
Cos’è la crawlability: 11 modi per correggere gli errori di crawl
Salve, cari amici e appassionati di SEO! Oggi vorrei parlare della crawlability, dei problemi di crawlability più comuni e delle relative soluzioni. Questo fattore vitale può danneggiare le classifiche, il traffico e la visibilità del sito web nei risultati di ricerca. Prima di immergerci negli errori di crawling, scopriamo cos’è la crawlability e come influisce sulla SEO.

Che cos’è la crawlability?
In termini semplici, la crawlability si riferisce alla capacità dei bot dei motori di ricerca di rilevare e scansionare correttamente le pagine del vostro sito web. Per quanto riguarda la SEO tecnica, è un aspetto importante da controllare perché se Googlebot non riesce a trovare le vostre pagine web, queste non si posizioneranno mai in cima ai risultati dei motori di ricerca.
Si noti che crawlability e indexability sono cose diverse. Quest’ultima si riferisce alla capacità dei motori di ricerca di trovare correttamente i contenuti che scansionano e di aggiungerli al loro indice. Google mostra nei risultati dei motori di ricerca solo le pagine web crawlabili e indicizzabili.
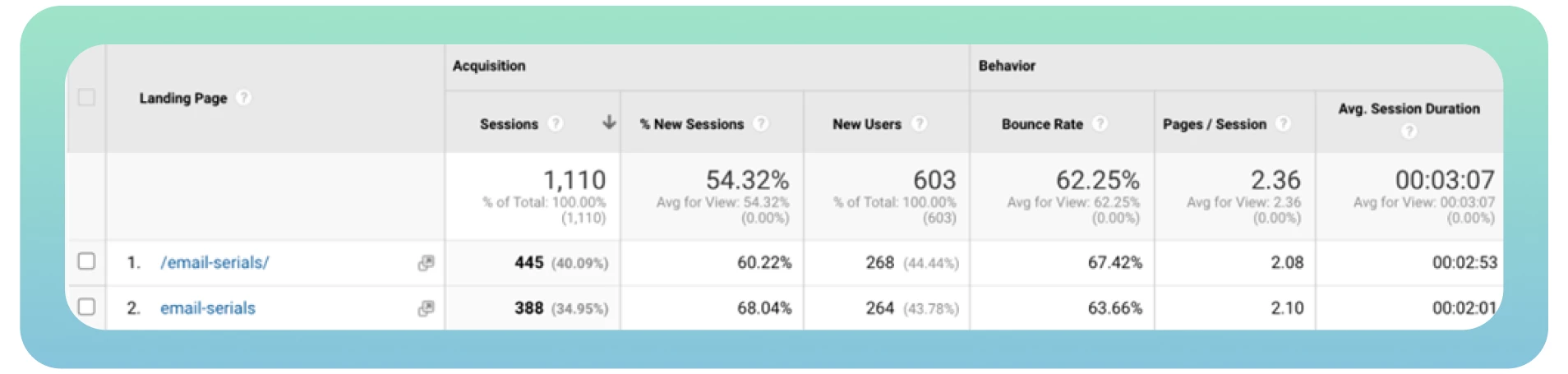
Per sapere quante pagine del vostro sito web sono state indicizzate, andate su Google e digitate “site:” con l’URL del sito. Potete dare un’occhiata all’esempio qui sotto, ma se volete che tutto sia fatto per voi, vi invitiamo a fare outsourcing con noi!
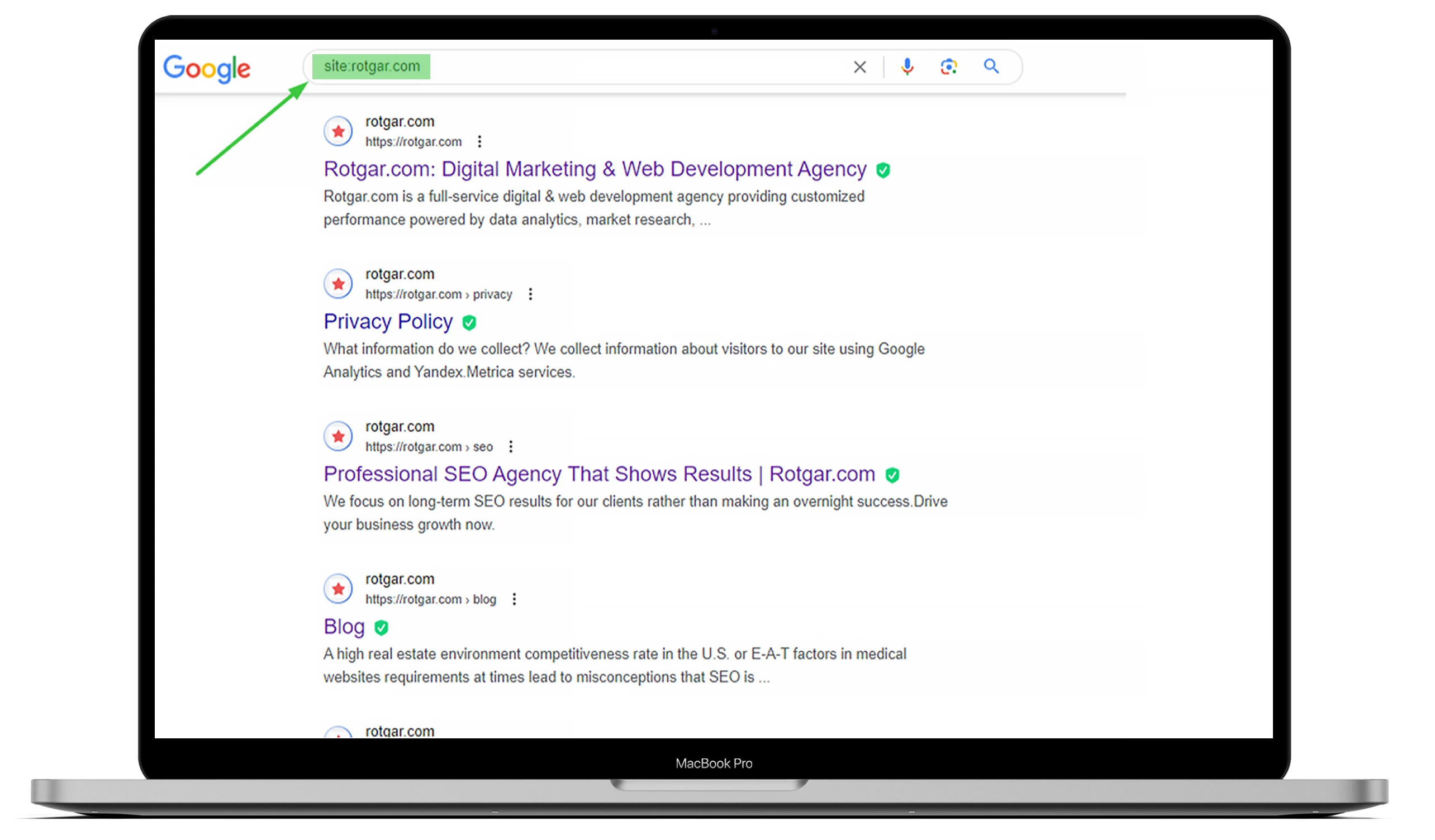
Dovete capire che i bot dei motori di ricerca, noti anche come web crawler, lavorano sempre, analizzano il contenuto e indicizzano le pagine web che trovano. Quando un Googlebot rileva un cambiamento, aggiorna i dati.
Molte cose possono influire sulla crawlabilità del vostro sito web, ma questo articolo illustrerà i problemi più comuni.
L’impatto degli errori di crawl sulla SEO
Se i bot dei motori di ricerca riscontrano problemi di crawlability sul vostro sito web, ciò può influenzare in modo significativo la vostra SEO. Le vostre pagine web non appariranno nei risultati di ricerca se un Googlebot non sa se il contenuto è rilevante per uno specifico termine di ricerca.
Ciò significa che non può indicizzarle e può comportare una perdita di conversioni e di traffico organico. Per questo motivo è essenziale avere pagine indicizzabili e crawlabili per posizionarsi al meglio nei motori di ricerca. In altre parole, più il vostro sito web è crawlable, più è probabile che le vostre pagine si indicizzino e si classifichino meglio su Google.
Come trovare gli errori di crawling in Google Search Console
Ora sappiamo cosa sono la crawlabilità e gli errori di crawl e come influiscono sulla SEO. È ora di trovare rapidamente questi errori dalla dashboard. Come forse sapete, Google Search Console divide gli errori di crawl in due sezioni: Errori del sito ed Errori dell’URL. È un ottimo modo per distinguere gli errori a livello di sito e di pagina.
Di solito, gli errori del sito sono considerati più urgenti e richiedono un’azione immediata per evitare danni all’usabilità del sito. Raccomando di essere al 100% senza errori in questa sezione.
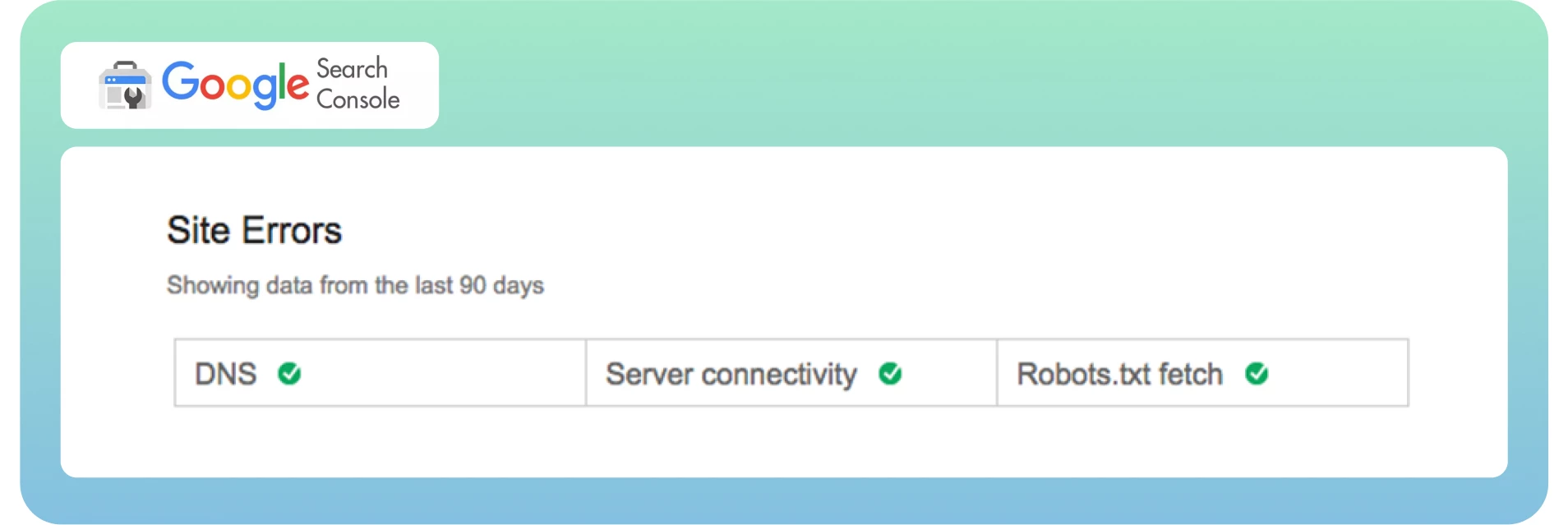
Gli errori URL sono meno catastrofici e più specifici per le singole pagine web, poiché questi errori influenzano solo alcune pagine, non l’intero sito web.
