
Wat is crawlbaarheid: 11 manieren om crawlfouten te herstellen
Hallo, mijn beste SEO-vrienden en -enthousiastelingen! Vandaag wil ik het hebben over crawlability, de meest voorkomende crawlability-problemen en oplossingen daarvoor. Deze belangrijke factor kan uw rankings, verkeer en zichtbaarheid van uw website in de zoekresultaten schaden. Laten we, voordat we in de crawlproblemen duiken, eerst uitzoeken wat crawlability is en hoe het SEO beïnvloedt.

Wat is crawlbaarheid?
In eenvoudige termen verwijst crawlability naar het vermogen van zoekmachine-bots om uw websitepagina’s te detecteren en correct te crawlen. Wat technische SEO betreft, is dit een belangrijk punt dat u moet controleren, want als Googlebot uw webpagina’s niet kan vinden, zullen ze nooit bovenaan de zoekmachineresultaten staan.
Merk op dat crawlability en indexability verschillende dingen zijn. De laatste verwijst naar het vermogen van zoekmachines om de inhoud die ze crawlen correct te vinden en toe te voegen aan hun index. Google toont alleen crawlable en indexeerbare webpagina’s in de zoekmachineresultaten.
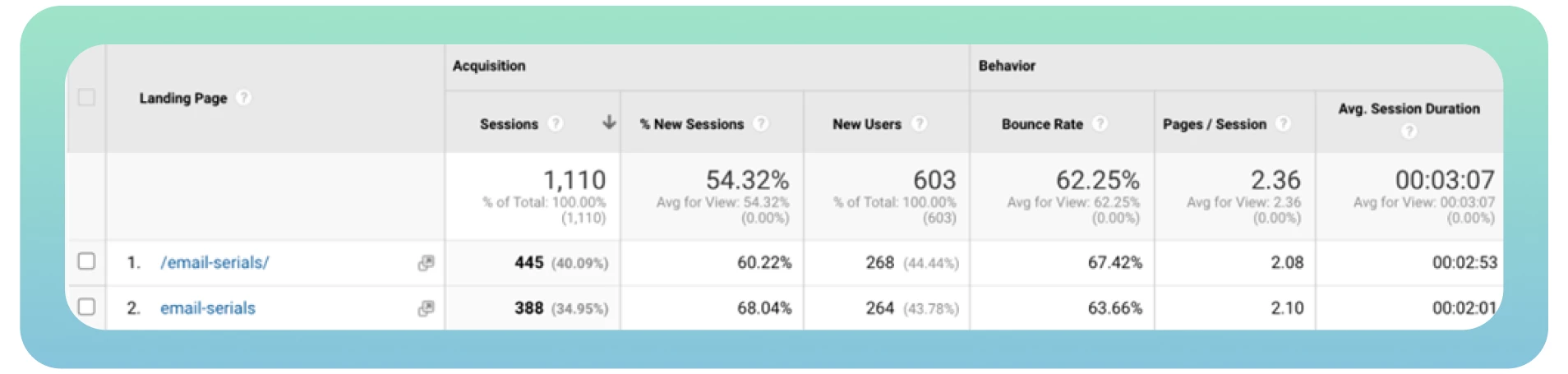
Om te weten hoeveel pagina’s op uw website zijn geïndexeerd, gaat u naar Google en typt u “site:” met de URL van de website. U kunt het onderstaande voorbeeld bekijken, maar als u wilt dat alles voor u wordt gedaan, kunt u het beste met ons outsourcen!
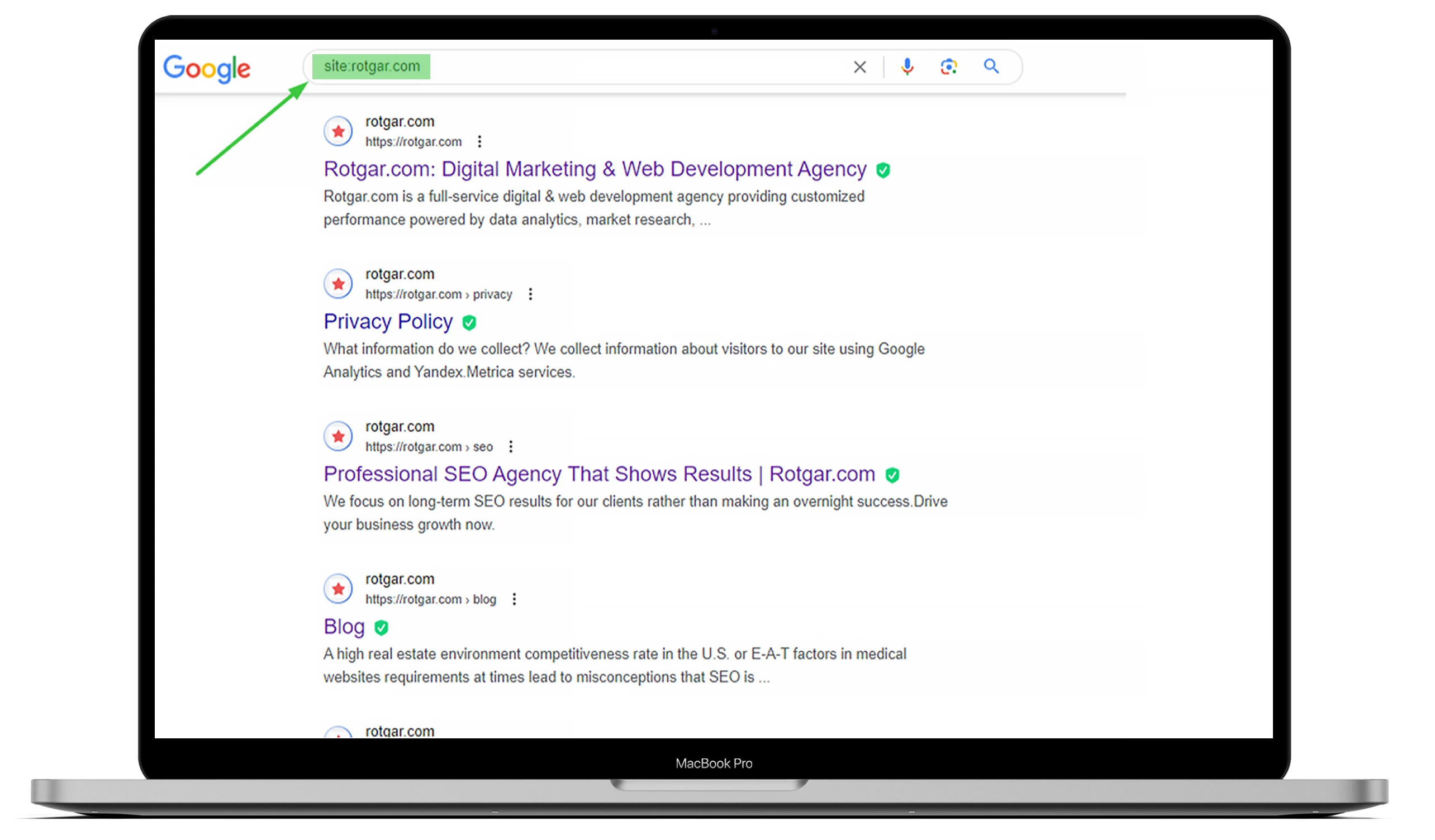
Je moet begrijpen dat zoekmachine bots, ook bekend als webcrawlers, altijd werken, de inhoud scannen en webpagina’s indexeren die ze vinden. Zodra een Googlebot een verandering detecteert, werkt hij de gegevens bij.
Veel dingen kunnen de crawlbaarheid van je website beïnvloeden, maar in dit artikel worden de meest voorkomende problemen uitgelegd.
De impact van crawlfouten op SEO
Als de bots van zoekmachines te maken krijgen met crawlproblemen op je website, kan dit je SEO aanzienlijk beïnvloeden. Uw webpagina’s worden niet weergegeven in de zoekresultaten als een Googlebot niet weet of de inhoud relevant is voor een specifieke zoekterm.
Dat betekent dat ze ze niet kunnen indexeren en dat kan leiden tot een verlies aan conversies en organisch verkeer. Daarom is het essentieel om crawlable- en indexeerbare pagina’s te hebben om hoog te scoren in zoekmachines. Met andere woorden, hoe beter uw website crawlablebaar is, hoe groter de kans dat uw pagina’s worden geïndexeerd en beter scoren in Google.
Hoe crawlfouten te vinden in Google Search Console
Nu weten we wat crawlability en crawlfouten zijn en hoe ze uw SEO beïnvloeden. Het is tijd om deze fouten snel te vinden via het dashboard. Zoals je misschien weet, verdeelt Google Search Console crawlfouten in twee secties: Sitefouten en URL-fouten. Het is een goede manier om fouten op site- en paginaniveau te onderscheiden.
Gewoonlijk worden sitefouten als urgenter beschouwd en vereisen ze onmiddellijke actie om schade aan de bruikbaarheid van je website te voorkomen. Ik adviseer 100% foutvrij in dit gedeelte.
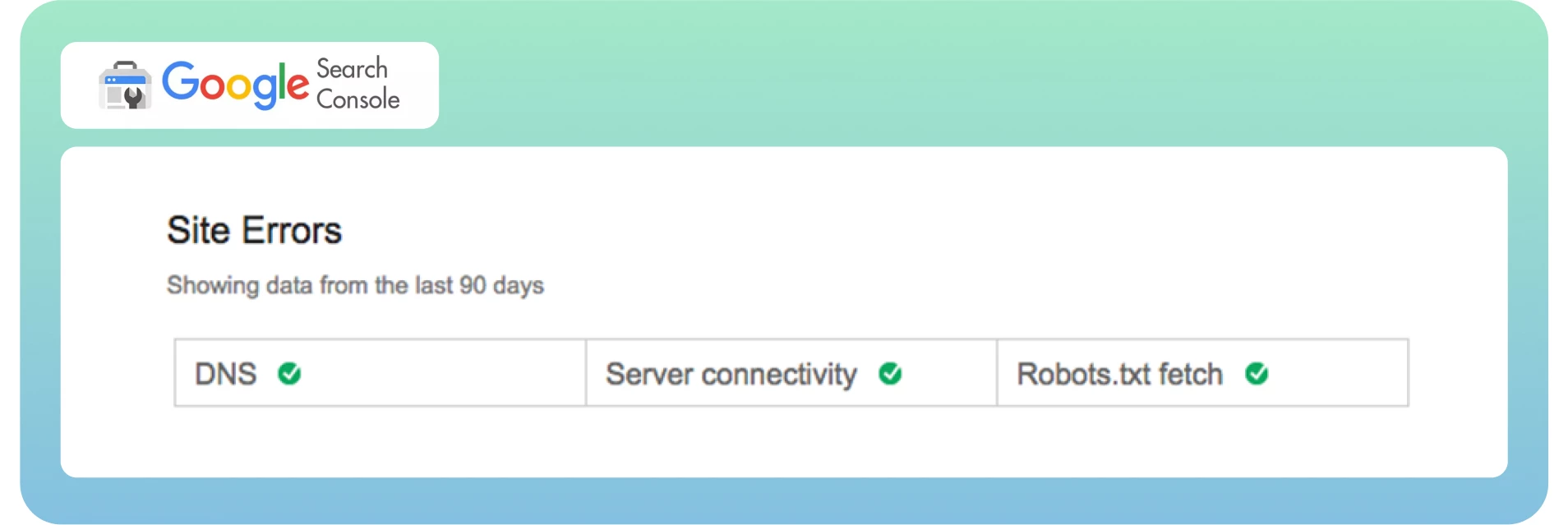
URL-fouten klinken minder catastrofaal en meer specifiek voor individuele webpagina’s, omdat deze fouten alleen invloed hebben op bepaalde pagina’s, niet op de hele website.
