un certificat SSL pour aider Google à explorer rapidement votre site web et maintenir une connexion sûre et cryptée entre votre site web et les utilisateurs.
Activez la version HTTPS de votre site web.
Surveillez et mettez à jour les protocoles de sécurité. Évitez les certificats SSL expirés, les anciennes versions de protocole ou l’enregistrement incorrect des informations relatives à votre site web.
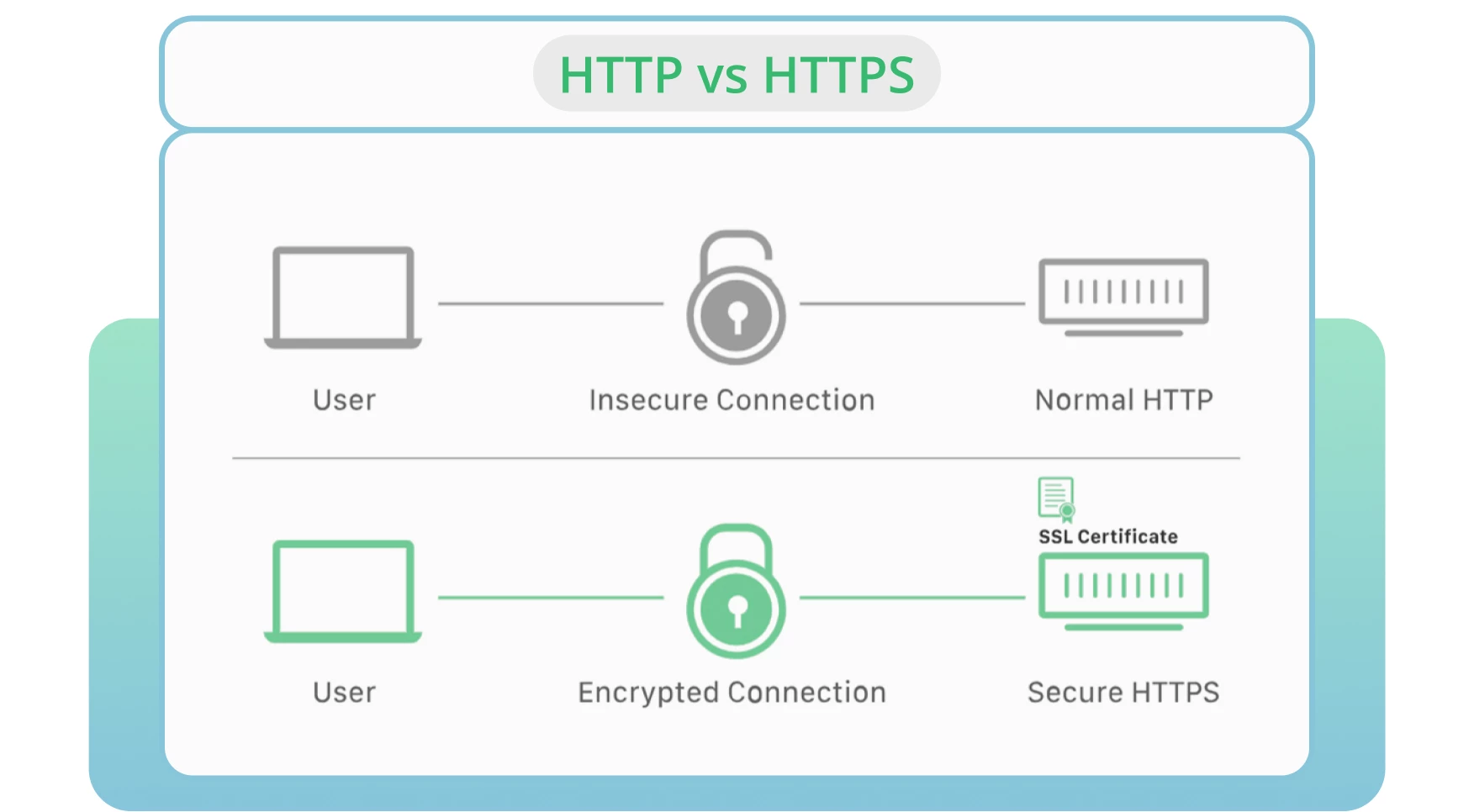
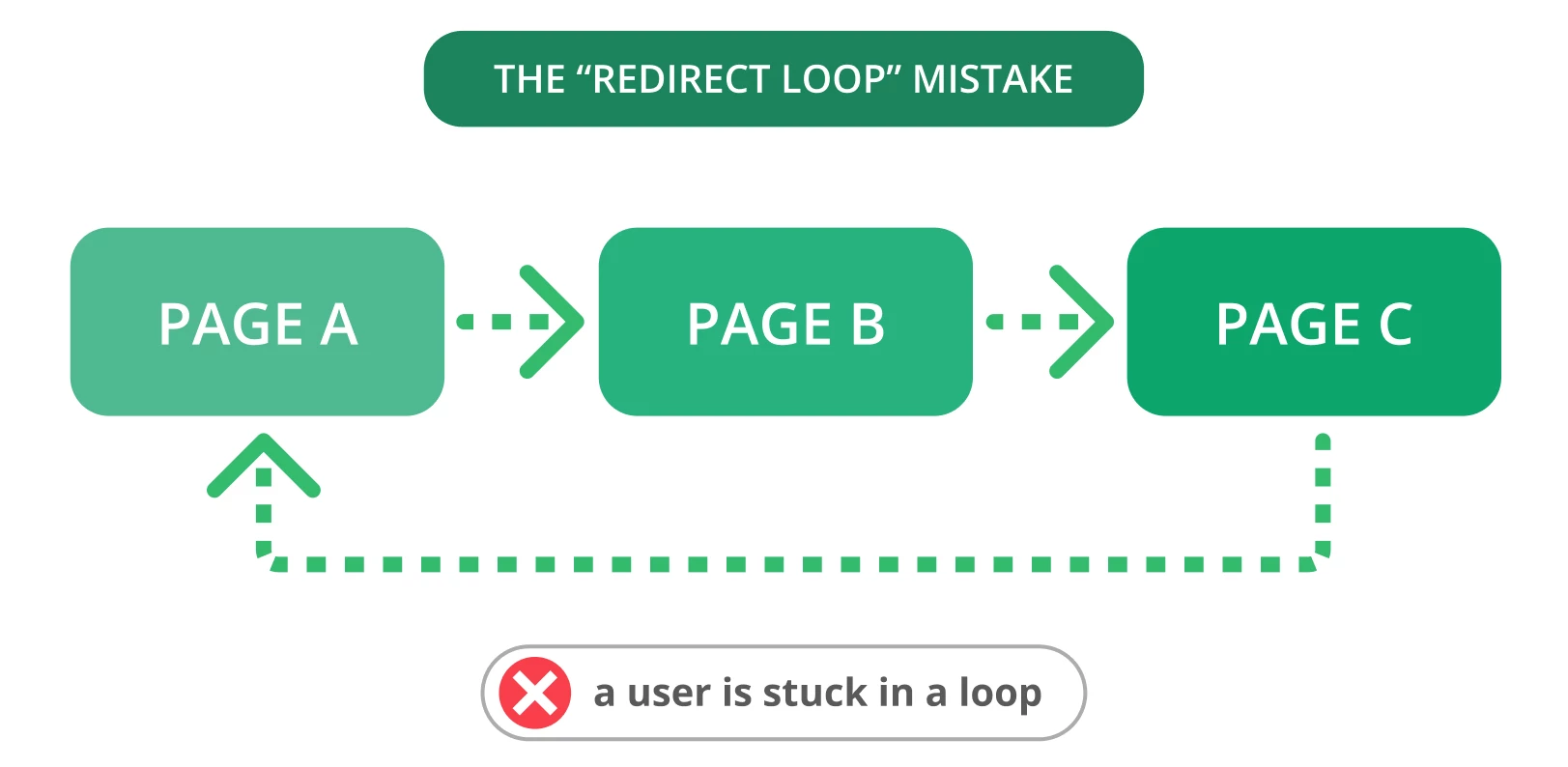
9. Boucles de redirection
Les redirections sont essentielles lorsque vous devez diriger votre ancienne URL vers une nouvelle page pertinente. Malheureusement, des problèmes de redirection, tels que des boucles de redirection, peuvent souvent se produire. Cela peut perturber les utilisateurs et empêcher les moteurs de recherche d’explorer vos pages.