Il modo migliore per trovare gli errori di crawl è andare nella dashboard principale, vedere la sezione “Crawl” e fare clic su “Errori di crawl”.
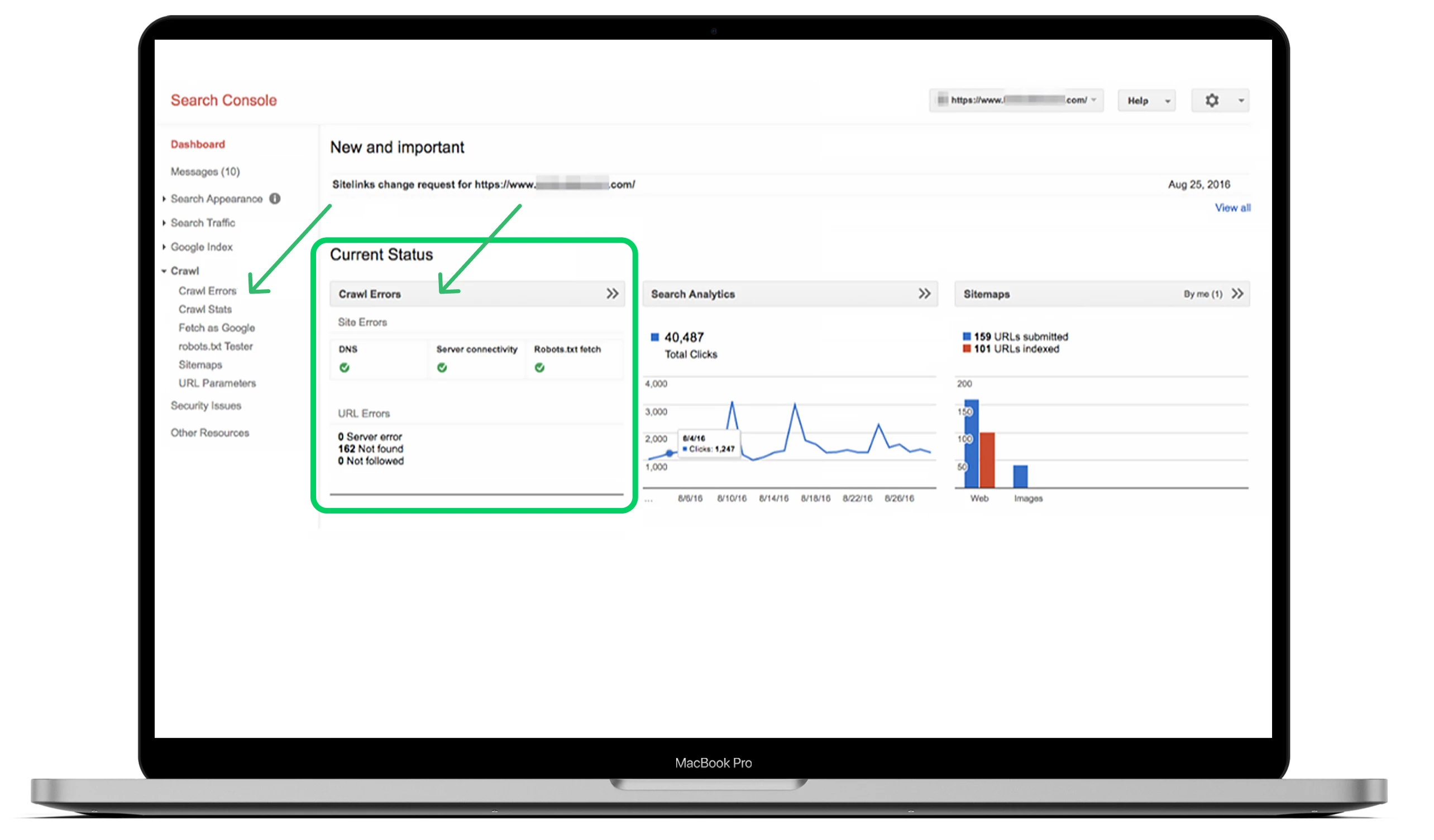
L’ideale sarebbe controllare gli errori di crawl almeno ogni tre mesi per evitare problemi gravi e mantenere la salute del sito in futuro.
I 10 principali problemi di crawlability e come risolverli
Vediamo ora i problemi di crawlability più comuni e le relative soluzioni per ottimizzare il vostro sito di conseguenza.
1. Errori 404
-Un errore 404 è uno dei problemi più complessi e più semplici di tutti gli errori contemporaneamente.
-In teoria, l’errore 404 si riferisce alla capacità di Googlebot di scansionare una pagina specifica che non si trova sul vostro sito web.
-In pratica, è possibile vedere molte pagine come 404 in Google Search Console.
Ecco cosa afferma Google:

“Gli errori 404 non danneggiano molto le prestazioni e le classifiche del vostro sito su Google, quindi potete tranquillamente ignorarli”.
È essenziale correggere gli errori 404 quando le vostre pagine web cruciali presentano questi problemi. Assicuratevi di distinguere le pagine per evitare errori e trovare la radice del problema. Quest’ultimo aspetto è molto importante, soprattutto se la pagina riceve link importanti da fonti esterne e ha molto traffico organico sul vostro sito.
La soluzione
Ecco alcuni passaggi per risolvere le pagine importanti con errori 404:
Ricontrollate che la pagina di errore 404 sia corretta e che provenga dal vostro CMS, ma non sia in modalità bozza.
Verificate su quale versione del vostro sito compare l’errore, se WWW o non WWW e se http o https.
Aggiungete un reindirizzamento 301 alla pagina più pertinente del vostro sito se non aggiornate la pagina.
Se la pagina non è più viva, rinnovatela e rendetela nuovamente viva.
Per trovare tutte le pagine con errori 404 in Google Search Console, andate su Errori di crawl -> Errori URL e fate clic su tutti i link che volete correggere:
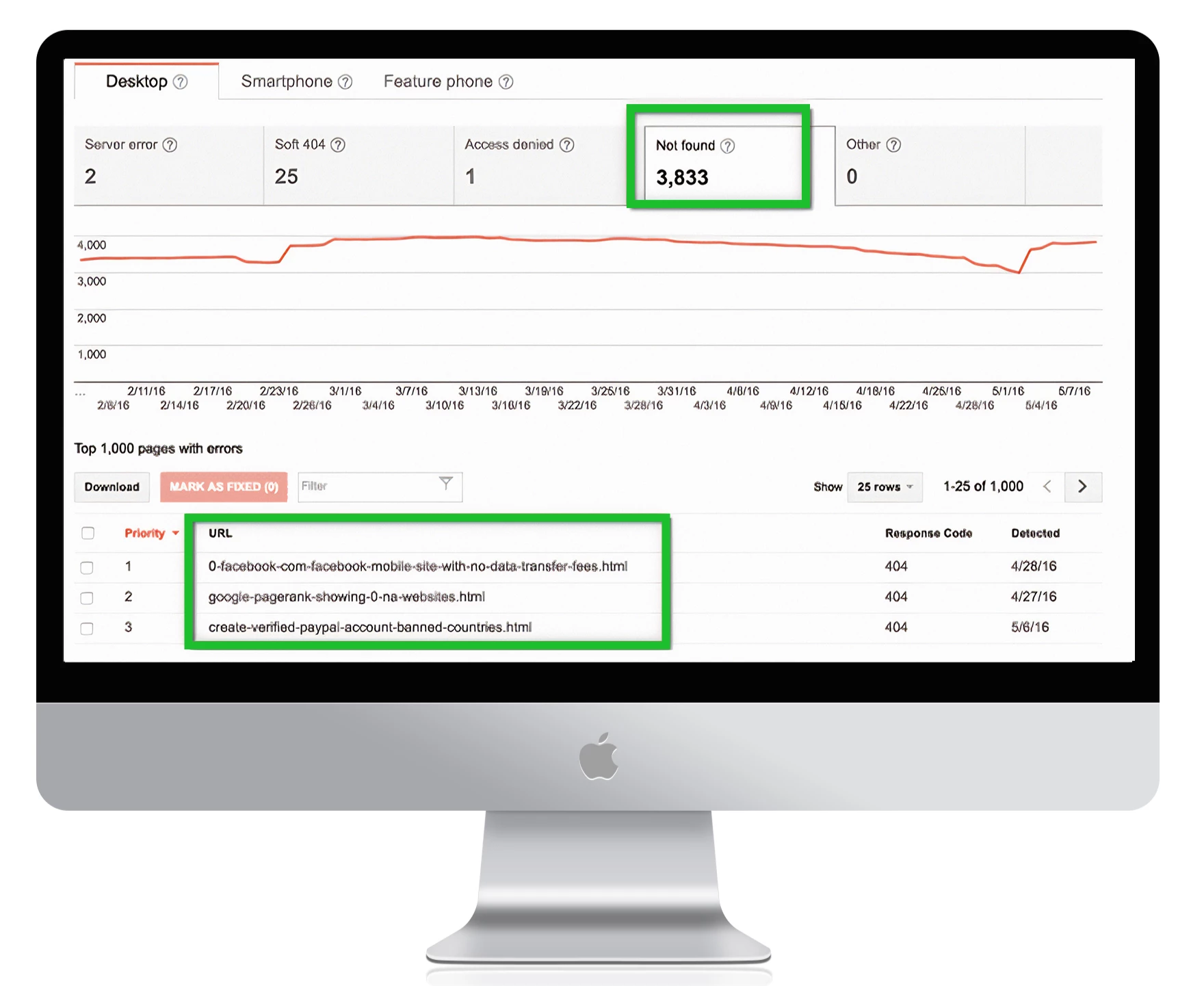
1. Avviso:
se avete una pagina 404 personalizzata che non restituisce uno stato 404, Google la noterà come un soft 404. Ciò significa che la pagina non ha abbastanza contenuti utili per gli utenti e restituisce uno stato 200. Tecnicamente, esiste ma è vuota, il che riduce le prestazioni del crawl del sito.
Gli errori Soft 404 possono confondere i proprietari dei siti web, poiché sembrano uno strano ibrido tra 404 e pagine web standard. Assicuratevi che Googleblog non consideri le pagine più importanti del vostro sito web come soft 404.