De beste manier om je crawlfouten te vinden is om naar het hoofddashboard te gaan, naar het gedeelte “Crawl” te gaan en op “Crawlfouten” te klikken.
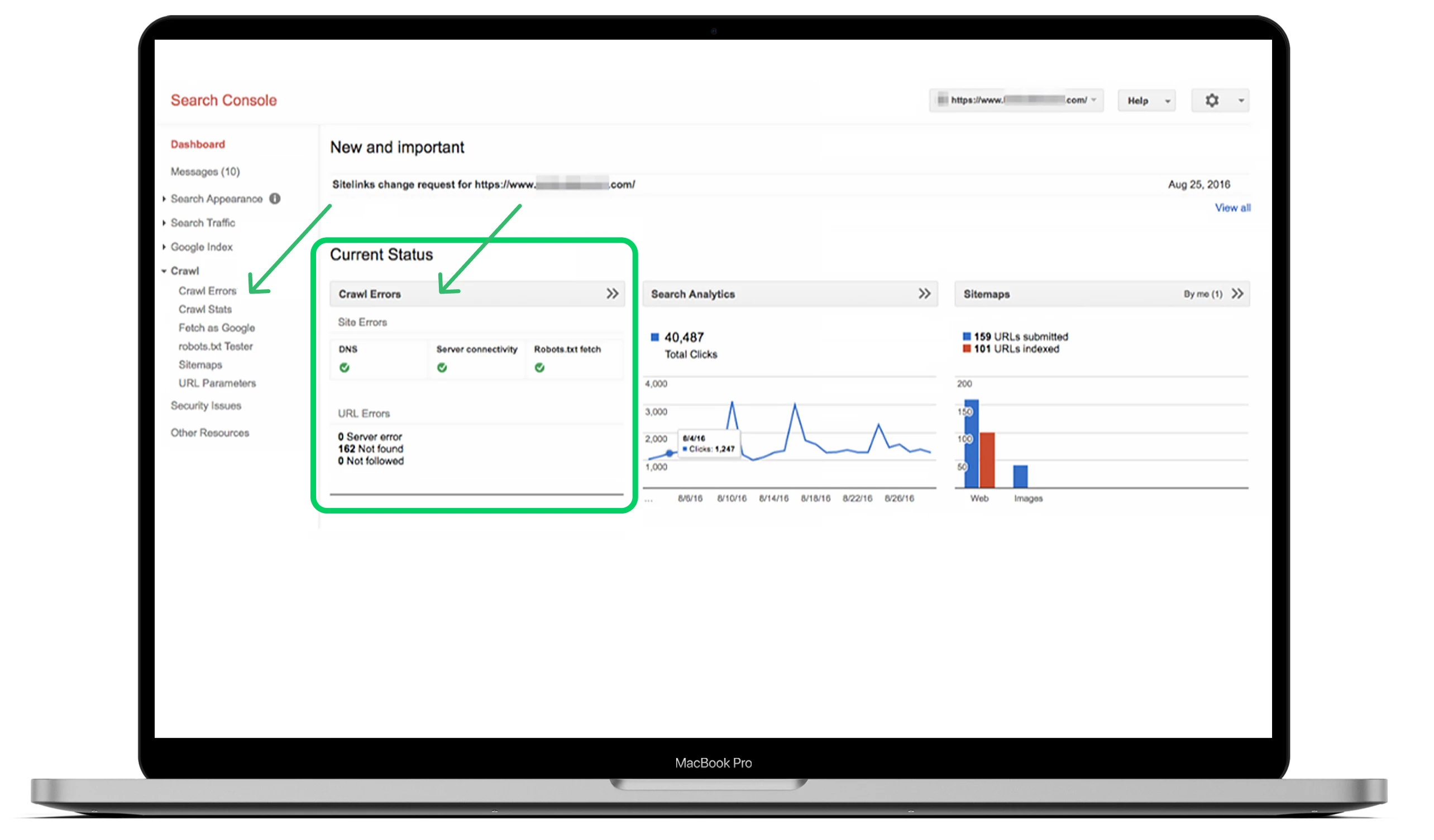
Idealiter moet u ten minste elke drie maanden controleren op crawlfouten om ernstige problemen te voorkomen en de gezondheid van uw site in de toekomst te behouden.
Top 10 crawlproblemen en hoe ze te verhelpen
Laten we nu eens kijken naar de meest voorkomende crawlproblemen en hun oplossingen om uw site dienovereenkomstig te optimaliseren.
1. 404-fouten
Een 404-fout is een van de meest complexe en eenvoudigste problemen van alle fouten tegelijk.
-In theorie verwijst een 404-fout naar het vermogen van de Googlebot om een specifieke pagina te crawlen die niet op uw website te vinden is.
-In de praktijk kun je veel pagina’s als 404 zien in Google Search Console.
Dit is wat Google zegt:

“404-fouten schaden de prestaties en rankings van je site in Google niet veel, dus je kunt ze veilig negeren.”
Het is essentieel om 404-fouten te herstellen wanneer je cruciale webpagina’s met deze problemen te maken hebben. Maak onderscheid tussen pagina’s om fouten te voorkomen en de oorzaak van het probleem te vinden. Dit laatste is echt belangrijk, vooral als de pagina belangrijke links krijgt van externe bronnen en veel organisch verkeer op je site heeft.
De oplossing
Hier volgen enkele stappen om belangrijke pagina’s met 404-fouten te herstellen:
Controleer of de 404-foutpagina correct is en afkomstig is van uw CMS, maar niet in conceptmodus staat.
Controleer op welke versie van uw site de fout verschijnt op WWW vs. niet-WWW en http vs. https.
Voeg een 301-omleiding toe naar de meest relevante pagina op uw site als u de pagina niet bijwerkt.
Als je pagina niet meer leeft, renoveer hem dan en maak hem weer levend.
Om al uw 404-foutpagina’s te vinden in Google Search Console, gaat u naar Crawlfouten -> URL-fouten en klikt u op alle links die u wilt herstellen:
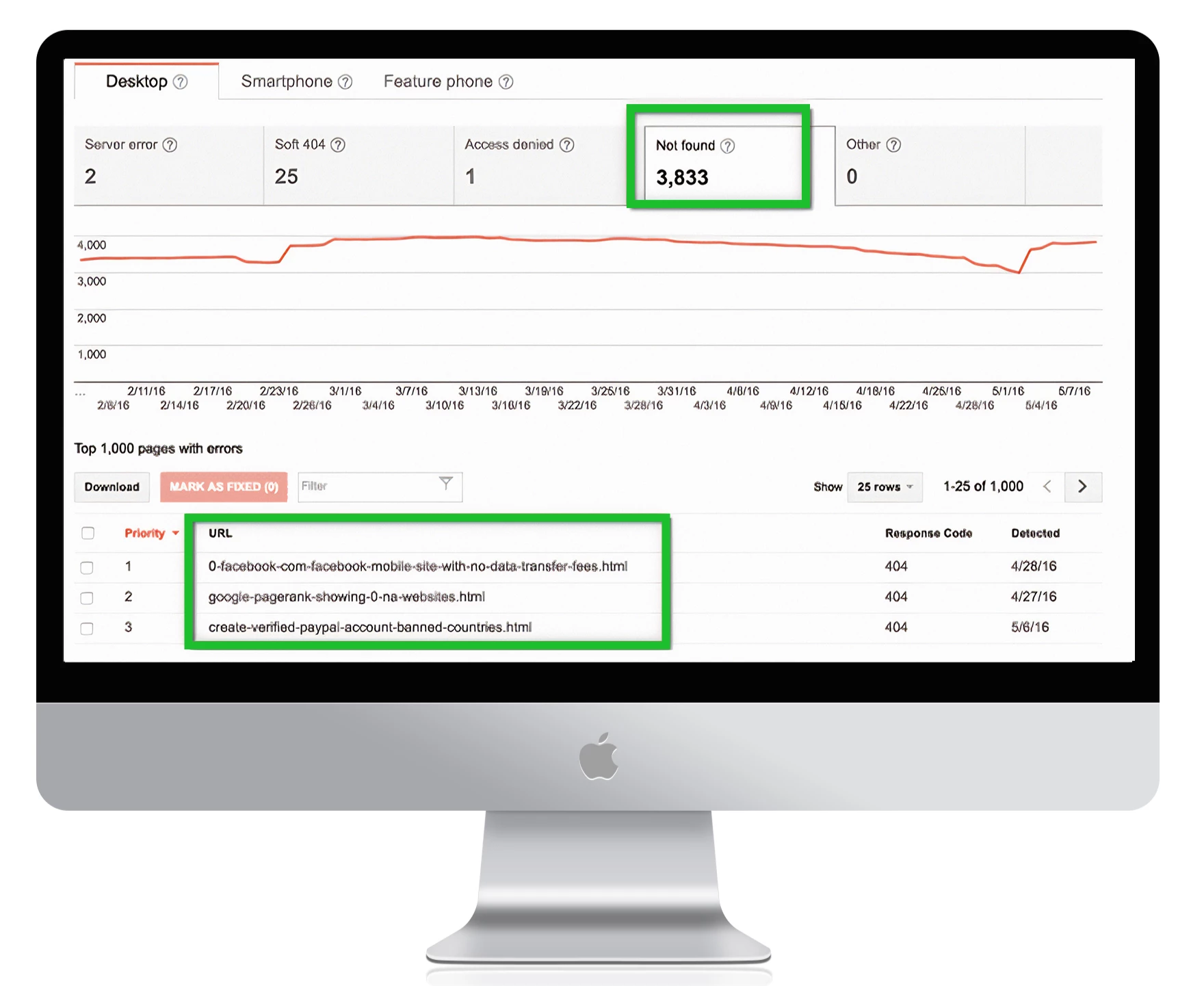
1. Let op:
als je een aangepaste 404-pagina hebt die geen 404-status retourneert, noteert Google deze als een zachte 404. Dat betekent dat de pagina niet genoeg nuttige inhoud heeft voor gebruikers en een 200-status retourneert. Technisch gezien bestaat de pagina wel, maar is deze leeg, waardoor de crawlprestaties van uw site afnemen.