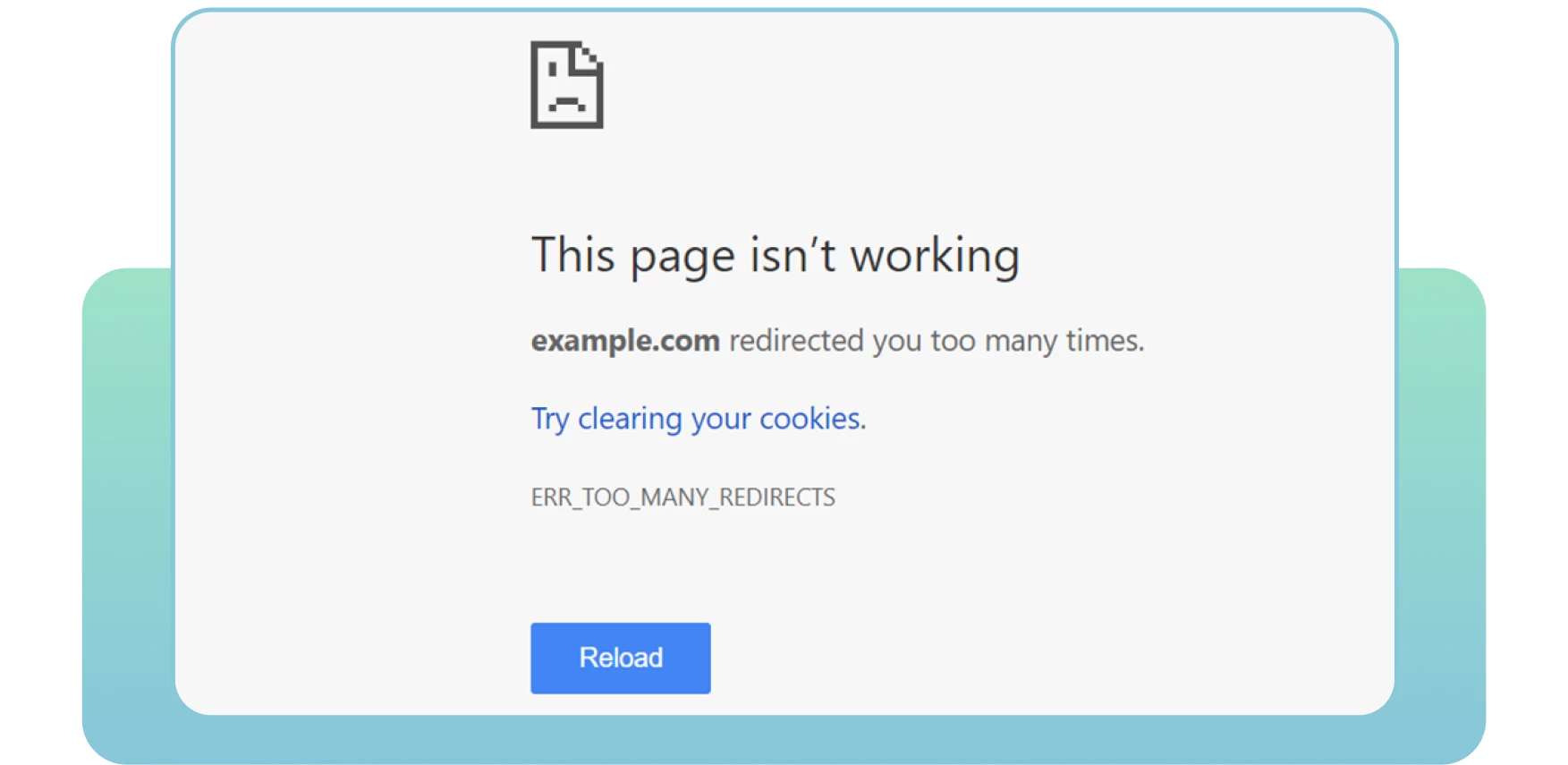
Une boucle de redirection se produit lorsqu’une URL est redirigée vers une autre, puis revient à l’URL d’origine. Les moteurs de recherche sont alors confrontés à un cycle infini de redirections entre deux ou plusieurs pages. Il peut affecter votre budget d’exploration et l’exploration de vos pages importantes.
La solution
Voici quelques étapes pour corriger les boucles de redirection :
● Utilisez HTTP Status Checker pour trouver rapidement les chaînes de redirection et les codes d’état HTTP.