2. Link Nofollow
Per i motori di ricerca può essere un errore confuso non strisciare i link sulla pagina di un sito web. Il tag nofollow indica al Googlebot di non seguire i link, con conseguenti problemi di crawlabilità del sito. Ecco come si presenta il tag:
<meta name=”robots” content=”nofollow”.
Nella maggior parte dei casi, questi errori derivano dal fatto che Google ha problemi con Javascript, Flash, reindirizzamenti, cookie o frame. Non dovreste preoccuparvi di correggere l’errore fino a quando non seguiranno problemi su URL ad alta priorità. Se provengono da vecchi URL non attivi o da parametri non indicizzati che servono come funzionalità extra, la priorità sarà più bassa – ma è comunque necessario esaminare questi errori.
La soluzione
Ecco alcuni passaggi per risolvere i problemi non seguiti:
Esaminare tutte le pagine con i tag nofollow utilizzando lo strumento “Fetch as Google” per vedere il sito come farebbe Googlebot.
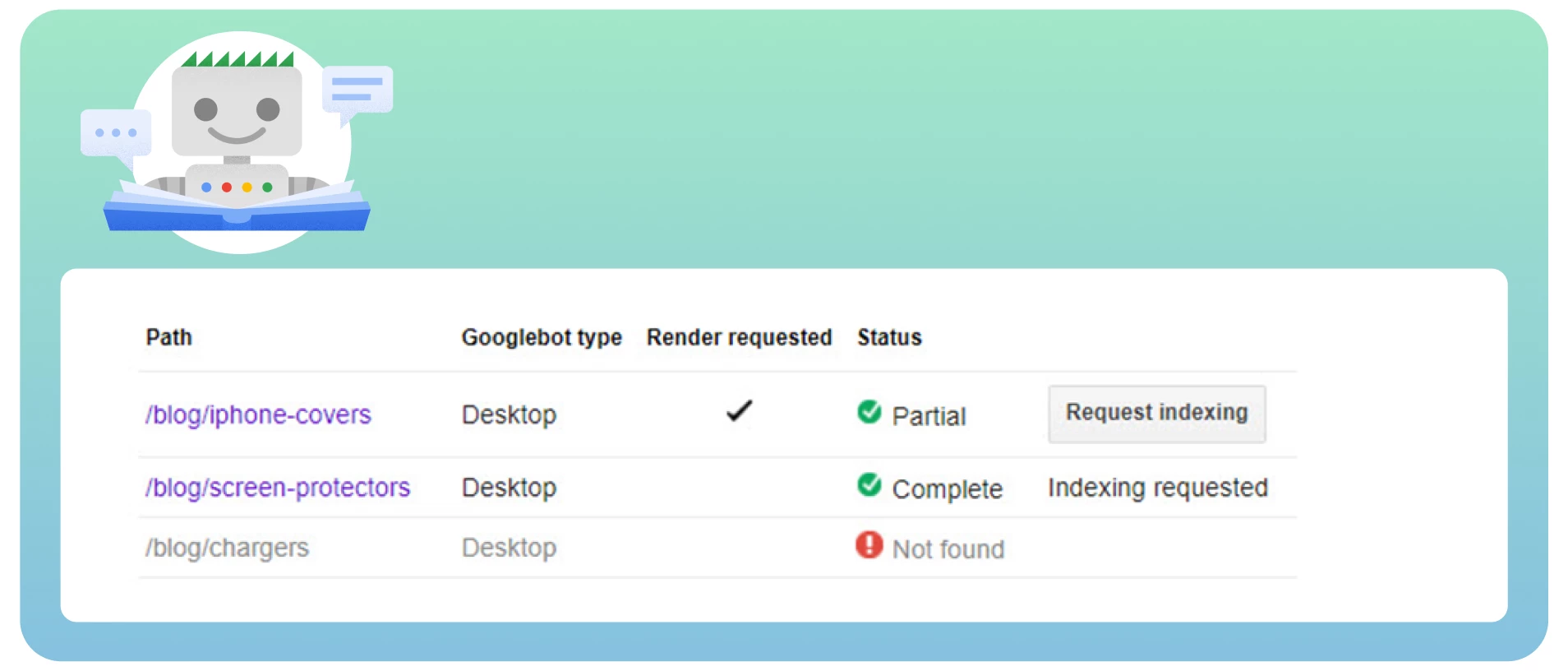
Controllate le catene di reindirizzamenti. Google può smettere di seguire i reindirizzamenti se ci sono molti cicli.
Includete nella sitemap l’URL di destinazione, non gli URL reindirizzati.
Migliorate l’architettura del sito in modo che ogni pagina del sito sia raggiungibile da link statici.
Rimuovere i tag nofollow dalle pagine in cui non dovrebbero essere presenti.
3. Pagine bloccate
Quando i bot dei motori di ricerca effettuano il crawling del vostro sito web, controllano innanzitutto il file robots.txt. Questo file indica loro quali pagine web devono e non devono essere scansionate. Ecco un esempio di file robots.txt che mostra che il vostro sito web è bloccato dal crawling:
User-agent: *
Disallow: /
Sfortunatamente, si tratta di uno dei problemi più comuni che influiscono sulla crawlabilità del sito web e che bloccano il crawling di pagine web cruciali. Per risolvere questo problema, è necessario modificare la direttiva in questo file in “Allow”, che consentirà ai bot dei motori di ricerca di effettuare il crawling dell’intero sito web.
User-agent: *
Consenti: /
Se create il vostro blog, aprirlo per il crawling e l’indicizzazione è essenziale per ottenere tutti i potenziali benefici SEO dopo averlo trasferito sul vostro sito web principale. È sufficiente utilizzare la direttiva Disallow: /blog* nell’esempio che segue:
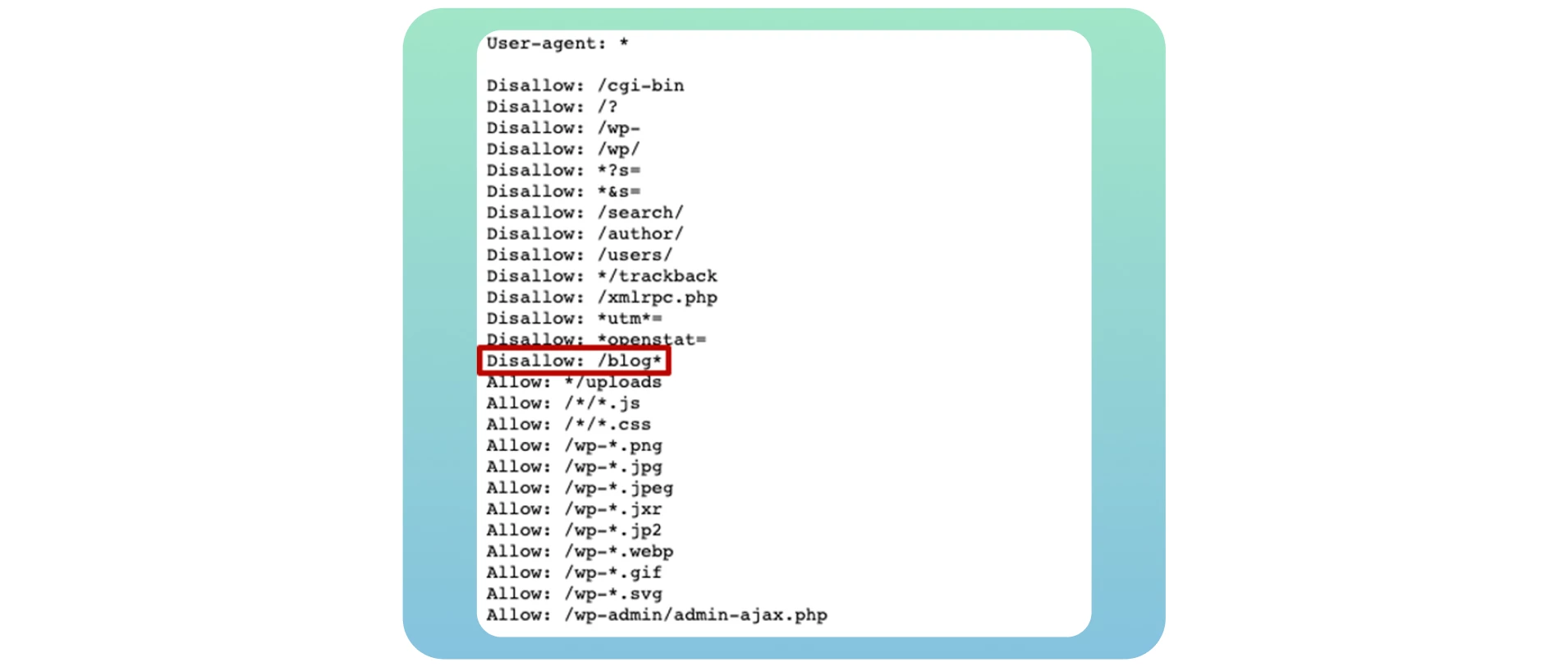
Molti proprietari di siti web inseriscono in questo file pagine specifiche di blog quando vogliono evitare di classificarle nei risultati di ricerca. Nella maggior parte dei casi, si tratta di pagine di login e di ringraziamento. Ma non si tratta di un problema di crawlablity, perché non si vuole che siano visibili nei risultati dei motori di ricerca. La presenza di un refuso o di un errore nel codice regex comporta problemi più gravi per il vostro sito.
La soluzione
Se volete che la vostra pagina sia crawlabile, assicuratevi di consentirlo nel file robot.txt. Controllate il vostro file utilizzando il robots.txt tester per trovare eventuali problemi e avvertimenti e testate URL specifici nel vostro file.
È inoltre possibile individuare eventuali errori di robots.txt utilizzando una verifica del sito web. Fortunatamente esistono molti strumenti validi per condurre un audit SEO tecnico, come Screaming Frog o Semrush. Ma prima è necessario registrarsi e aggiungere il proprio sito per ottenere risultati.
4. Tag ‘Noidex
I tag “Noindex” indicano ai motori di ricerca quali pagine non devono essere indicizzate. Ecco come si presenta il tag qui sotto:
<meta name=”robots” content=”nodiex”.
La presenza del tag “noindex” sul sito web può comprometterne la crawlabilità e l’indicizzazione sui motori di ricerca se lo si lascia a lungo sulle pagine web. Al momento del lancio, gli sviluppatori web spesso dimenticano di eliminare il tag “noindex” dal sito web.
Google considera i tag “noindex” come “nofollow” e interrompe il crawling dei link su quelle pagine. È prassi comune includere un tag “noindex” nelle pagine di ringraziamento, di login e di amministrazione per impedire l’indicizzazione da parte di Google. In altri casi, è necessario rimuovere questi tag se si desidera che i bot dei motori di ricerca effettuino il crawling delle pagine.