Zachte 404-fouten kunnen website-eigenaren in verwarring brengen omdat ze eruit zien als een vreemde hybride van 404 en standaard webpagina’s. Zorg ervoor dat Googleblog de belangrijkste pagina’s van je website niet als zachte 404’s beschouwt.
2. Nofollow-links
Het kan een verwarrende fout zijn voor zoekmachines om de links op een websitepagina niet te crawlen. De nofollow-tag vertelt de Googlebot de links niet te volgen, wat leidt tot crawlbaarheidsproblemen op uw site. Zo ziet de tag eruit:
<meta name=”robots” content=”nofollow”.
In de meeste gevallen komen deze fouten doordat Google problemen heeft met Javascript, Flash, redirects, cookies of frames. Je moet je geen zorgen maken over het herstellen van de fout totdat er problemen zijn met URL’s met een hoge prioriteit. Als ze afkomstig zijn van oude URL’s die niet actief zijn of niet-geïndexeerde parameters die dienen als extra functie, zal de prioriteit lager zijn – maar je moet deze fouten nog steeds bekijken.
De oplossing
Hier zijn enkele stappen om niet gevolgde problemen op te lossen:
● Bekijk alle pagina’s met de nofollow-tags met behulp van de tool “Fetch as Google” om de site te bekijken zoals Googlebot dat zou doen.
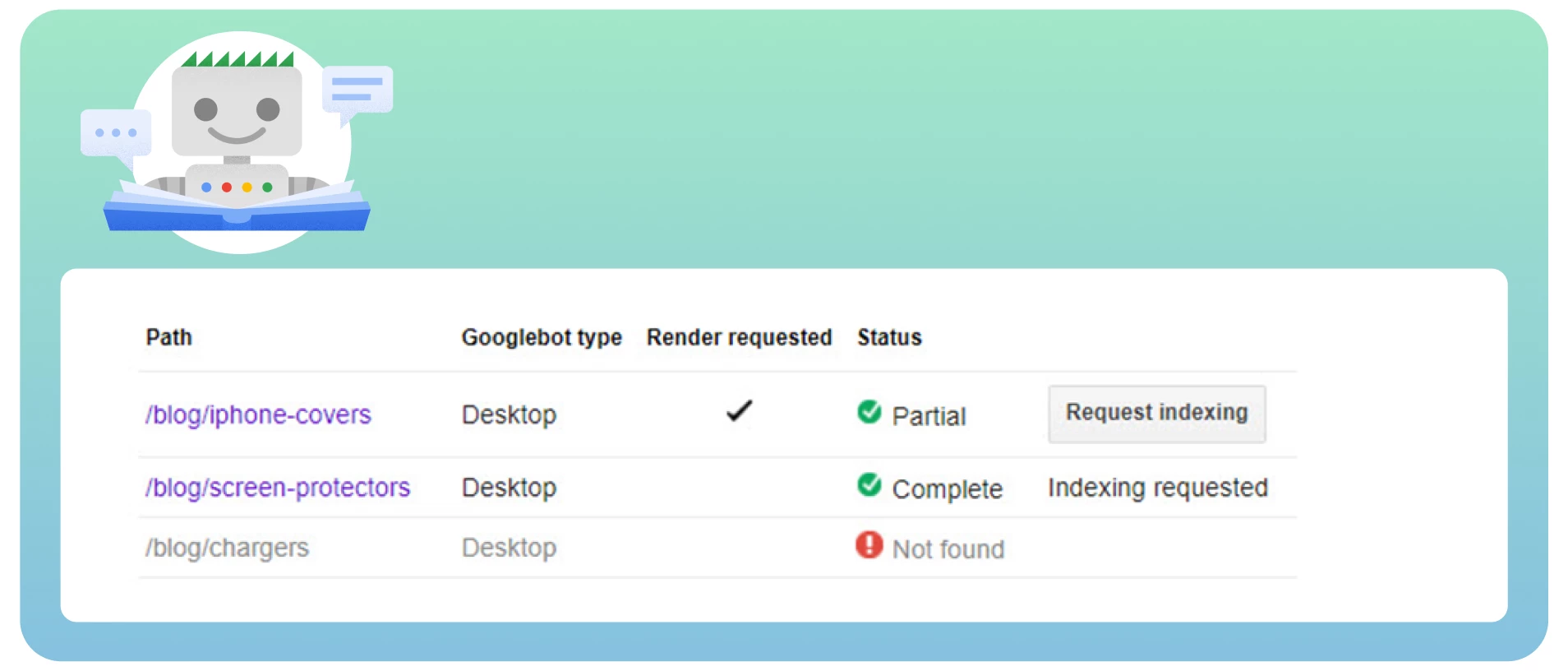
Controleer op redirect-ketens. Google kan stoppen met het volgen van redirects als u veel lussen hebt.
Neem de bestemmings-URL, niet de omgeleide URL’s, op in de sitemap.
Verbeter de architectuur van uw site zodat elke pagina op uw site kan worden bereikt via statische links.
Verwijder de nofollow-tags van de pagina’s waar ze niet horen te staan.
3. Geblokkeerde pagina’s
Wanneer de bots van zoekmachines uw website crawlen, controleren ze eerst uw robots.txt-bestand. Dit bestand geeft aan welke webpagina’s ze wel en niet moeten crawlen. Hieronder ziet u een voorbeeld van het robots.txt-bestand waaruit blijkt dat uw website geblokkeerd is voor crawling:
User-agent: *
Niet toestaan: /
Helaas is dit een van de meest voorkomende problemen die de crawlbaarheid van uw website beïnvloeden en cruciale webpagina’s blokkeren. Om dit probleem op te lossen, moet u de richtlijn in dit bestand wijzigen in “Allow”, waardoor zoekmachine-bots de hele website kunnen crawlen.
User-agent: *
Toestaan: /
Als u uw eigen blog maakt, is het essentieel dat u deze openstelt voor crawling en indexering om alle potentiële SEO-voordelen te krijgen nadat u deze hebt overgezet naar uw hoofdwebsite. Gebruik gewoon de richtlijn Disallow: /blog* in het onderstaande voorbeeld:
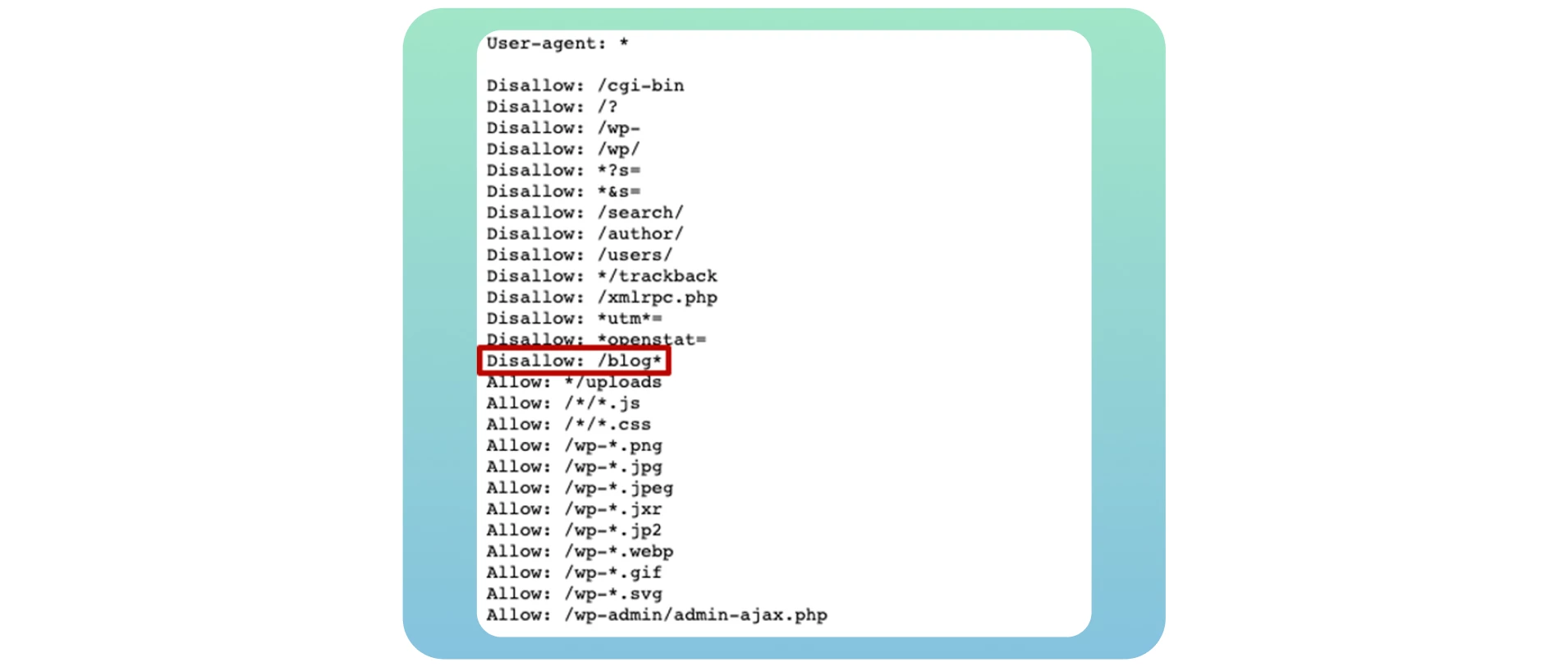
Veel website-eigenaren bloggen specifieke pagina’s in dit bestand wanneer ze willen voorkomen dat deze in de zoekresultaten worden weergegeven. In de meeste gevallen verwijst dit naar aanmeldings- en bedankpagina’s. Maar het is geen crawlablity-probleem omdat je niet wilt dat ze zichtbaar zijn in de zoekmachineresultaten. Het vinden van een typfout of een fout in de regexcode zal leiden tot ernstigere problemen op uw site.
De oplossing
Als u uw pagina crawlablebaar wilt maken, zorg er dan voor dat u dit toestaat in de robot.txt. Controleer je bestand met de robots.txt tester om eventuele problemen en waarschuwingen te vinden en test specifieke URL’s in je bestand.
Je kunt ook eventuele robots.txt-fouten opsporen met behulp van een website-audit. Gelukkig zijn er veel waardevolle tools om een technische SEO-audit uit te voeren, zoals Screaming Frog of Semrush. Maar eerst moet je je registreren en je site toevoegen om resultaten te krijgen.
4. ‘Noidex’ tags
“Noindex” tags vertellen zoekmachines welke pagina’s ze niet hoeven te indexeren. Hieronder ziet de tag eruit:
<meta name=”robots” content=”nodiex”.
Het hebben van “noindex”-tags op uw website kan de crawlbaarheid en indexeerbaarheid van zoekmachines beïnvloeden als u deze lange tijd op uw webpagina’s laat staan. Bij de livegang vergeten webontwikkelaars vaak om de “noindex”-tag van de website te verwijderen.