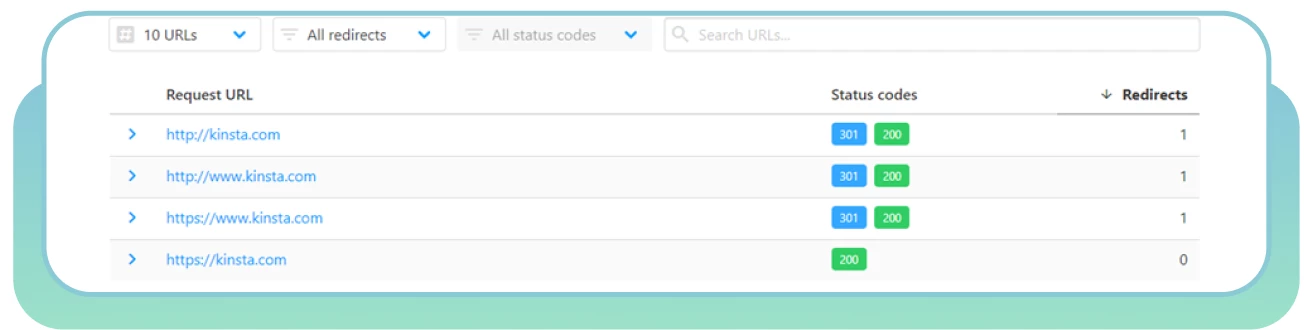
Choisissez la page « correcte » et redirigez les autres pages vers elle.
Supprimez la redirection à l’origine de la boucle.
Marquez les pages avec un code de statut 403 comme nofollow pour optimiser votre budget d’exploration. Ces pages ne peuvent être utilisées que par les utilisateurs enregistrés.
Utilisez des redirections temporaires pour indiquer aux robots des moteurs de recherche de revenir sur votre page. Utilisez une redirection permanente si vous ne souhaitez plus indexer la page d’origine.
10. Mauvaise architecture du site
L’organisation des pages et du contenu de votre site web est l’un des facteurs les plus importants pour optimiser la navigabilité. Une mauvaise architecture du site entraînera des erreurs d’exploration pour les robots d’indexation qui découvriront des pages web situées au bas de l’échelle ou non liées (appelées « pages orphelines »).
Un site bien structuré peut aider les moteurs de recherche à trouver et à accéder facilement à toutes les pages, ce qui peut avoir un effet positif sur vos performances et votre référencement. Une structure de site idéale permet d’atteindre toutes les pages à quelques clics de la page d’accueil, sans pages orphelines.