La soluzione
Ecco alcuni passaggi per risolvere i problemi di “noindex”:
● Analizzare le statistiche di crawl in Google Search Console per determinare la frequenza con cui Googlebot visita il vostro sito web.
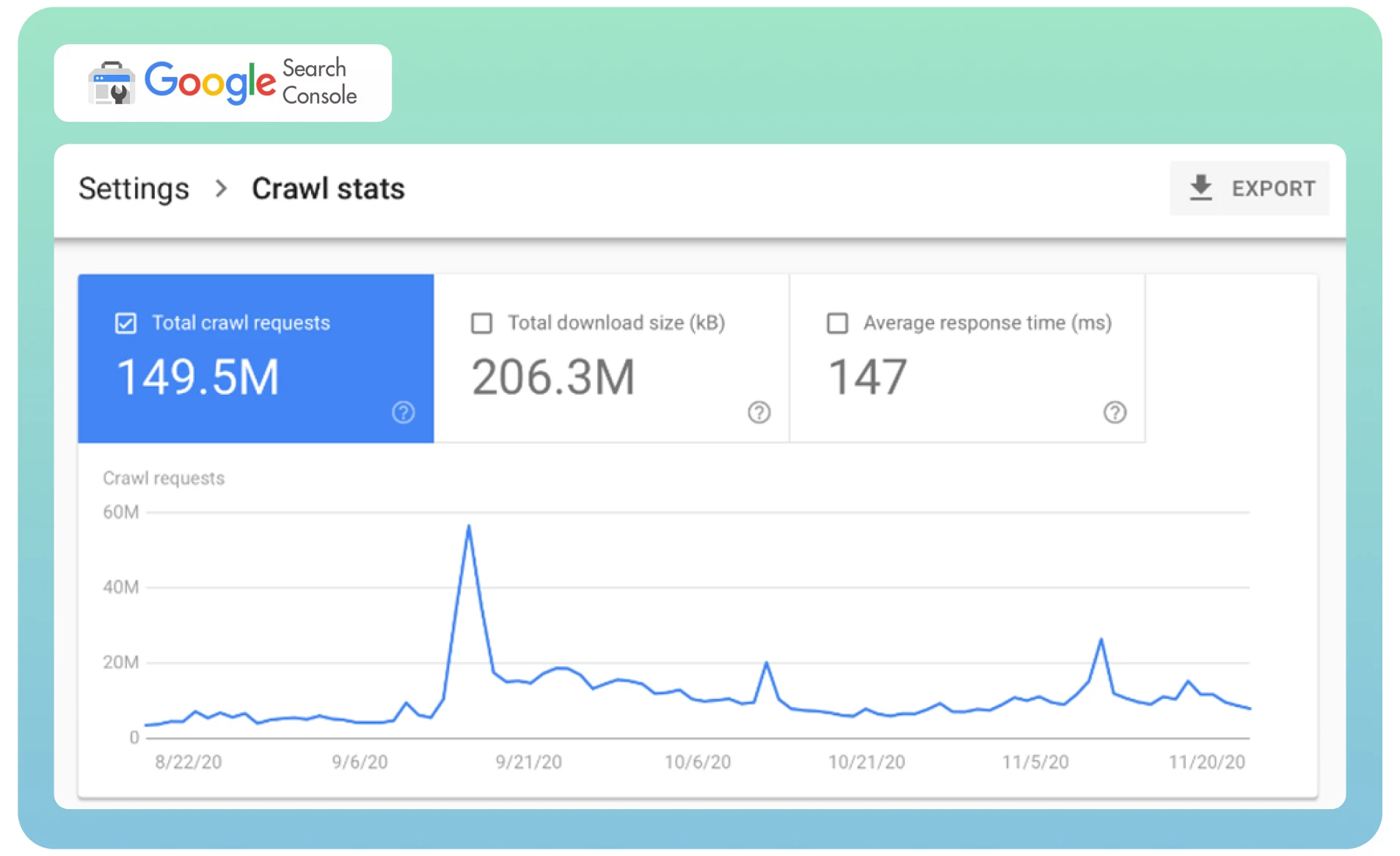
Richiedete a Google di effettuare un nuovo crawling della vostra pagina utilizzando lo strumento Rimozioni per rimuovere immediatamente la pagina già indicizzata dalle SERP. L’operazione può richiedere del tempo.
Utilizzate uno strumento di verifica del sito web come Semrush per individuare le pagine con tag “noindex”. Mostrerà un elenco di pagine del vostro sito, le esaminerà e le rimuoverà dove necessario.
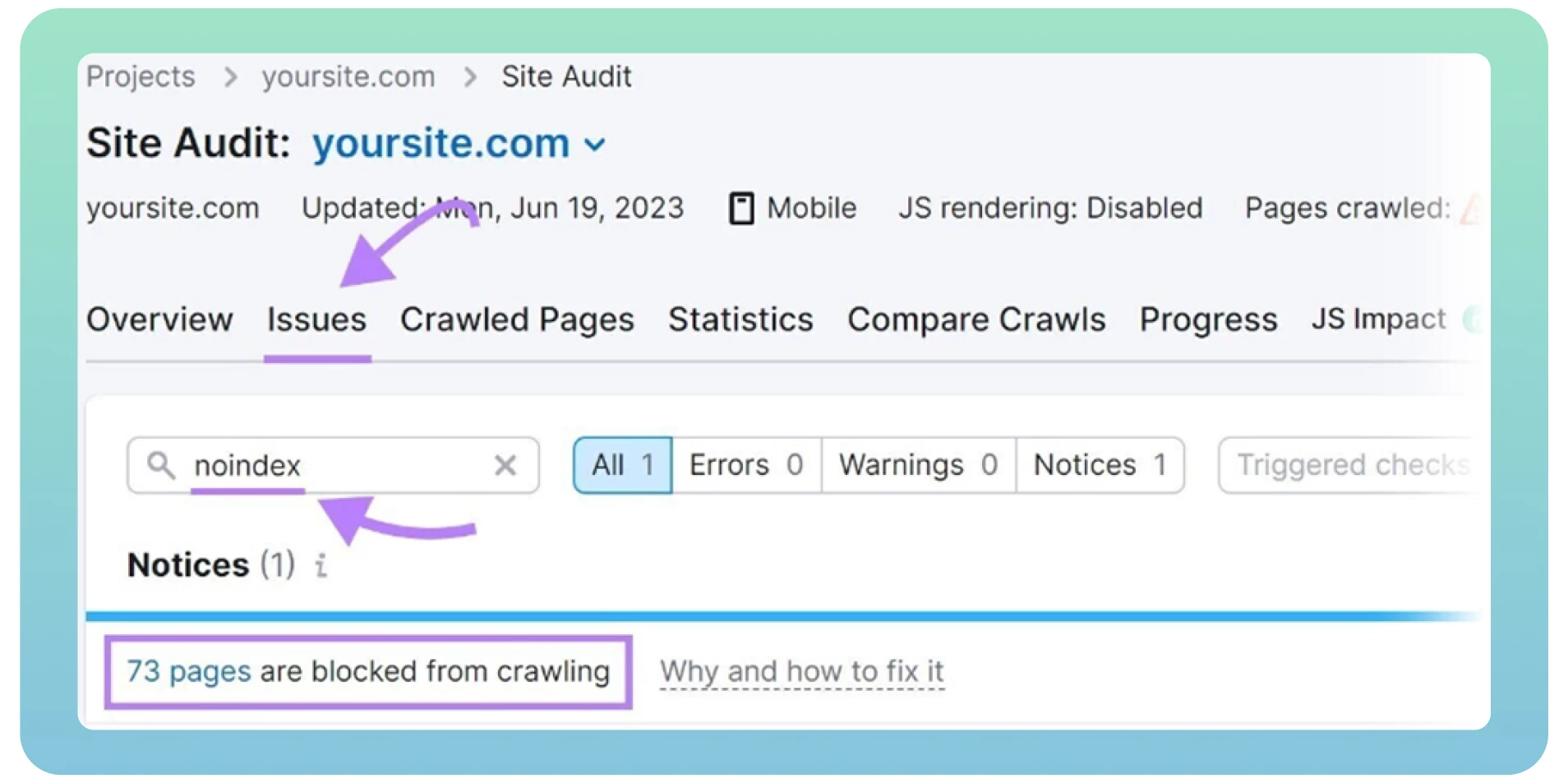
5. Duplicati di pagina
Spesso pagine web diverse con lo stesso contenuto possono essere caricate da URL diversi, con conseguente duplicazione delle pagine. Ad esempio, avete due versioni del vostro dominio (www e non www) che portano alla homepage del vostro sito. Queste pagine non influenzano i visitatori del sito, ma possono influenzare la percezione del sito da parte dei motori di ricerca.
La cosa peggiore è che i motori di ricerca non riescono a individuare quale pagina considerare come prioritaria a causa dei contenuti duplicati. Il Googlebot effettua una rapida scansione di ogni pagina e indicizza nuovamente lo stesso contenuto.
Idealmente, il bot dovrebbe scansionare e indicizzare ogni pagina una sola volta. Inoltre, versioni diverse della stessa pagina ottengono traffico organico e page rank, rendendo complicata l’analisi delle metriche del traffico in Google Analytics.
La soluzione
La canonicalizzazione è il metodo preferito per mantenere l’autorità SEO dei duplicati. Ecco alcuni suggerimenti da tenere in considerazione:
● Utilizzare i tag canonici per indicare a Google di individuare facilmente l’URL originale di una pagina. Ecco come dovrebbe apparire il link con questo tag:
<link rel=”canonical” href=”https://example.com/page/” />
Controllare gli avvisi in Google Search Console: può trattarsi di qualcosa come “Troppi URL” o un linguaggio simile quando Google trova più URL e contenuti di quanti dovrebbero essere.
Non utilizzate contemporaneamente i tag canonical e noindex, poiché i bot dei motori di ricerca possono considerare le pagine web canoniche noindex e i duplicati.
Canonicalizzare alla pagina “Visualizza tutto”.