Google beschouwt “noindex”-tags als “nofollow” en stopt met het crawlen van de links op die pagina’s. Het is gebruikelijk om een “noindex”-tag op te nemen op bedank-, aanmeld- en beheerpagina’s om te voorkomen dat Google deze indexeert. In andere gevallen is het tijd om deze tags te verwijderen als je wilt dat zoekmachine bots je pagina’s crawlen.
De oplossing
Hier zijn enkele stappen om “noindex” problemen op te lossen:
● Analyseer uw crawlstatistieken in Google Search Console om te bepalen hoe vaak de Googlebot uw website bezoekt.
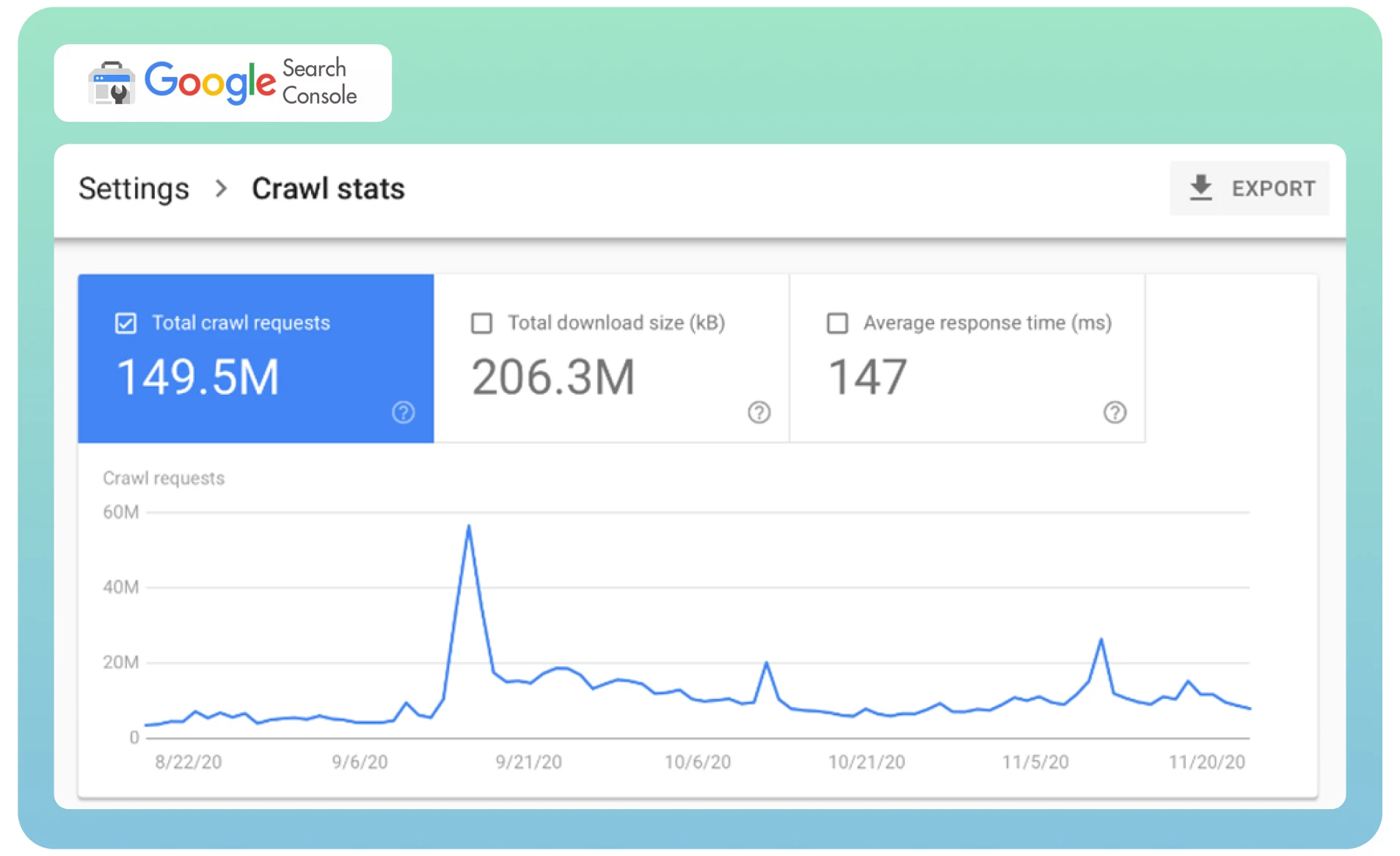
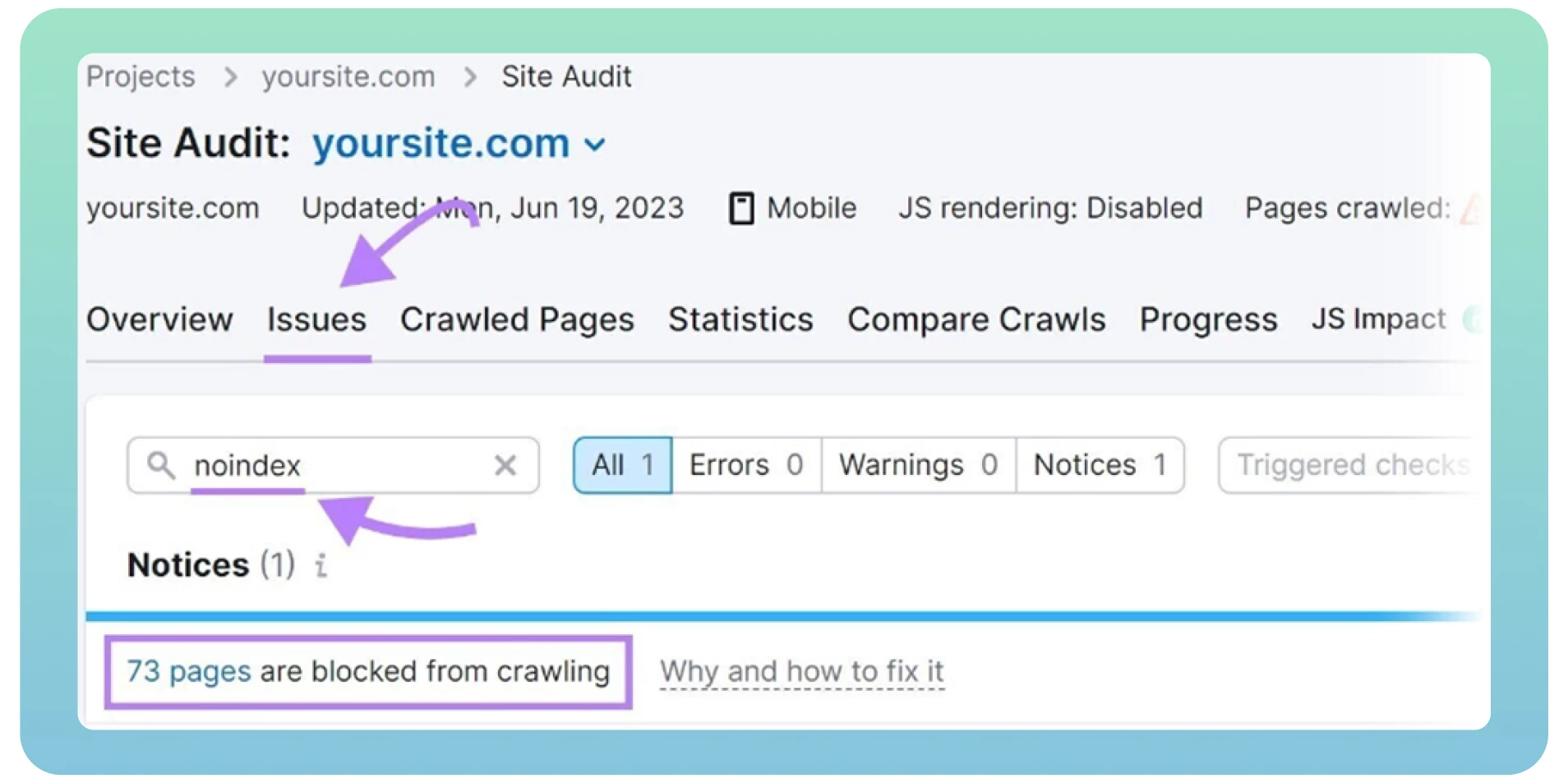
Vraag Google om uw pagina opnieuw te crawlen met de Removals-tool om de reeds geïndexeerde pagina direct uit de SERP’s te verwijderen. Dat kan enige tijd duren.
Gebruik een website-auditprogramma zoals Semrush om pagina’s met “noindex”-tags op te sporen. Het toont een lijst met pagina’s op uw site, bekijkt ze en verwijdert ze waar nodig.
5. Pagina duplicaten
Vaak kunnen verschillende webpagina’s met dezelfde inhoud worden geladen vanaf verschillende URL’s, wat resulteert in paginaduplicatie. U hebt bijvoorbeeld twee versies van uw domein (www en niet-www) die leiden naar de startpagina van uw site. Deze pagina’s hebben geen invloed op de bezoekers van uw website, maar ze kunnen wel de perceptie van uw website door zoekmachines beïnvloeden.
Het ergste is dat zoekmachines niet kunnen bepalen welke pagina ze als topprioriteit moeten beschouwen vanwege duplicate content. De Googlebot crawlt elke pagina snel en zal dezelfde inhoud opnieuw indexeren.
Idealiter zou de bot elke pagina slechts één keer moeten crawlen en indexeren. Bovendien krijgen verschillende versies van dezelfde pagina organisch verkeer en paginaranking, waardoor het analyseren van verkeersstatistieken in Google Analytics ingewikkeld wordt.
De oplossing
Canonicalisatie is de meest geprefereerde manier om duplicaten SEO-autoriteit te laten behouden. Hier zijn enkele tips om te overwegen:
● Gebruik canonical tags om Google gemakkelijk te vertellen wat de originele URL van een pagina is. Zo zou de link met deze tag er hieronder uit moeten zien:
<link rel=”canonical” href=”https://example.com/page/” />
Controleer de waarschuwingen in Google Search Console – het kan iets zijn als “Te veel URL’s” of soortgelijke taal wanneer Google meer URL’s en inhoud tegenkomt dan zou moeten.
Gebruik canonical en noindex tags niet tegelijkertijd, omdat zoekmachine bots canonical webpagina’s als duplicaten kunnen beschouwen.
Canonicaliseer naar de “Alles weergeven” pagina.