Par exemple, la structure d’un site typique peut ressembler à une pyramide. La page d’accueil se trouve au sommet, et plusieurs couches renvoient aux pages des sujets principaux, qui mènent aux pages des sujets secondaires. Voici un exemple de structure de site.
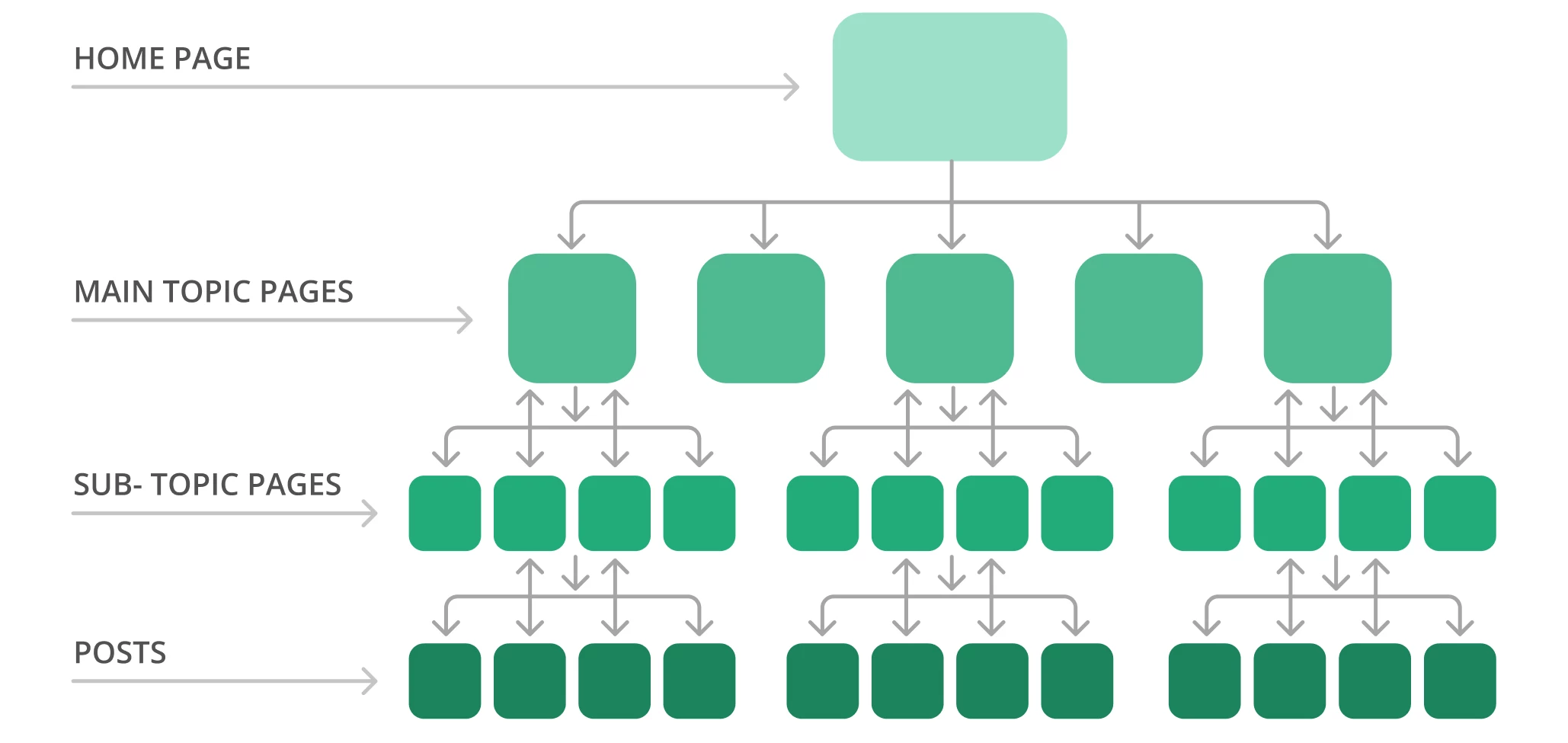
Google explore généralement le site web du haut de la page d’accueil jusqu’en bas. En d’autres termes, plus vos pages sont éloignées du sommet, plus les robots des moteurs de recherche les trouveront complexes, surtout si vous avez beaucoup de pages orphelines.
La solution
Voici quelques étapes pour optimiser l’architecture de votre site :
Utilisez Screaming Frog pour vérifier la structure actuelle de votre site et sa profondeur d’exploration.
Organisez vos pages de manière logique et hiérarchisée à l’aide de liens internes. Faites en sorte que vos pages essentielles soient accessibles en deux ou trois clics à partir de la page d’accueil.
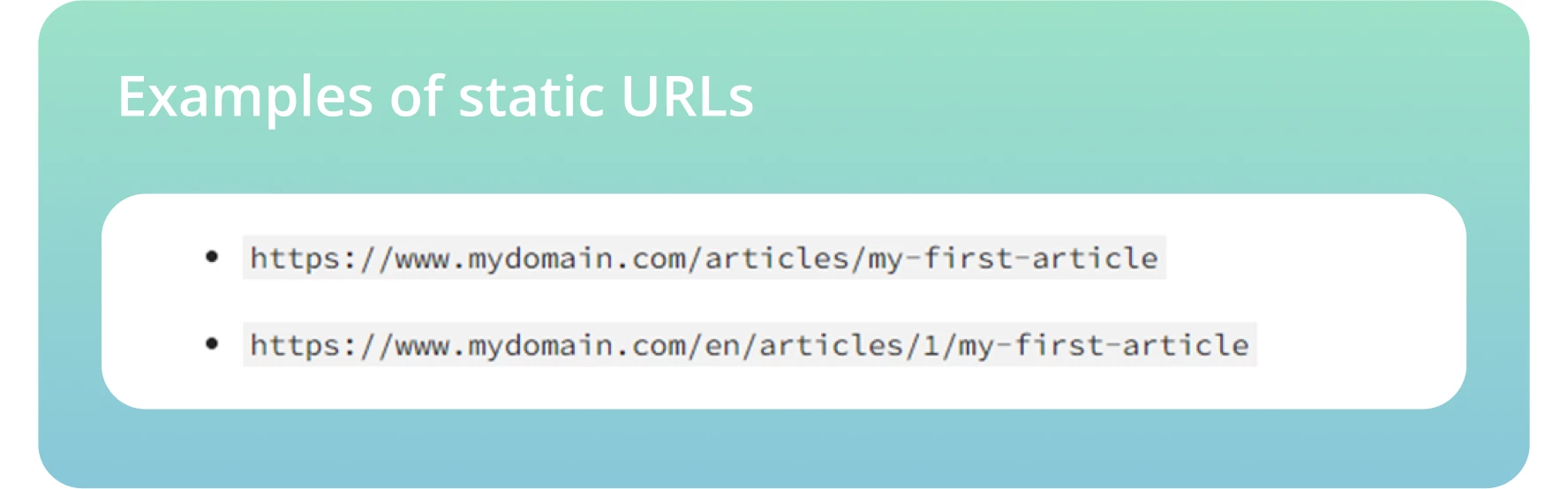
● Créez une structure URL claire. Rendez-la facile à lire pour que les moteurs de recherche et les utilisateurs comprennent le contexte et la pertinence de chaque page de votre site. Incluez des mots-clés cibles dans chaque URL dans la mesure du possible.