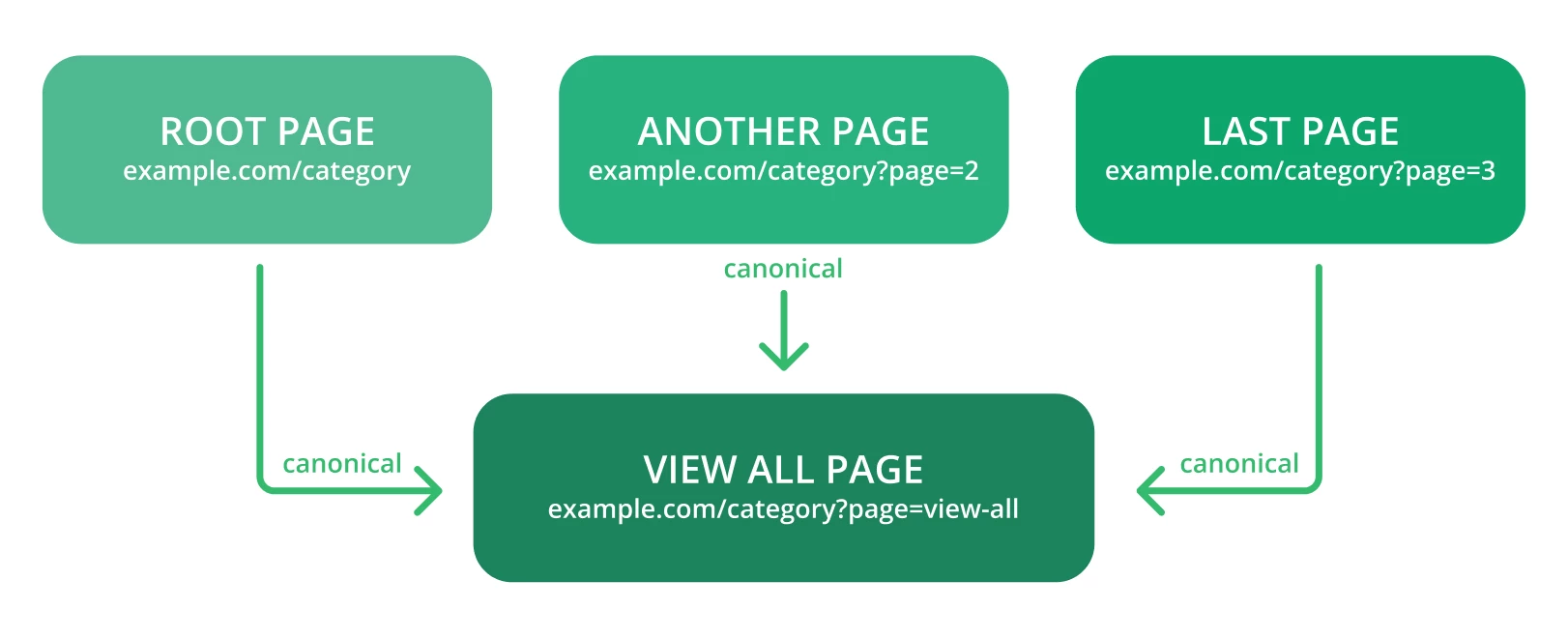
Canonicalizzare ogni URL creato dalla navigazione a faccette.
6. Velocità di caricamento lenta
La velocità di caricamento della pagina è uno dei fattori più critici che influiscono sulla crawlabilità del sito web. Una velocità di caricamento lenta può creare una cattiva esperienza per l’utente e ridurre il numero di pagine che i bot dei motori di ricerca possono scansionare in una sessione di crawling. Ciò può comportare l’esclusione di pagine web cruciali dal crawling.
In parole povere, più le pagine web si caricano velocemente, più velocemente il Googlebot può scansionare i contenuti del sito e posizionarsi meglio nei risultati di ricerca. Ecco perché è essenziale migliorare le prestazioni e la velocità complessiva del sito web.
La soluzione
Ecco alcuni consigli utili da tenere in considerazione per ottimizzare la velocità del sito:
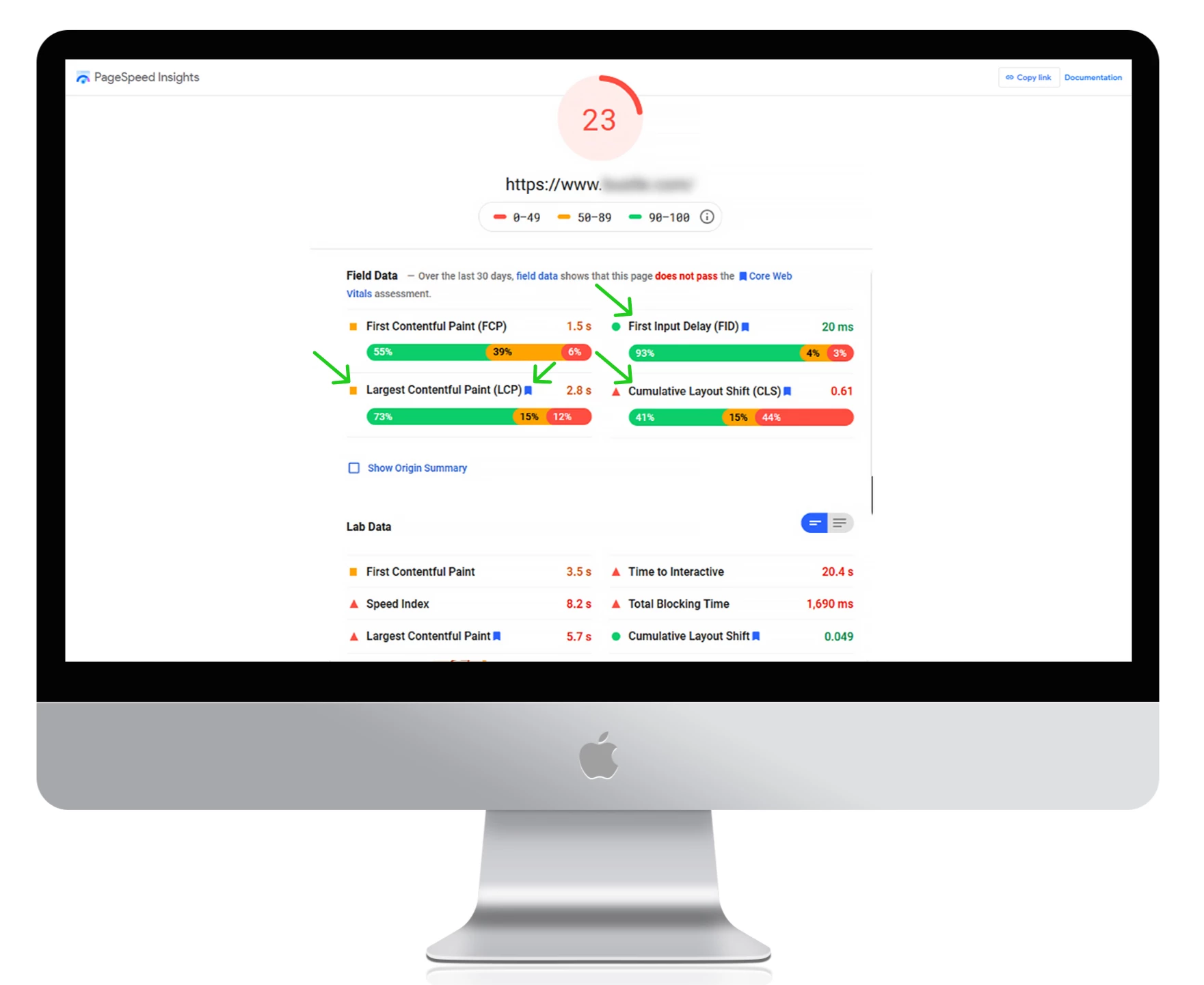
Utilizzate Google PageSpeed Insights per misurare i tempi di caricamento attuali, individuare eventuali errori e ottenere suggerimenti utili per migliorare le prestazioni del sito.
Utilizzate una rete di distribuzione dei contenuti (CDN) per reindirizzare i vostri contenuti su diversi server in tutto il mondo. Ridurrà la latenza e renderà il vostro sito più veloce.
Scegliete un provider di web hosting veloce.
Comprimete le dimensioni dei file di immagini e video per aumentare la velocità di caricamento.
Rimuovete i plugin non necessari e riducete il numero di file CSS e JacaScript sul vostro sito.
7. Mancanza di collegamenti interni
Le pagine web con una mancanza di link interni possono incontrare problemi di crawlabilità. I link interni si riferiscono al collegamento di una pagina a un’altra pagina rilevante all’interno dello stesso dominio. Aiutano gli utenti a navigare facilmente all’interno del vostro sito web e forniscono ai motori di ricerca informazioni utili sulla vostra struttura e gerarchia.
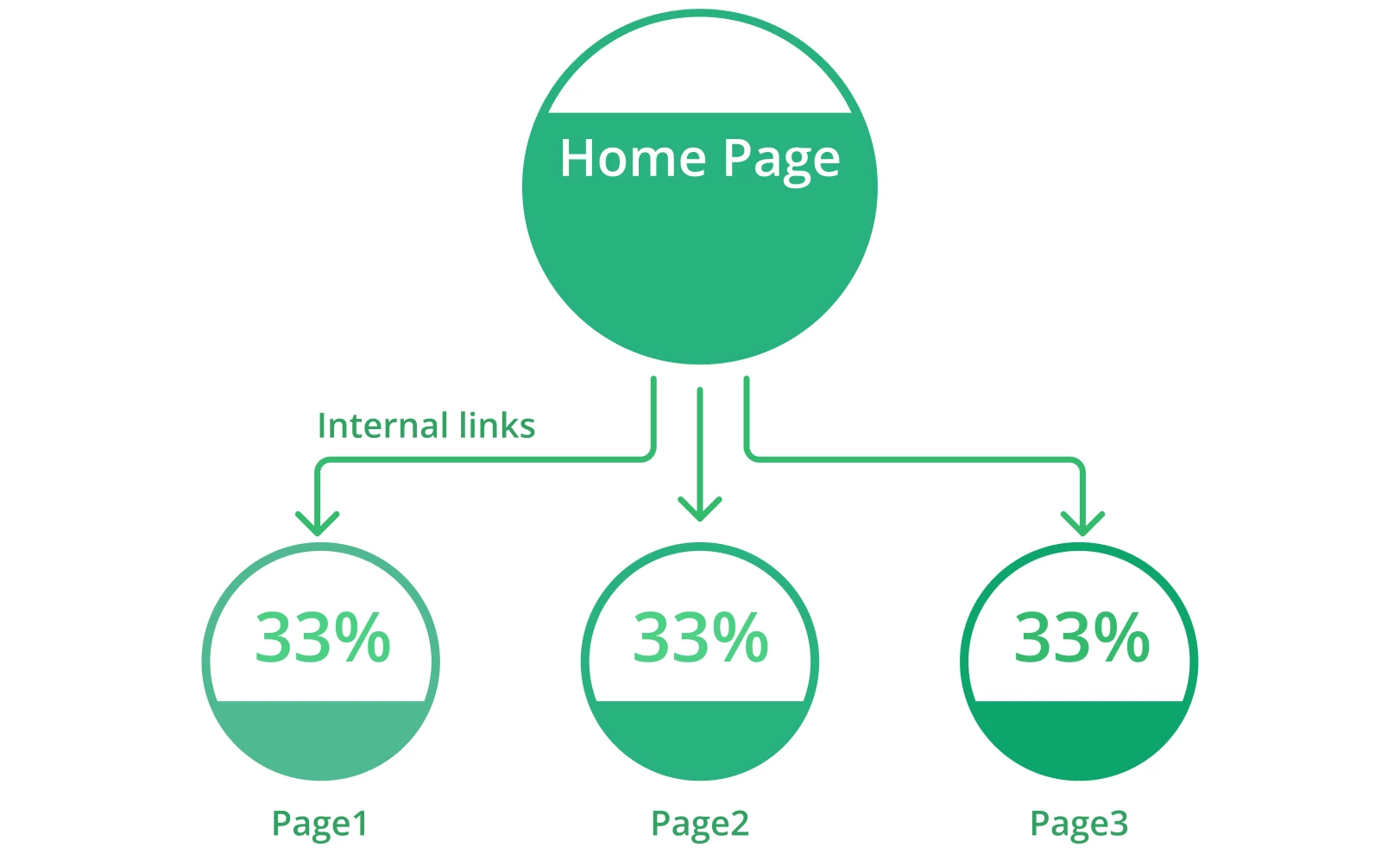
Ogni pagina del vostro sito dovrebbe avere almeno un link interno che la colleghi. Questo mostrerà ai motori di ricerca che le pagine sono interconnesse e collegate. Le pagine isolate rendono difficile per i bot considerarle parte del vostro sito. Più link interni sono pertinenti, più facile e veloce sarà la scansione dell’intero sito da parte dei bot.