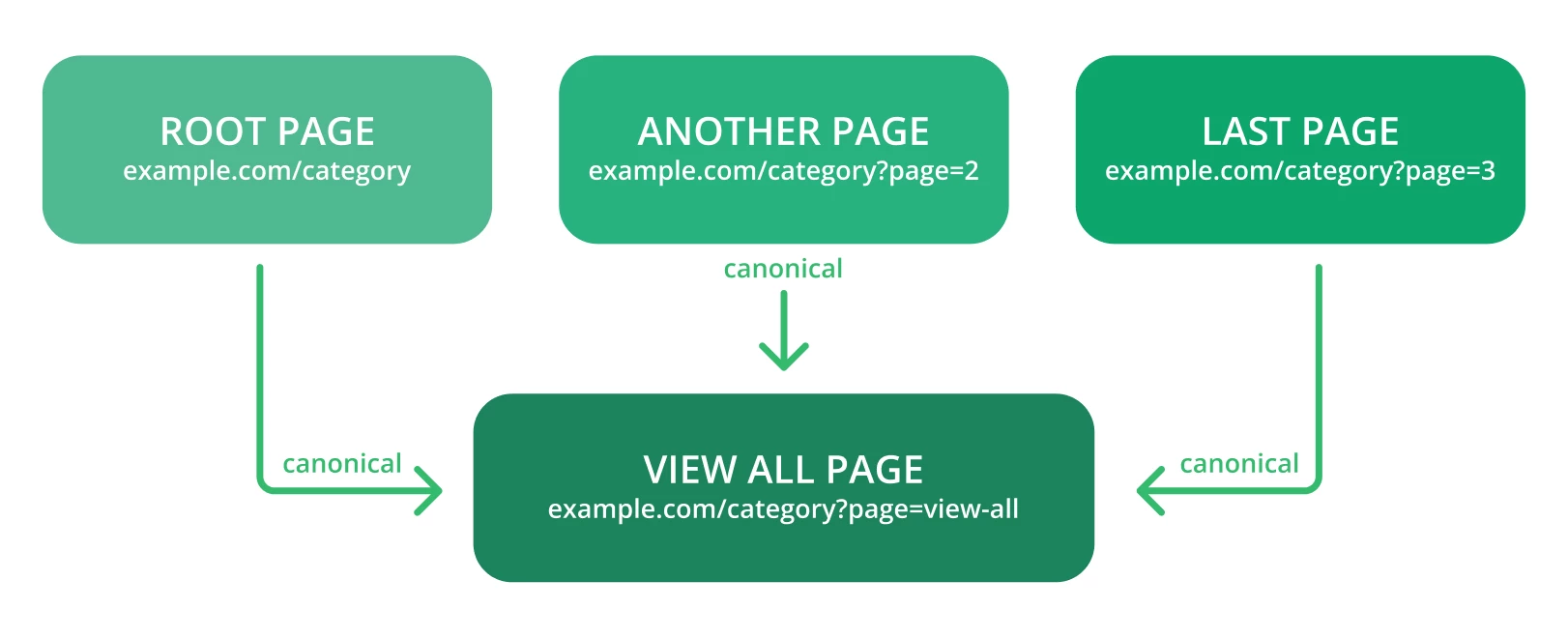
Canonicaliseer elke URL die is gemaakt door facetnavigatie
6. Trage laadsnelheid
De laadsnelheid van pagina’s is een van de meest kritieke factoren die de crawlbaarheid van uw website beïnvloeden. Een trage laadsnelheid kan een slechte gebruikerservaring opleveren en het aantal pagina’s dat zoekmachine-bots kunnen crawlen binnen een crawl-sessie verminderen. Dat kan ertoe leiden dat cruciale webpagina’s niet worden gecrawld.
Met andere woorden, hoe sneller uw webpagina’s laden, hoe sneller de Googlebot de inhoud op de site kan crawlen en beter kan scoren in de zoekresultaten. Daarom is het verbeteren van de algehele prestaties en snelheid van uw website essentieel.
De oplossing
Hier zijn enkele nuttige tips die u in overweging moet nemen bij het optimaliseren van de snelheid van uw website:
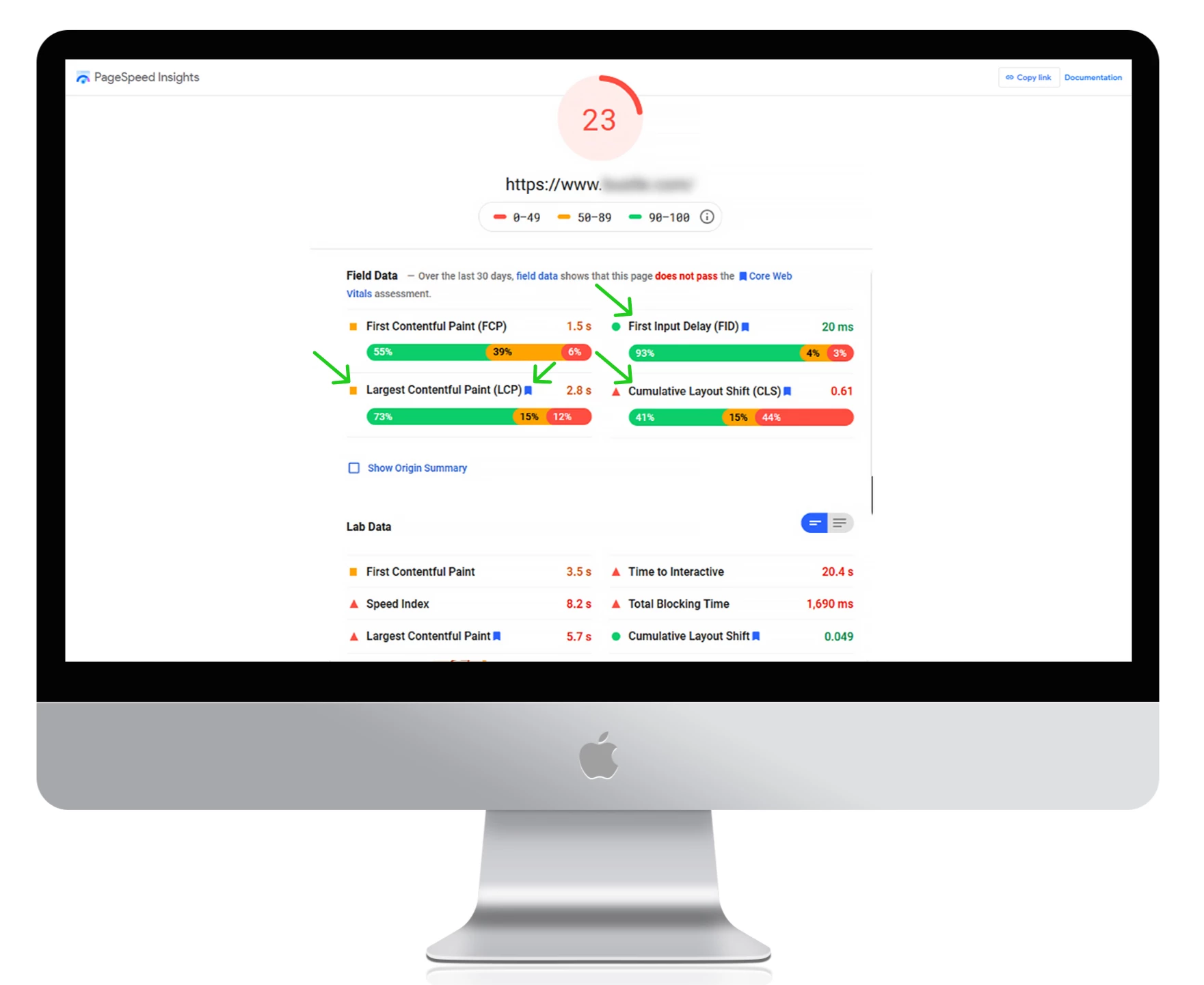
● Gebruik Google PageSpeed Insights om uw huidige laadtijden te meten, mogelijke fouten op te sporen en bruikbare tips te krijgen voor het verbeteren van de websiteprestaties.
Gebruik een content delivery network (CDN) om uw content om te leiden naar verschillende servers wereldwijd. Dit vermindert de latentie en zorgt ervoor dat je website sneller werkt.
Kies een snelle webhostingprovider.
Comprimeer afbeeldingen en videobestanden om de laadsnelheid te verhogen.
Verwijder onnodige plugins en verminder het aantal CSS- en JacaScript-bestanden op je site.
7. Gebrek aan interne links
Webpagina’s met een gebrek aan interne links kunnen te maken krijgen met crawlbaarheidsproblemen. Interne links verwijzen naar het linken van een pagina naar een andere relevante pagina binnen hetzelfde domein. Ze helpen gebruikers eenvoudig te navigeren binnen uw website en voorzien zoekmachines van nuttige informatie over uw structuur en hiërarchie.
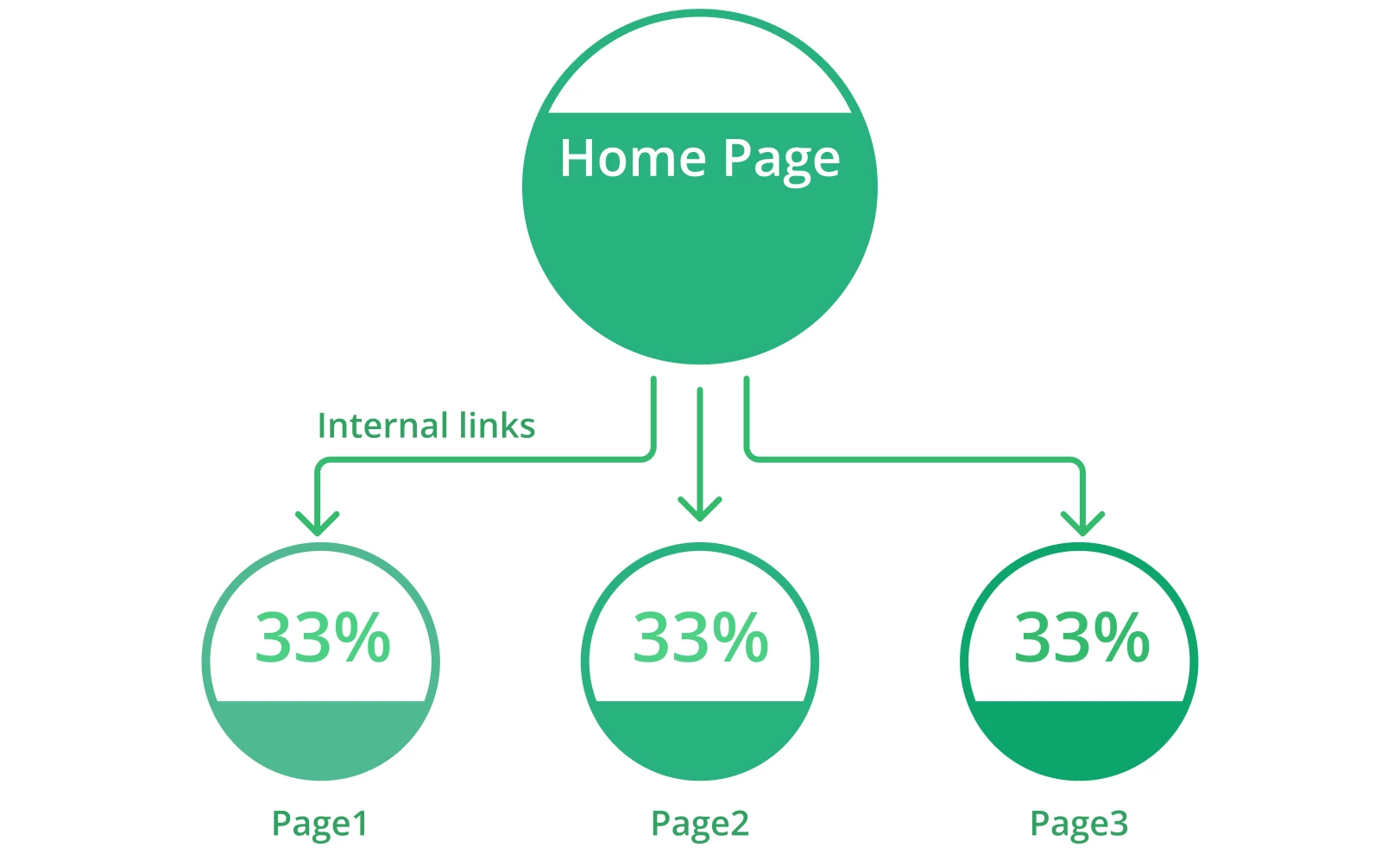
Elke pagina op uw site moet ten minste één interne link hebben. Dat laat zoekmachines zien dat uw pagina’s onderling gerelateerd en verbonden zijn. Geïsoleerde pagina’s maken het moeilijk voor bots om ze als onderdeel van uw site te beschouwen. Hoe meer relevante interne links u hebt, hoe gemakkelijker en sneller de bots de hele website crawlen.