● Utilisez des URL statiques et évitez d’utiliser des URL dynamiques, y compris des identifiants de session ou d’autres paramètres d’URL qui rendent difficile l’exploration et l’indexation par les robots.
● Créez des fils d’Ariane pour aider Google à comprendre vos sites et les internautes à avancer et à reculer rapidement.

11. Mauvaise gestion des sitemaps
Les sitemaps désignent des fichiers XML contenant des informations importantes sur les pages de votre site. Ils indiquent aux moteurs de recherche les pages importantes du site que vous souhaitez explorer et indexer. Les sitemaps contiennent également des informations sur les images, les vidéos et les autres fichiers multimédias de votre site. Voici un exemple de sitemap :
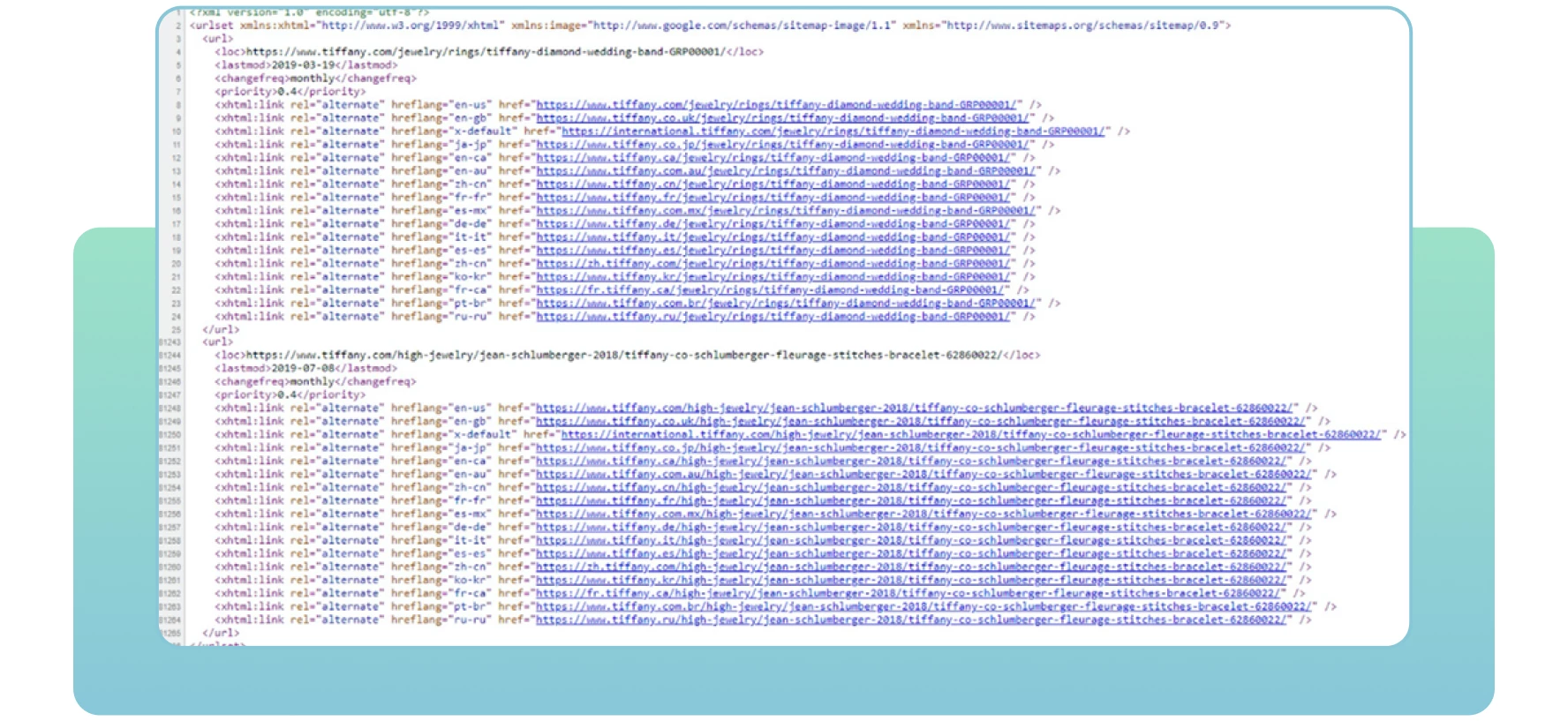
Grâce aux sitemaps, les moteurs de recherche trouveront et exploreront efficacement vos pages web essentielles. Si vous n’incluez pas certaines pages que vous souhaitez indexer et classer, les moteurs de recherche risquent de ne pas les remarquer, ce qui entraînera des problèmes d’indexation et une baisse du trafic sur votre site.
La solution
Voici quelques mesures à prendre concernant les sitemaps :
Utilisez l’outil XML Sitemaps pour créer ou mettre à jour un sitemap.
Assurez-vous que toutes les pages nécessaires sont incluses et qu’il n’y a pas d’erreurs de serveur qui pourraient rendre l’accès difficile aux robots d’indexation.