La soluzione
Ecco alcuni suggerimenti pratici da prendere in considerazione:
Conducete un audit SEO per determinare dove aggiungere più link interni da pagine rilevanti del vostro sito.
Consultare l’analitica del sito web per vedere come gli utenti scorrono all’interno del sito e trovare il modo di coinvolgerli con i vostri contenuti rilevanti. Osservate le pagine con un’alta frequenza di rimbalzo per migliorarle e aggiungere più contenuti di qualità.
Date la priorità alle pagine cruciali mettendole più in alto nella gerarchia del sito e aggiungendo più link interni che conducano ad esse.
Includete testi di ancoraggio descrittivi per mostrare il contenuto delle pagine collegate.
Aggiornate i vecchi URL o rimuovete i link non funzionanti. Assicuratevi che ogni collegamento sia pertinente e attivo sul vostro sito.
Ricontrollate e rimuovete eventuali errori di battitura negli URL che includete nelle vostre pagine web.
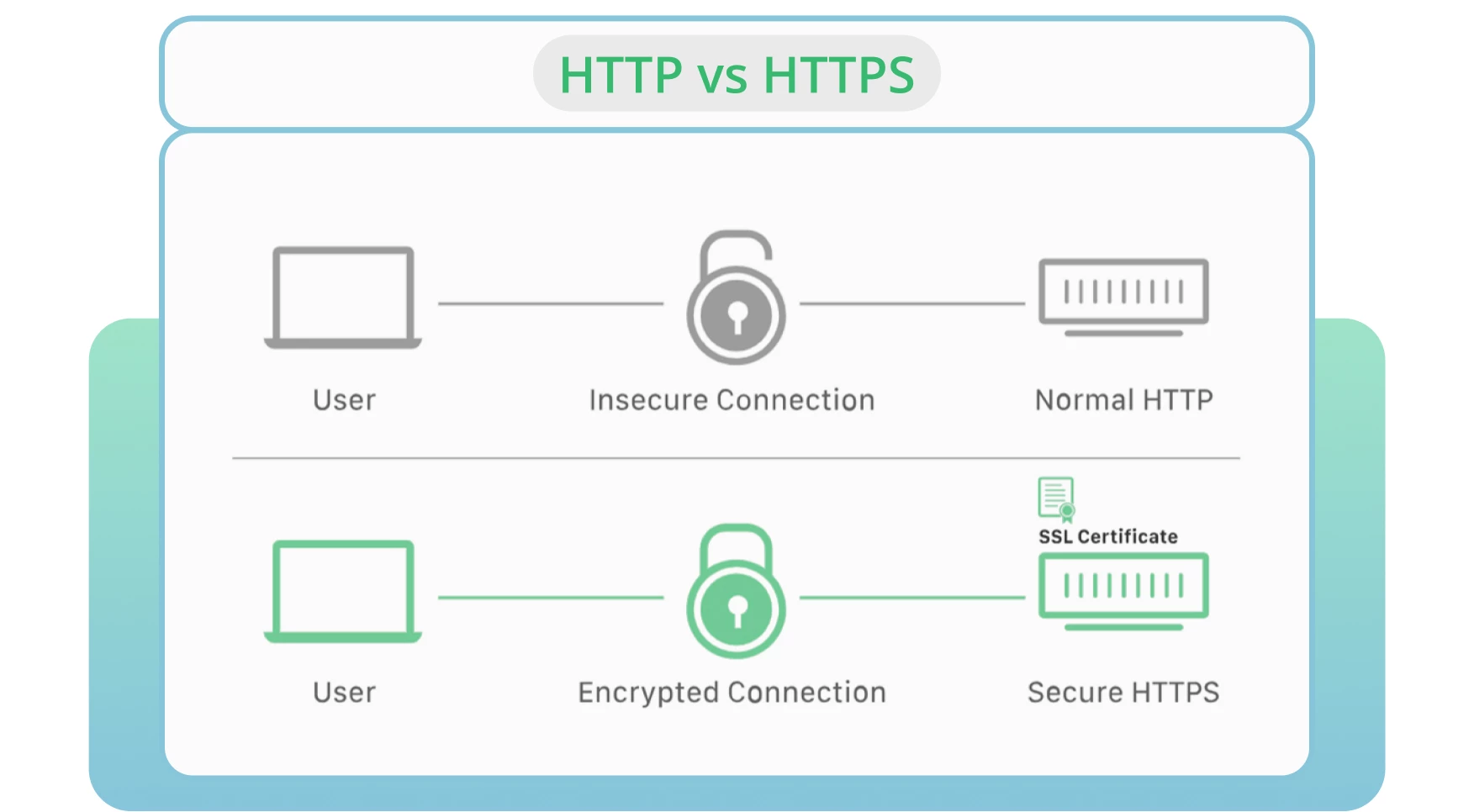
8. Usare HTTP invece di HTTPS
La sicurezza del server rimane uno dei fattori principali per il crawling e l’indicizzazione. HTTP è il protocollo standard che trasmette i dati da un server web a un browser. HTTPS è considerato l’alternativa più sicura alla versione HTTP.
Nella maggior parte dei casi, i browser preferiscono le pagine HTTPS rispetto a quelle HTTP. Quest’ultimo aspetto influisce negativamente sulle classifiche e sulla crawlabilità dei siti.
La soluzione
Procuratevi un certificato SSL per consentire a Google di effettuare rapidamente il crawling del vostro sito e mantenere una connessione sicura e crittografata tra il vostro sito e gli utenti.
Attivate la versione HTTPS del vostro sito web.
Monitorate e aggiornate i protocolli di sicurezza. Evitate i certificati SSL scaduti, le vecchie versioni del protocollo o la registrazione errata delle informazioni del vostro sito web.
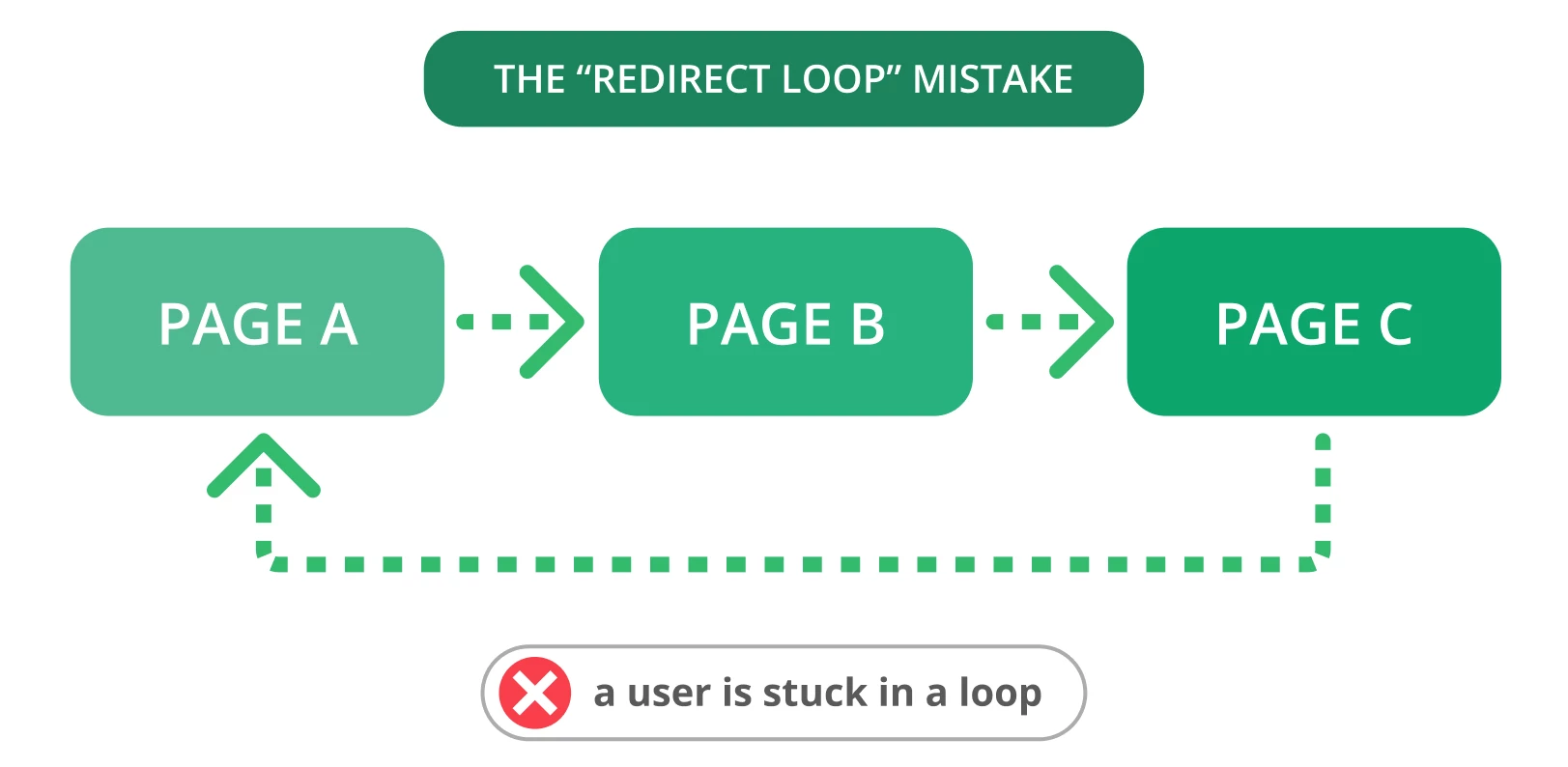
9. Loop di reindirizzamento
I reindirizzamenti sono essenziali quando è necessario indirizzare il vecchio URL a una nuova pagina pertinente. Purtroppo, spesso possono verificarsi problemi di reindirizzamento, come i loop di reindirizzamento. Questo può disturbare gli utenti e impedire ai motori di ricerca di scansionare le vostre pagine.