De oplossing
Hier zijn een aantal bruikbare tips om te overwegen:
● Voer een SEO-audit uit om te bepalen waar je meer interne links van relevante pagina’s op je site kunt toevoegen.
Bekijk de analytics van de website om te zien hoe gebruikers door de site stromen en zoek manieren om ze te betrekken bij uw relevante inhoud. Kijk uit naar pagina’s met een hoog bouncepercentage om deze te verbeteren en meer inhoud van hoge kwaliteit toe te voegen.
Geef cruciale pagina’s prioriteit door ze hoger in de websitehiërarchie te plaatsen en meer interne links toe te voegen die naar deze pagina’s leiden.
Voeg beschrijvende ankerteksten toe om de inhoud van de gelinkte pagina’s weer te geven.
Werk uw oude URL’s bij of verwijder gebroken links. Zorg ervoor dat elke koppeling relevant en actief is op uw site.
Controleer en verwijder eventuele typefouten in de URL’s die u op uw webpagina’s vermeldt.
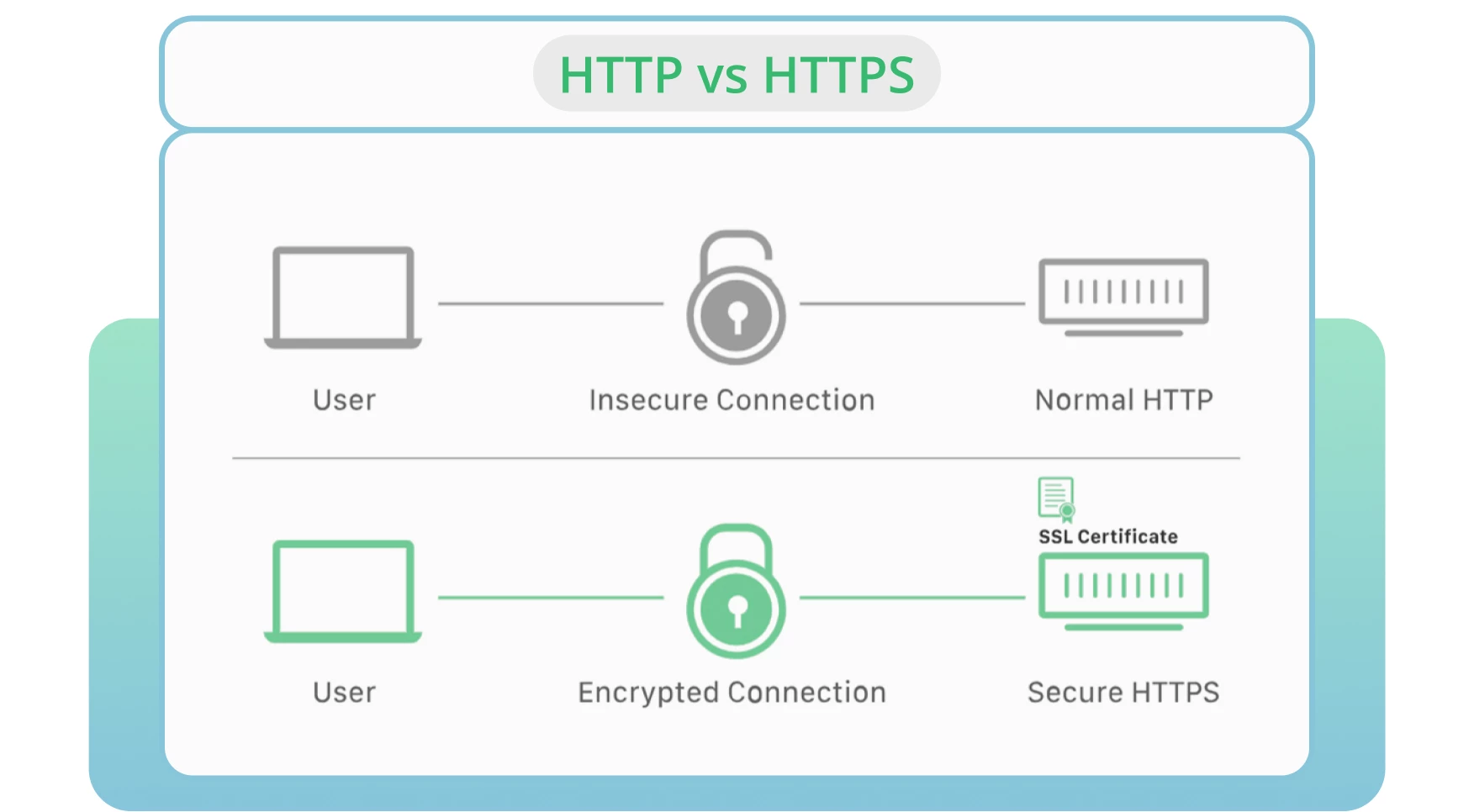
8. HTTP gebruiken in plaats van HTTPS
Serverbeveiliging blijft een van de belangrijkste factoren bij crawlen en indexeren. HTTP is het standaardprotocol waarmee gegevens van een webserver naar een browser worden verzonden. HTTPS wordt beschouwd als het veiligste alternatief voor de HTTP-versie.
In de meeste gevallen verkiezen browsers HTTPS-pagina’s boven HTTP-pagina’s. Dit laatste heeft een negatieve invloed op de site rankings en crawlbaarheid.
De oplossing
Neem een SSL-certificaat om Google te helpen je website snel te crawlen en een veilige en versleutelde verbinding te onderhouden tussen je website en gebruikers.
Schakel uw website in op de HTTPS-versie.
Bewaak en update beveiligingsprotocollen. Vermijd verlopen SSL-certificaten, oude protocolversies of onjuiste registratie van uw websitegegevens.
9. Redirect-lussen
Redirects zijn essentieel wanneer u uw oude URL naar een nieuwe, relevante pagina moet leiden. Helaas komen problemen met redirects, zoals redirect loops, vaak voor. Dat kan gebruikers van streek maken en zoekmachines ervan weerhouden je pagina’s te crawlen.
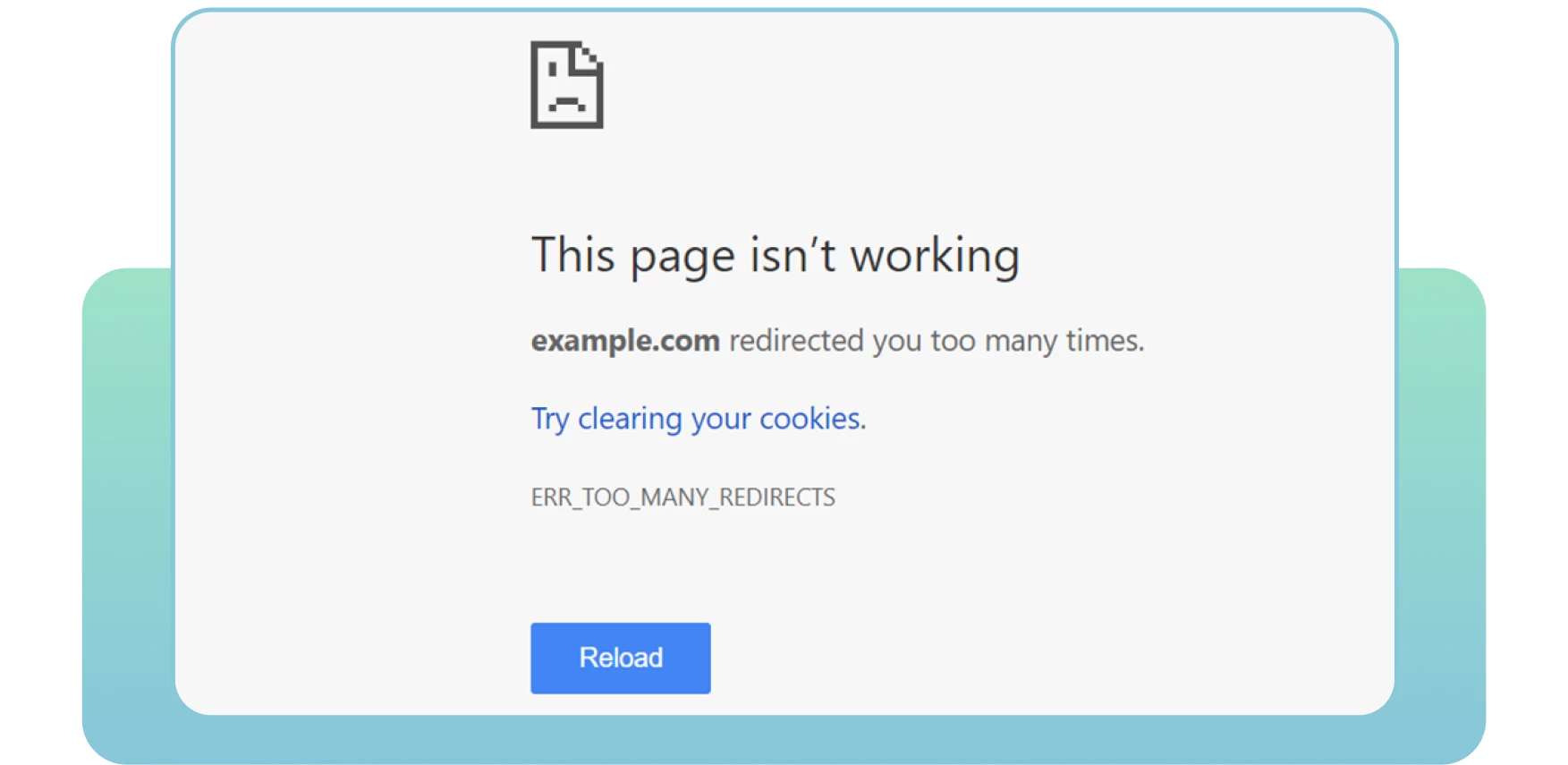
Er is sprake van een redirect-lus als een URL wordt omgeleid naar een andere URL en vervolgens terugkeert naar de oorspronkelijke URL. Dit probleem vormt een oneindige cyclus van omleidingen tussen twee of meer pagina’s voor zoekmachines. Dit kan gevolgen hebben voor uw crawlbudget en het crawlen van uw belangrijke pagina’s.