Soumettez votre sitemap à Google. Vous pouvez généralement le trouver en suivant l’URL de votre site, comme indiqué ci-dessous : domain.com/sitemap.xml
Utilisez Google Search Console pour contrôler l’état de votre sitemap et vérifier les problèmes éventuels.
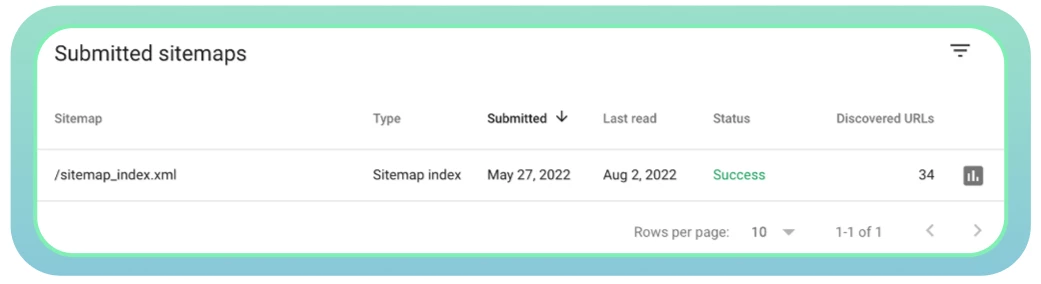
● Veillez à mettre à jour votre sitemap une fois que de nouvelles pages sont ajoutées ou supprimées de votre site web. Cela aidera les moteurs de recherche à obtenir des informations précises sur toutes vos pages web.
Conclusion
Il existe de nombreuses raisons pour lesquelles certaines de vos pages sont cachées à Google et ne se classent pas du tout. Tout d’abord, vérifiez si votre site ne présente pas de problèmes d’indexation (crawlability)
De nombreuses erreurs d’indexation peuvent affecter les performances de votre site web et indiquer aux robots des moteurs de recherche que certaines pages web ne valent pas la peine d’être indexées. Par conséquent, Google n’indexera pas et ne classera pas vos pages cruciales auxquelles il ne peut accéder.
C’est pourquoi il est essentiel de détecter tout problème de crawlabilité et de faire de son mieux pour le résoudre. En mettant en œuvre les solutions mentionnées plus haut, vous pouvez optimiser votre site pour en améliorer les performances et aider les moteurs de recherche et les utilisateurs à le trouver facilement.
Chers amis ! J’espère que cet article s’est avéré intéressant, et je serais très heureux qu’il vous soit utile. À bientôt !