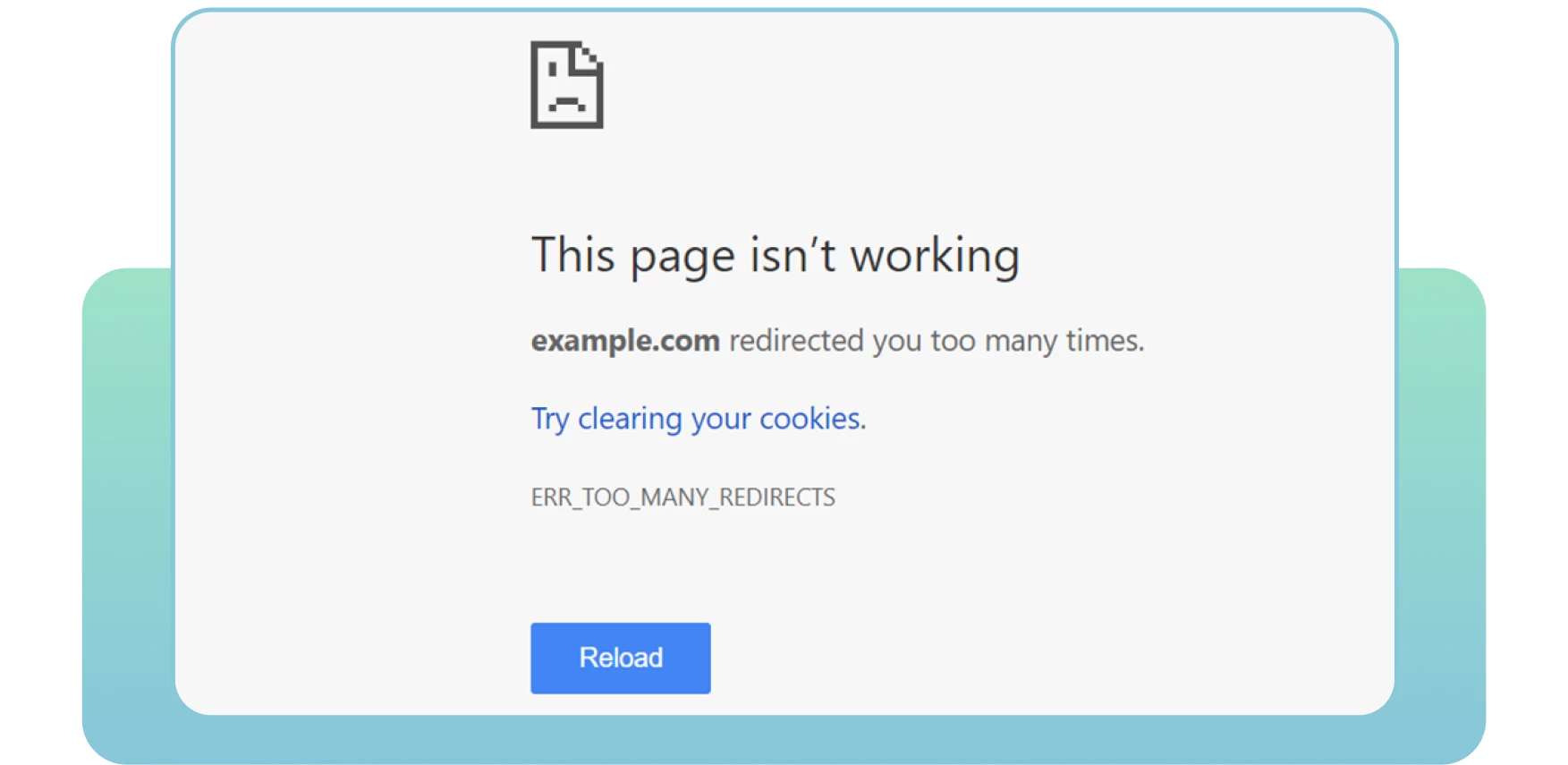
Un ciclo di reindirizzamento si verifica quando un URL viene reindirizzato a un altro, ritornando all’URL originale. Questo problema genera nei motori di ricerca un ciclo infinito di reindirizzamenti tra due o più pagine. Può influire sul budget di crawl e sul crawling delle pagine importanti.
La soluzione
Ecco alcuni passaggi per risolvere i loop di reindirizzamento:
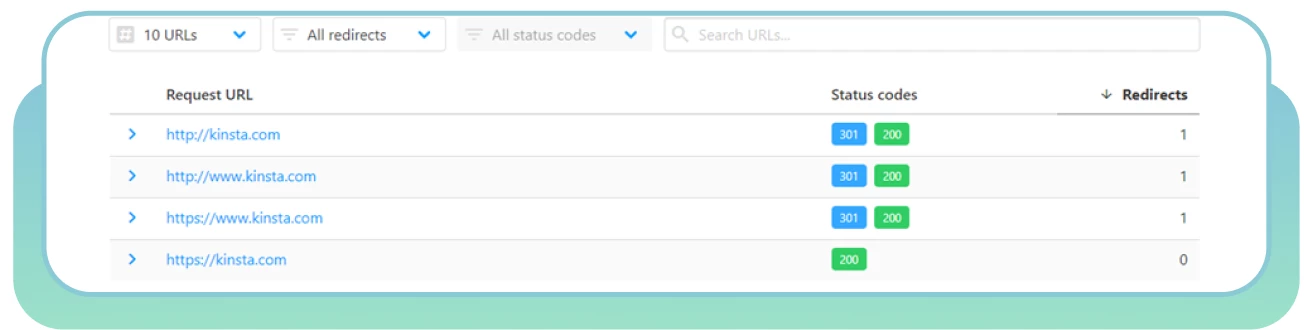
● Utilizzare HTTP Status Checker per trovare rapidamente le catene di reindirizzamento e i codici di stato HTTP.
Scegliete la pagina “corretta” e reindirizzate le altre pagine verso di essa.
Eliminare il reindirizzamento che causa il loop.
Contrassegnare le pagine con un codice di stato 403 come nofollow per ottimizzare il budget di crawl. Queste pagine possono essere utilizzate solo dagli utenti registrati.
Includete reindirizzamenti temporanei per indicare ai bot dei motori di ricerca di tornare alla vostra pagina. Utilizzare un reindirizzamento permanente se non si vuole più indicizzare la pagina originale.
10. Scarsa architettura del sito
L’organizzazione delle pagine e dei contenuti del sito web è uno dei fattori più critici per l’ottimizzazione della crawlabilità. Una cattiva architettura del sito crea errori di crawling per i web crawler che scoprono pagine web basse nella gerarchia o non collegate (note come “pagine orfane”).
Un sito ben strutturato può aiutare i motori di ricerca a trovare e accedere facilmente a tutte le pagine, il che può influire positivamente sulle prestazioni e sulla SEO. Una struttura ideale del sito significa raggiungere ogni pagina a pochi clic di distanza dalla homepage, senza pagine orfane.
Ad esempio, la struttura tipica di un sito può assomigliare a una piramide. In cima c’è la homepage, con diversi livelli che si riferiscono alle pagine dell’argomento principale e che conducono alle pagine dei sotto-argomenti. Notate la struttura del sito di esempio qui sotto.
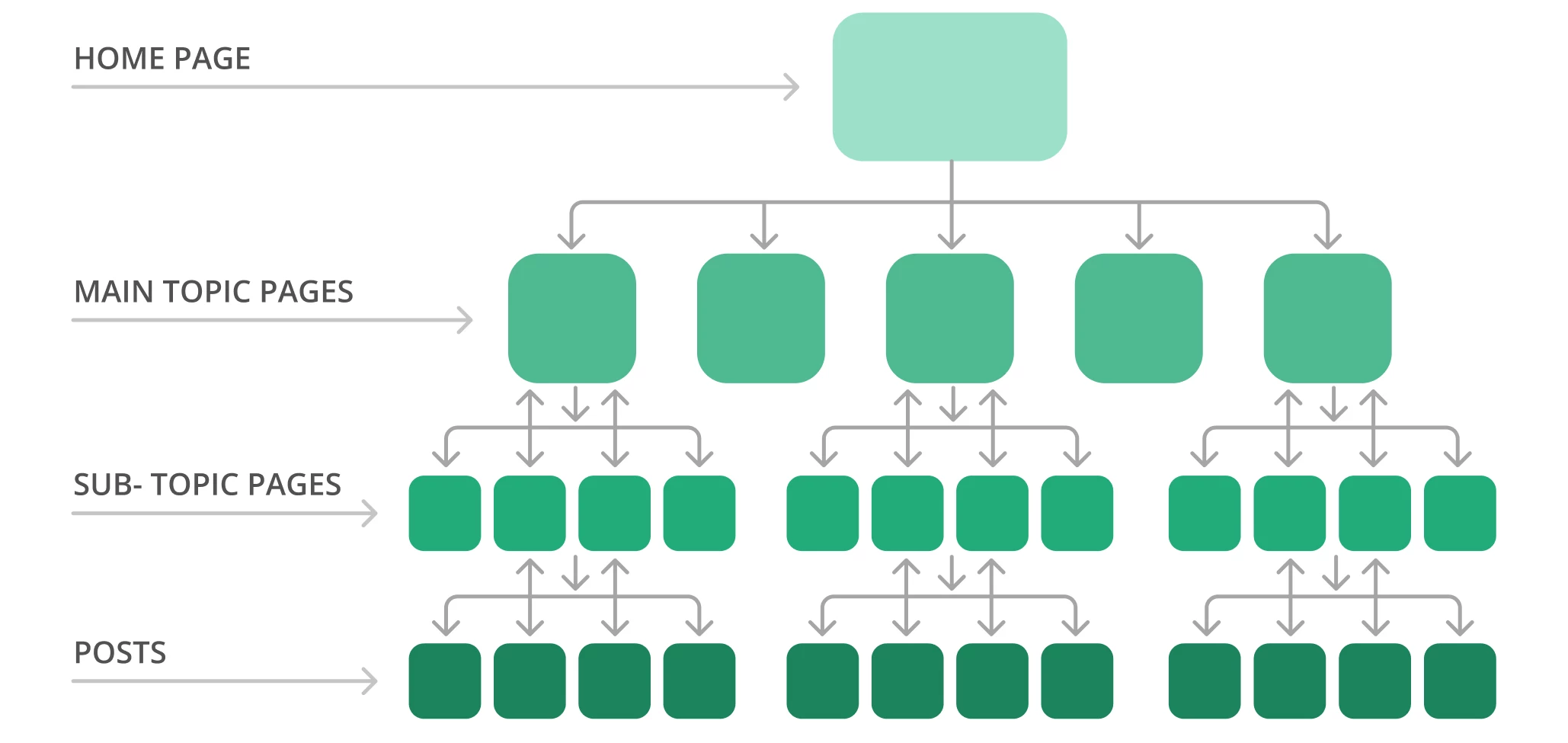
Di solito Google esegue il crawling del sito web dall’inizio della homepage fino alla fine. In altre parole, più le pagine sono lontane dall’alto, più i bot dei motori di ricerca le troveranno complesse, soprattutto se avete molte pagine orfane.