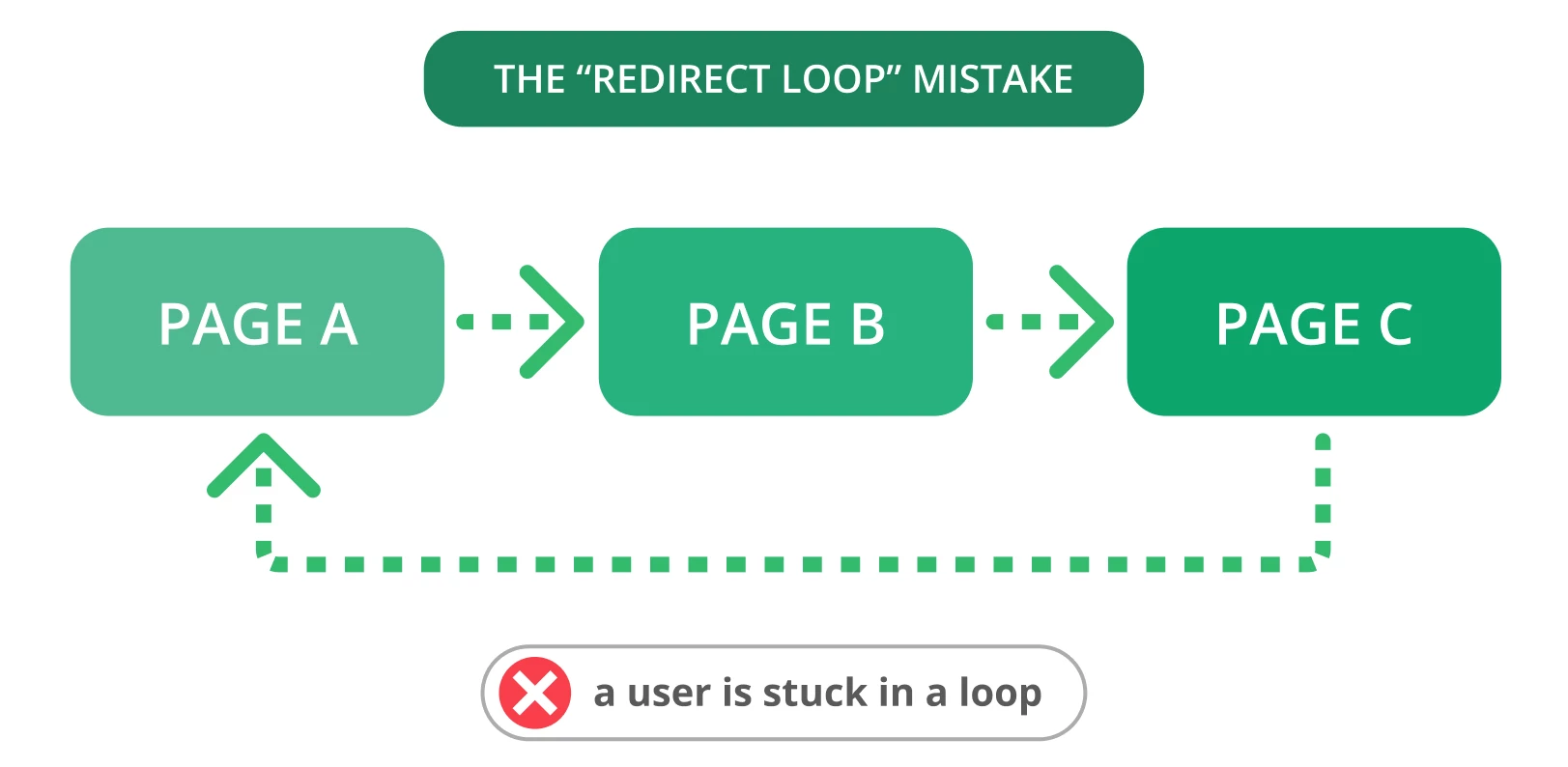
De oplossing
Hier zijn enkele stappen om redirect loops te verhelpen:
Gebruik HTTP Status Checker om snel redirect-ketens en HTTP-statuscodes te vinden.
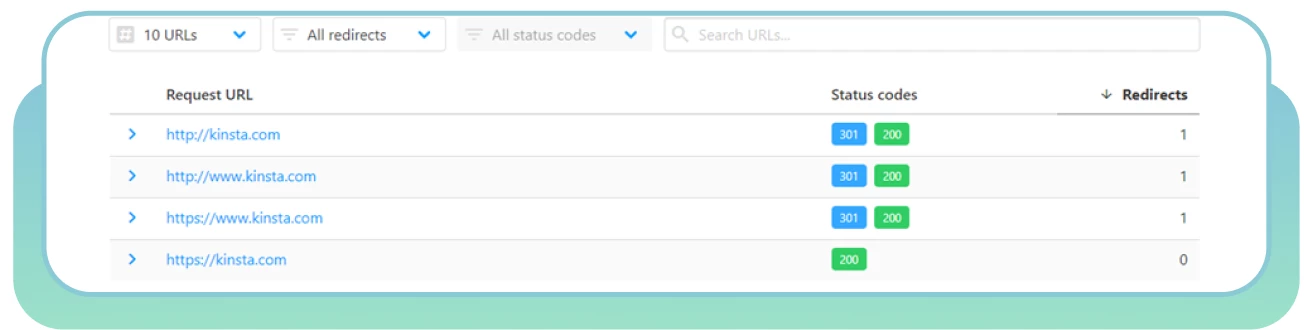
Kies de “juiste” pagina en redirect andere pagina’s daarheen.
Verwijder de redirect die de lus veroorzaakt.
Markeer de pagina’s met een 403 statuscode als nofollow om je crawlbudget te optimaliseren. Deze pagina’s kunnen alleen worden gebruikt voor geregistreerde gebruikers.
Gebruik tijdelijke redirects om zoekmachine bots te vertellen dat ze terug moeten keren naar je pagina. Gebruik een permanente redirect als je de oorspronkelijke pagina niet langer wilt indexeren.
10. Slechte website-architectuur
Het organiseren van de pagina’s en inhoud van uw website is een van de meest kritieke factoren bij het optimaliseren van de crawlbaarheid. Een slechte site-architectuur creëert crawlfouten voor webcrawlers om webpagina’s te ontdekken die laag in de hiërarchie staan of niet gelinkt zijn (bekend als “weespagina’s”).
Een goed gestructureerde site kan zoekmachines helpen om alle pagina’s gemakkelijk te vinden en te openen, wat uw prestaties en SEO positief kan beïnvloeden. Een ideale sitestructuur betekent dat elke pagina slechts een paar klikken verwijderd is van de startpagina, zonder verweesde pagina’s.
Een typische sitestructuur kan er bijvoorbeeld uitzien als een piramide. U hebt de startpagina bovenaan, met verschillende lagen die verwijzen naar de pagina’s met het hoofdthema die naar pagina’s met subonderwerpen leiden. Hieronder ziet u een voorbeeld van een sitestructuur.
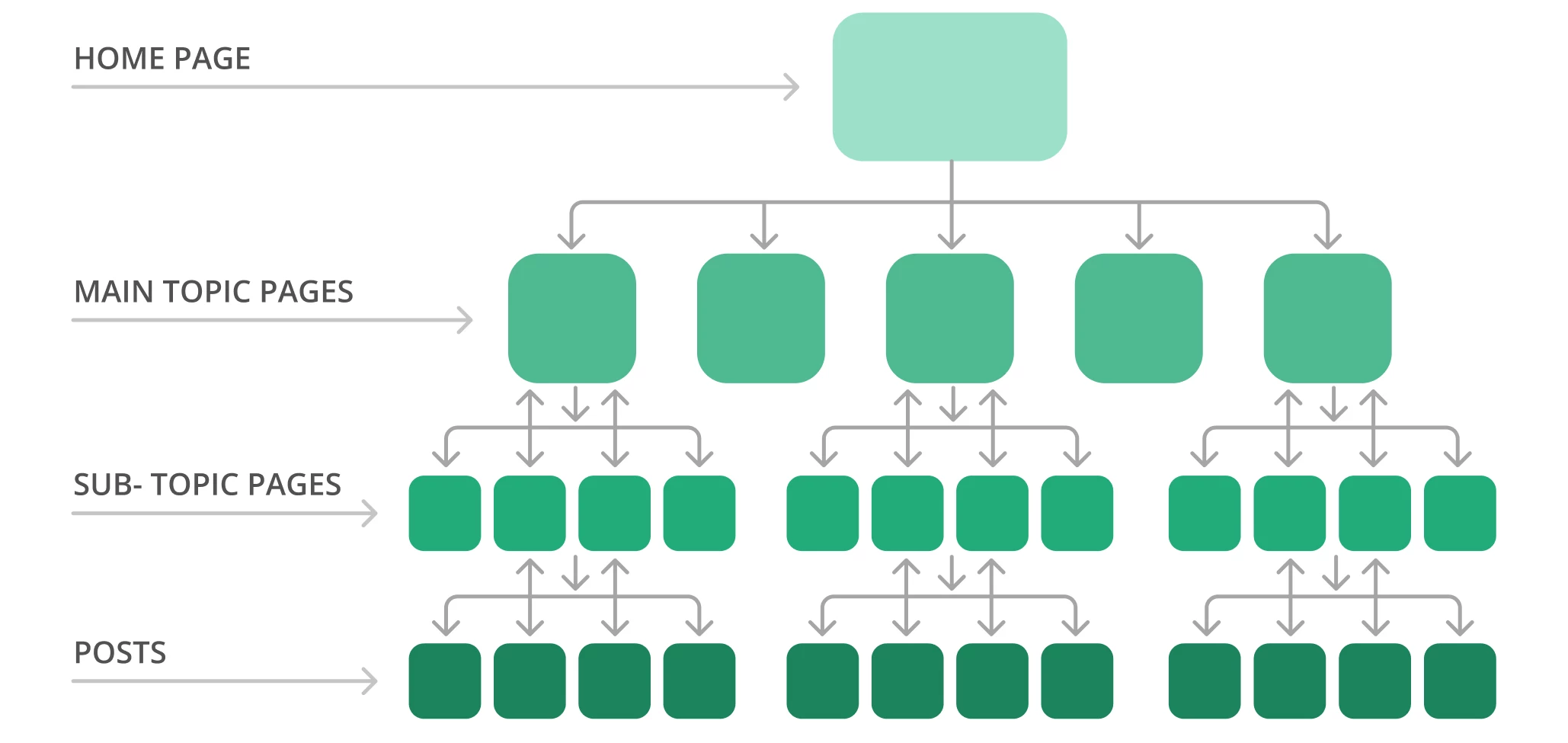
Google crawlt de website meestal van de bovenkant van de homepage naar de onderkant. Met andere woorden, hoe verder uw pagina’s van de top staan, hoe complexer de zoekmachine-bots ze zullen vinden, vooral als u veel weespagina’s hebt.
De oplossing
Hier volgen enkele stappen om de architectuur van uw site te optimaliseren:
Gebruik Screaming Frog om uw huidige sitestructuur en crawldiepte te controleren.
Organiseer uw pagina’s logisch in een hiërarchie met interne links. Maak uw cruciale pagina’s met twee of drie klikken toegankelijk vanaf de startpagina.
Maak een duidelijke URL-structuur. Maak het gemakkelijk leesbaar voor zoekmachines en gebruikers om de context en relevantie van elke pagina op je site te begrijpen. Neem waar mogelijk trefwoorden op in elke URL.
Gebruik statische URL’s en vermijd het gebruik van dynamische URL’s, inclusief sessie-ID’s of andere URL-parameters die het voor bots moeilijk maken om te crawlen en te indexeren.
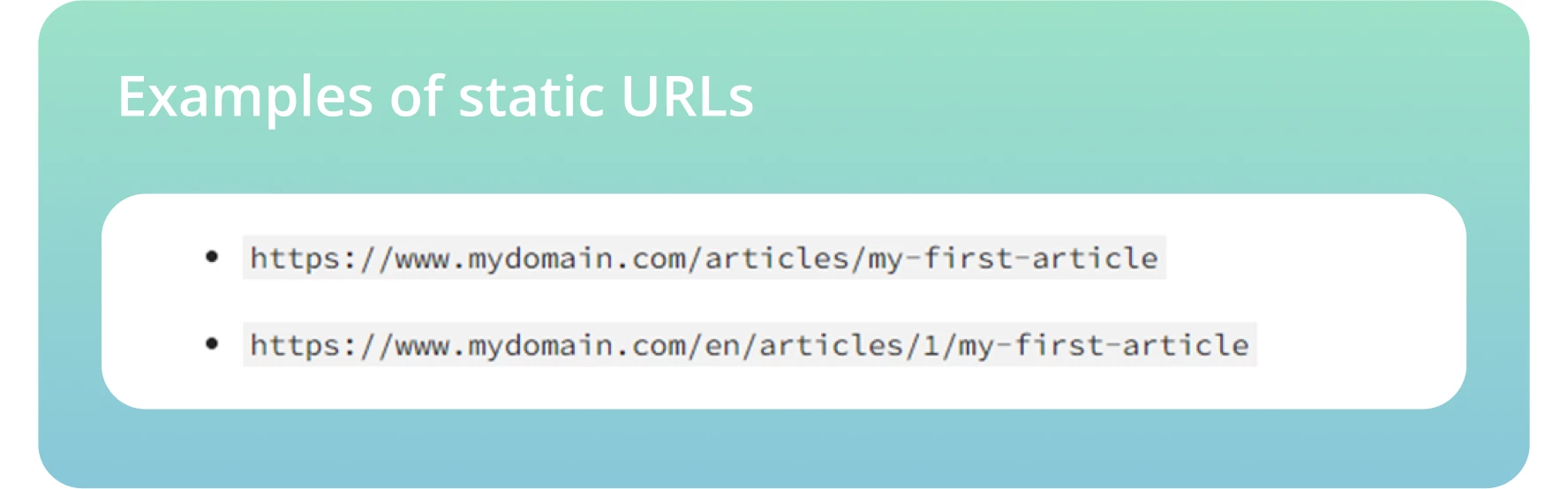
● Maak breadcrumbs om Google te helpen uw sites te begrijpen en mensen snel vooruit en achteruit te laten gaan.

11. Slecht Sitemap-beheer
Sitemaps zijn XML-bestanden met belangrijke informatie over de pagina’s van uw site. Ze vertellen zoekmachines welke pagina’s belangrijk zijn op de site die u wilt crawlen en indexeren. Sitemaps bevatten ook informatie over de afbeeldingen, video’s en andere mediabestanden op uw site. Hieronder ziet u een voorbeeld van een sitemap:
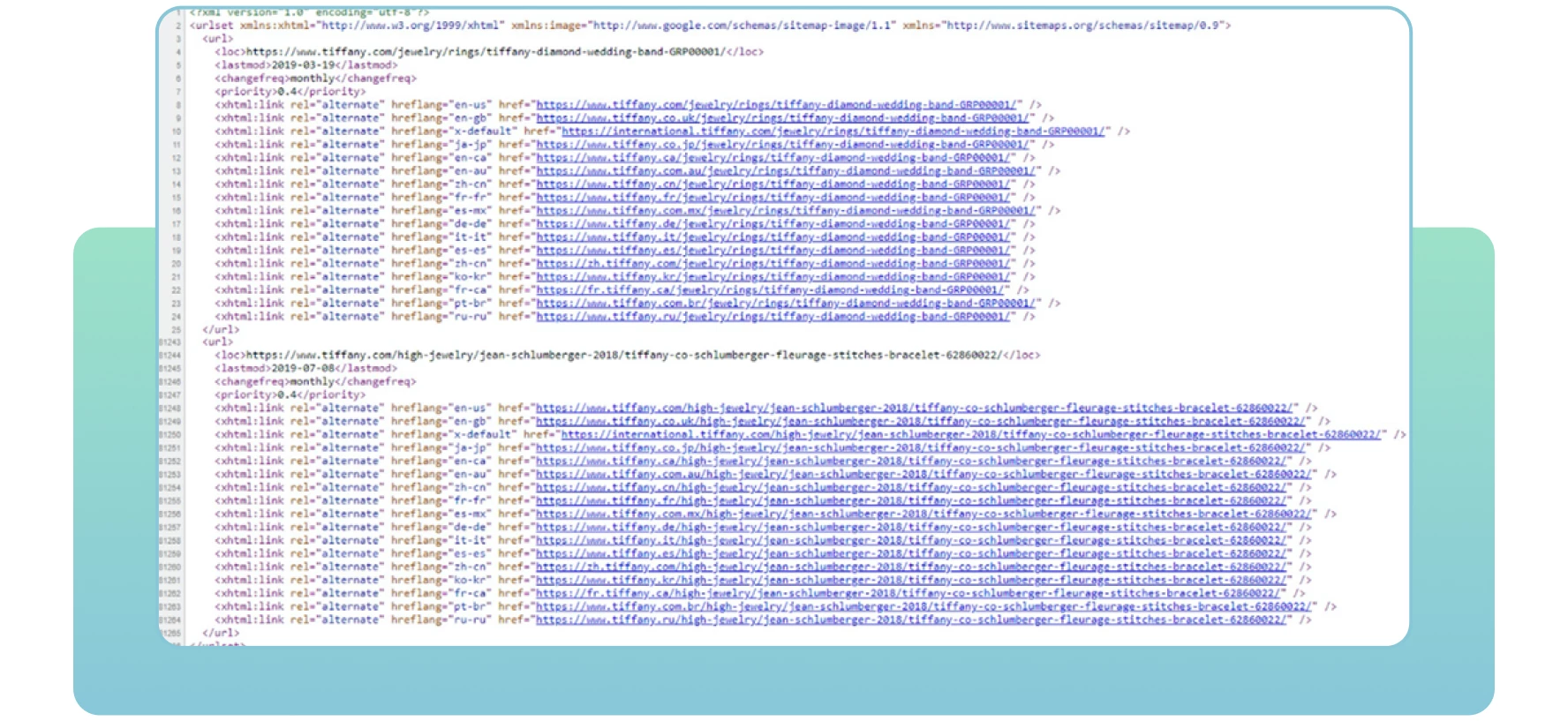
Met sitemaps zullen zoekmachines uw essentiële webpagina’s effectief vinden en crawlen. Als u sommige pagina’s die u wilt indexeren en rangschikken niet opneemt, merken zoekmachines ze misschien niet op, met crawlproblemen en minder verkeer op uw site tot gevolg.
De oplossing
Hier zijn enkele stappen die u kunt overwegen met betrekking tot sitemaps:
Gebruik de XML Sitemaps tool om een sitemap te maken of bij te werken.
Zorg ervoor dat alle noodzakelijke pagina’s zijn opgenomen en dat er geen serverfouten zijn die de toegang voor webcrawlers bemoeilijken.
Dien je sitemap in bij Google. U kunt deze meestal vinden door de URL van uw site te volgen, zoals hieronder weergegeven: domein.nl/sitemap.xml
Gebruik Google Search Console om de status van uw sitemap te controleren en eventuele problemen op te sporen.
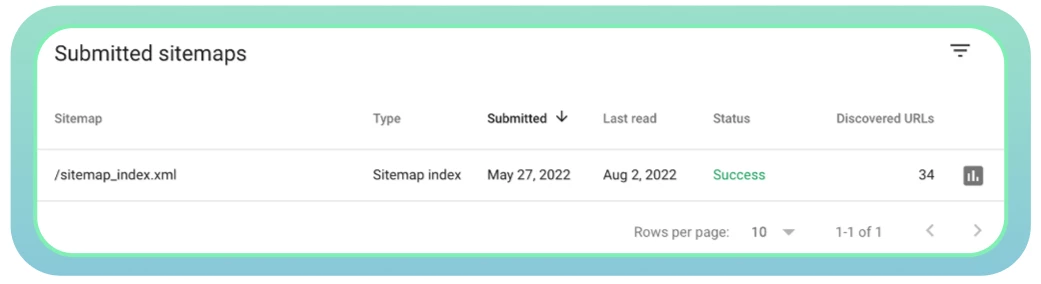
Zorg ervoor dat u uw sitemap bijwerkt zodra nieuwe pagina’s worden toegevoegd of verwijderd van uw website. Zo krijgen zoekmachines nauwkeurige informatie over al uw webpagina’s.
Conclusie
Er zijn veel redenen waarom sommige van uw pagina’s verborgen blijven voor Google en helemaal niet scoren. Ga eerst na of uw site vrij is van crawlproblemen
Veel crawlfouten kunnen de prestaties van uw website beïnvloeden en de bots van zoekmachines vertellen dat bepaalde webpagina’s het crawlen niet waard zijn. Als gevolg daarvan zal Google uw cruciale pagina’s niet indexeren en rangschikken als ze niet toegankelijk zijn.
Daarom is het essentieel om eventuele crawlability-problemen op te sporen en uw best te doen om ze te verhelpen. Door de eerder genoemde oplossingen te implementeren, kunt u uw site optimaliseren voor betere prestaties en ervoor zorgen dat zoekmachines en gebruikers uw site gemakkelijk kunnen vinden.
Beste vrienden! Ik hoop dat het artikel interessant is gebleken en ik zou erg blij zijn als je er iets aan hebt gehad. Tot snel!