La soluzione
Ecco alcuni passaggi per ottimizzare l’architettura del sito:
Utilizzate Screaming Frog per verificare la struttura attuale del sito e la profondità di crawl.
Organizzate le pagine in modo logico in una gerarchia con collegamenti interni. Create le pagine cruciali con due o tre clic dalla homepage.
Create una struttura URL chiara. Rendetelo di facile lettura per i motori di ricerca e gli utenti, in modo da comprendere il contesto e la rilevanza di ogni pagina del vostro sito. Includete parole chiave mirate in ogni URL, ove possibile.
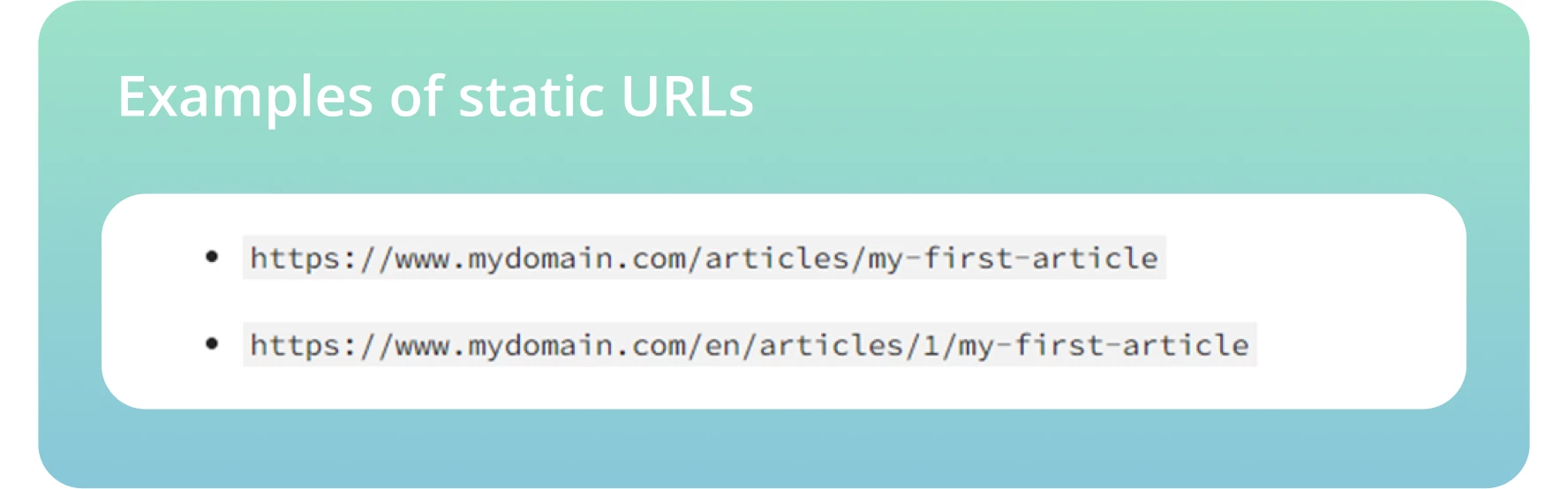
Utilizzate URL statici ed evitate quelli dinamici, compresi gli ID di sessione o altri parametri URL che rendono difficile il crawling e l’indicizzazione da parte dei bot.
Creare briciole di pane per aiutare Google a capire i siti e le persone a spostarsi rapidamente in avanti e indietro.

11. Cattiva gestione delle Sitemap
Le sitemap sono file XML contenenti informazioni importanti sulle pagine del sito. Indicano ai motori di ricerca quali sono le pagine importanti del sito che si desidera scansionare e indicizzare. Le sitemap contengono anche informazioni su immagini, video e altri file multimediali del sito. Ecco un esempio di sitemap:
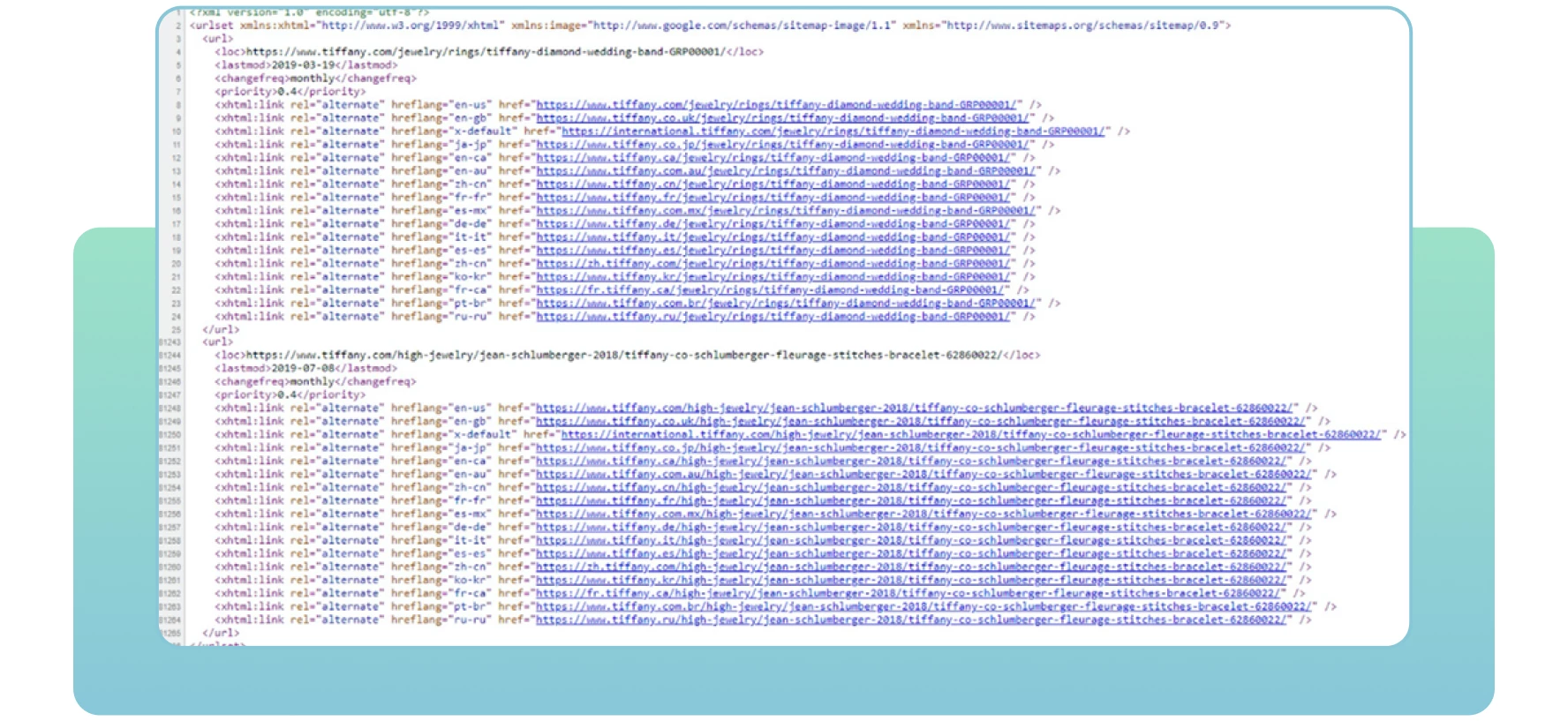
Con le sitemap, i motori di ricerca troveranno e indicizzeranno efficacemente le vostre pagine web essenziali. Se non si includono alcune pagine che si desidera indicizzare e classificare, i motori di ricerca potrebbero non notarle, con conseguenti problemi di crawlabilità e riduzione del traffico sul sito.
La soluzione
Ecco alcuni passi da considerare per quanto riguarda le sitemap:
Utilizzare lo strumento XML Sitemaps per creare o aggiornare una sitemap.
Assicuratevi che tutte le pagine necessarie siano incluse e che non vi siano errori del server che possano rendere difficile l’accesso ai web crawler.
Inviate la vostra sitemap a Google. Di solito è possibile trovarla seguendo l’URL del proprio sito, come illustrato di seguito: domain.com/sitemap.xml
Utilizzate Google Search Console per monitorare lo stato della vostra sitemap e verificare eventuali problemi.
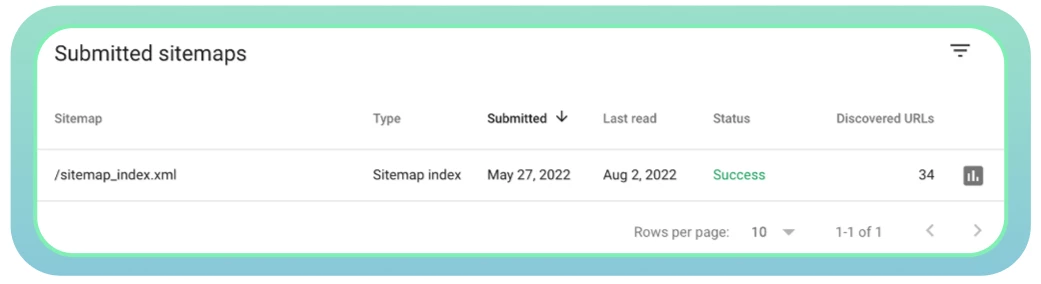
Assicuratevi di aggiornare la vostra sitemap quando vengono aggiunte o eliminate nuove pagine dal vostro sito web. Questo aiuterà i motori di ricerca a ottenere informazioni accurate su tutte le vostre pagine web.
Conclusione
Ci sono molte ragioni per cui alcune pagine sono nascoste a Google e non vengono classificate. In primo luogo, è necessario verificare se il vostro sito è privo di problemi di crawlability
Molti errori di crawl possono influire sulle prestazioni del sito web e indicare ai bot dei motori di ricerca che alcune pagine web non meritano di essere crawlate. Di conseguenza, Google non indicizzerà e classificherà le pagine cruciali a cui non possono accedere.
Per questo motivo è fondamentale individuare eventuali problemi di crawlability e fare del proprio meglio per risolverli. Implementando le soluzioni menzionate in precedenza, potrete ottimizzare il vostro sito per ottenere prestazioni migliori e aiutare i motori di ricerca e gli utenti a trovarlo facilmente.
Cari amici! Spero che l’articolo si sia rivelato interessante e sarei molto felice se vi fosse utile. A presto!




